Linear Algebra 3 - Training Neural Network
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Linear Algebra 과목의 수업을 다룬다…만, 과목명은 페이크고 사실은 생성형 모델을 다루는 수업이다.
Basic Rationale
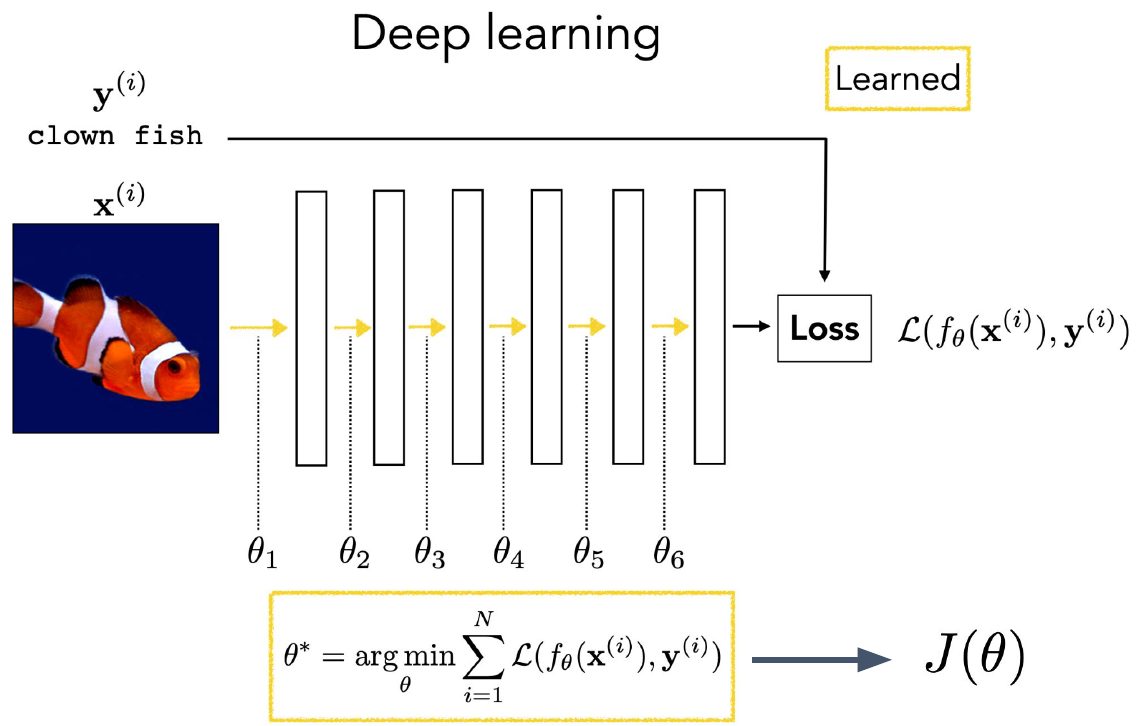
딥러닝의 구조를 사진 하나로 정리하면 위와 같다. 입력 $x^{(i)}$를 주면, 이것을 각각의 Layer에 순차적으로 통과시켜서 최종적으로 출력 $y^{(i)}$를 얻는 구조이다. 이 출력값을 손실함수를 통해 정답과 얼마나 차이가 나는지 계산하여, 이를 최소화시키는 파라미터 $\theta_i$를 찾는 것이 목표이다. 이 과정을 수식 한줄로 요약하면 다음과 같다.
\[\theta^{\ast}=\arg\min_{\theta}\sum_{i=1}^{N}L(f_{\theta}(x^{(i)}),y^{(i)})\]그런데 위의 식은 너무 길기 때문에, $\sum\limits_{i=1}^{N}L(f_{\theta}(x^{(i)}),y^{(i)})$를 $J(\theta)$라고 줄여서 부르자.
\[\theta^{\ast}=\arg\min_{\theta}J(\theta)\]그러면 이를 만족하는 $\theta$를 어떻게 찾을 수 있을까? 크게 다음의 3가지 방법을 생각해볼 수 있다.
가장 생각하기 쉬운 방법은, 랜덤하게 $\theta$를 골라서 값을 비교하는 것이다. 이를 Black box Optimization이라고 하는데, 사실 현대 머신러닝에서는 이 방법을 쓰지 않는다. 그 이유는 당연히 파라미터를 어떻게 이동해야 하는지 아무것도 몰라서, 계산을 줄일 방법이 없기 때문이다.
$J(\theta)$를 한 번 미분해서 Gradient $\nabla_{\theta}J(\theta)$를 얻은 후, 이를 기반으로 최솟값을 찾는 것이다. 이를 First order Optimization이라고 하는데, 대부분의 머신러닝은 이 방법을 사용해서 학습을 진행한다.
Gradient에 더해 Hessian도 구해서 분석한다. Hessian은 모든 변수 조합에 대해서 편미분을 2번씩 해서 얻는 행렬이다. 이렇게 얻어진 $H_{\theta}(J(\theta))$는 정보가 $\theta^2$개가 되는데, 실제로 2020년 정도까지는 이 방식을 사용해서 네트워크를 분석하는 방법이 쓰였다. 이를 Second order Optimization이라고 한다. 그러나 최근의 딥러닝 모델들은 파라미터의 수가 굉장히 많기 때문에 $\theta^2$개의 정보를 다 분석하기 어려워 사장되었다.
결국 사실상 Gradient를 이용하는 방법만이 살아남았다고 볼 수 있다.
Stochastic Gradient Descent
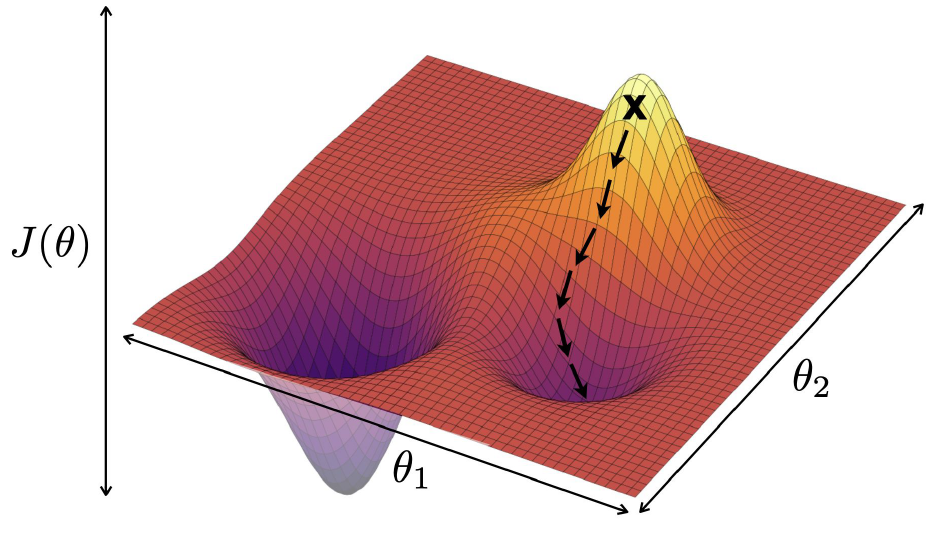
Gradient로 찾는 방법은 굉장히 직관적인데, 어떤 함수의 도함수의 값은 그 지점에서의 기울기를 의미하기 때문이다. Gradient를 구하면 그 변수에 대한 기울기가 나올 것이니, 이들을 모아서 나온 벡터는 곧 함수 값이 증가하는 방향을 가리킬 것이다. 우리는 최솟값을 찾는 것이 목표이므로 이 벡터의 반대 방향으로 가면 된다.
다만, 위의 그래프에서도 알 수 있듯이 Local minimum과 Global minimum은 별개이다. 위의 그래프에서 점 x에서 학습을 시작했다고 가정하면, 이 학습은 화살표방향대로 이동하여 Local minimum에 빠지게 된다. 그리고 Gradient Descent만 가지고는 내가 지금 Local minimum인지 Global minimum인지 구분할 수조차 없으며, 한번 minimum에 진입한 이상 나갈 방법도 존재하지 않는다.
그 때문에 이 학습 방법을 최적화시키려는 노력이 많이 이루어졌는데, 그 중 하나가 Momentum이다. 물리학에서의 관성과 마찬가지로, 이 학습에 “속도”라는 개념을 부여한다. 만일 내가 진입할 minimum이 얕은 곳이라면, 그리고 그동안의 누적된 속도가 충분히 빠르다면 관성에 의해 자력으로 minimum을 벗어날 수 있다는 논리로 제시된 개념이다.
\[\theta^{t+1} \leftarrow \theta^t-\eta\nabla f(\theta^t)-\alpha m^t\]여기서 마지막 항 $\alpha m^t$가 momentum을 의미한다. 위의 식에서 Learning rate $\eta$와 Momentum의 강도 $\alpha$는 사람이 사전에 설정해줘야 하는 Hyper parameter이다. 여담으로 현재는 최적화 기법으로 AdamW를 주로 사용하지만, 여기에도 이 momentum의 아이디어가 반영되어있다.
Loss Function
그러면 손실함수의 형태를 살펴보고 각각 학습 관점에서 어떤지 살펴보자.
Convex
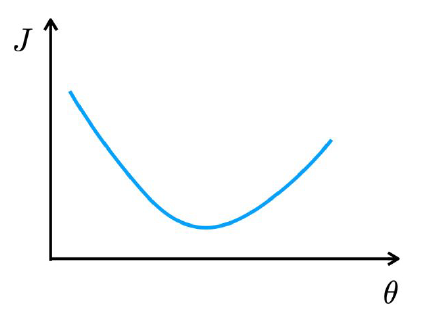
단 하나의 최솟값이 존재하는 Convex function이다. 어디서 시작해도 항상 같은 점으로 수렴하기 때문에 이러한 함수의 형태가 우리가 가장 원하는 그림이 될 것이다. 그러나 아쉽게도 현실에서 손실함수가 이러한 형태를 그리는 것은 거의 있을 수 없는 일이긴 하다.
Local minima
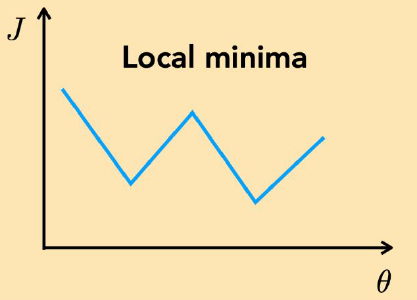
대부분의 손실함수는 이와 비슷한 모양을 지닌다. 물론 일반적으로 파라미터 공간의 차원이 굉장히 크기 때문에 Local minima 또한 그 드넓은 공간에서 수없이 많이 존재하는 형태일 것이다. 위의 그래프라면 내가 오른쪽에서 훈련을 시작했으면 제대로 Global minima에 수렴하겠지만 왼쪽에서 훈련을 시작했으면 Local minima에 빠져서 나오지 못할 것이다.
그렇기 때문에 훈련의 시작점을 잘 정하는 것, 즉 Weights Initialization이 꽤 중요한 케이스이다. 이거에 대한 연구도 존재할 정도인데, 결과적으론 특정 분포에 맞게 선택해주는 것이 가장 성능이 좋다고 밝혀졌다. 물론 이 경우에도 “그럴 확률이 높다”인 것이지 100% 확신할 수는 없으며, Global minima를 찾지 못해도 적당한 Local minima를 학습의 결과로 타협할 수 있다.
Vanishing Gradient
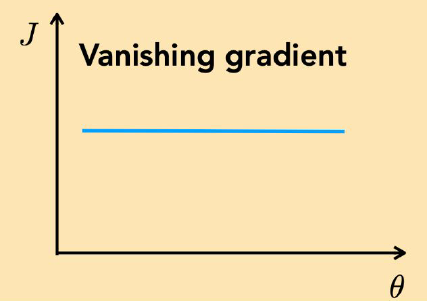
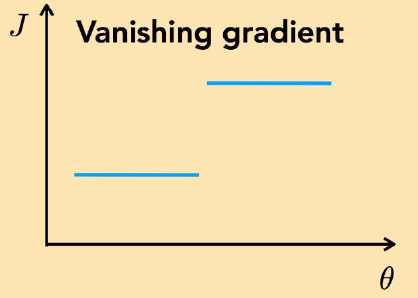
두 케이스 모두 따라갈 Gradient가 딱히 존재하지 않는다. 이러한 경우는 보통 문제 자체가 잘못된 케이스로, 애초에 머신러닝으로 풀 수 없거나 손실함수의 설계가 잘못되었다는 의미이다. 이 케이스에선 어차피 훈련 자체가 불가능하기 때문에 그래프가 연속적인지 아닌지는 그리 중요하진 않으며, 네트워크나 손실함수의 모델링을 점검해봐야 하는 케이스이다.
Exploding Gradient
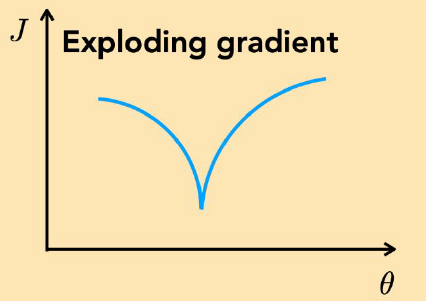
수렴하는 지점은 존재하나 그 근처로 갈수록 Gradient가 $\infty$로 발산하는, 즉 폭발하는 형태이다. 이 경우는 잘 알려진 모델에서는 보기 드물지만, 새로운 모델을 설계하는 경우엔 비교적 흔하게 볼 수 있다. 수렴하는 지점 근처에서의 Gradient가 굉장히 커지기 때문에 순식간에 학습 루프 자체가 폭발해버린다.
Linear discontinuous
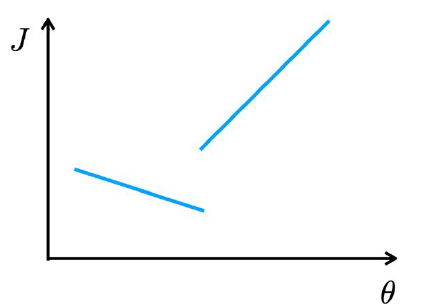
이 케이스도 사실 실제로 발생할만한 형태는 아니다. 그러나 손실함수가 각각의 사이드에서 잘 정의되어 있기 때문에, 의외로 학습에 문제는 없다.
Activation function
지금까지 본 손실함수의 형태를 종합해보면, 손실함수는 모든 곳에서 연속적이고, 미분가능하고, 부드러워야 우리가 훈련을 잘 진행할 수 있다.
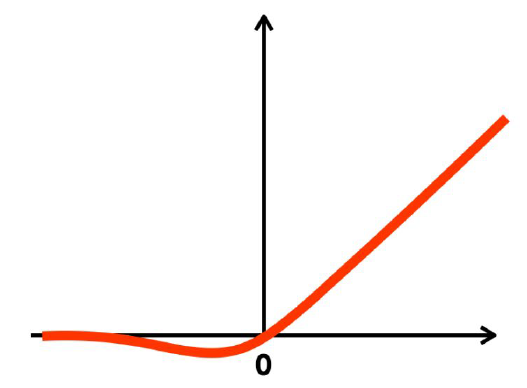
그래서 각각의 Layer들 사이사이에 위와 같은 함수를 끼워넣어서 손실함수가 Continuous, Differentiable, Smooth하게 만들어준다. 이러한 함수를 Activation function이라고 하며, 위의 예시는 그 중 하나인 GeLU이다.
Computational Graph
Computational Graph는 딥러닝 네트워크를 그래프로 표현한 것이다. 각각의 노드가 하나의 레이어를 의미하는데, NN 특성상 루프같은 개념이 없이 Directed Acyclic Graph(DAG)의 형태로만 이루어지게 된다. 이 개념을 Python의 딥러닝 라이브러리에서도 잘 지원해서, 그래프를 그리듯이 네트워크를 구성할 수 있다.
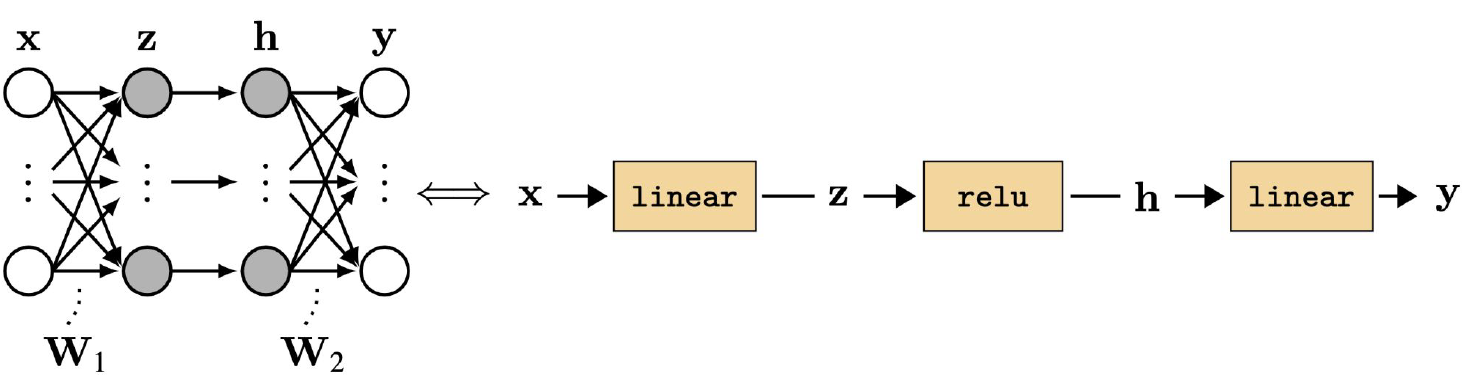
왼쪽의 네트워크를 오른쪽과 같이 간단하고 직관적으로 표현할 수 있다.
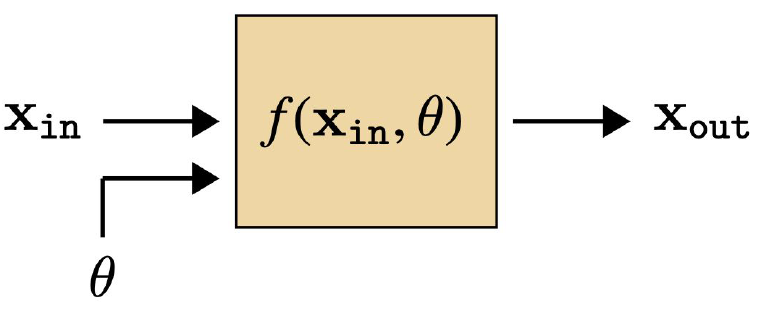
노드 하나만 보면 이런 구조가 된다. 즉, $x_{out}=f(x_{in},\theta)$이다.
Forward/Backward Propagation
그러면 이런 식으로 구성된 네트워크의 Gradient를 어떻게 구할 수 있을까? Gradient도 결국은 미분이므로, 아래의 Chain rule이 성립한다.
\[h(x)=f(g(x)) \Rightarrow h^{\prime}(x)=f^{\prime}(g(x))g^{\prime}(x)\]이것이 “Chain” Rule인 이유는, $z=f(u)$, $u=g(x)$로 두면 아래처럼 정리가 되기 때문이다.
\[\dfrac{\partial z}{\partial x} = \dfrac{\partial z}{\partial u} \cdot \dfrac{\partial u}{\partial x}\]그러면 이걸 어떻게 활용할 수 있을까? 아래의 네트워크를 보자.
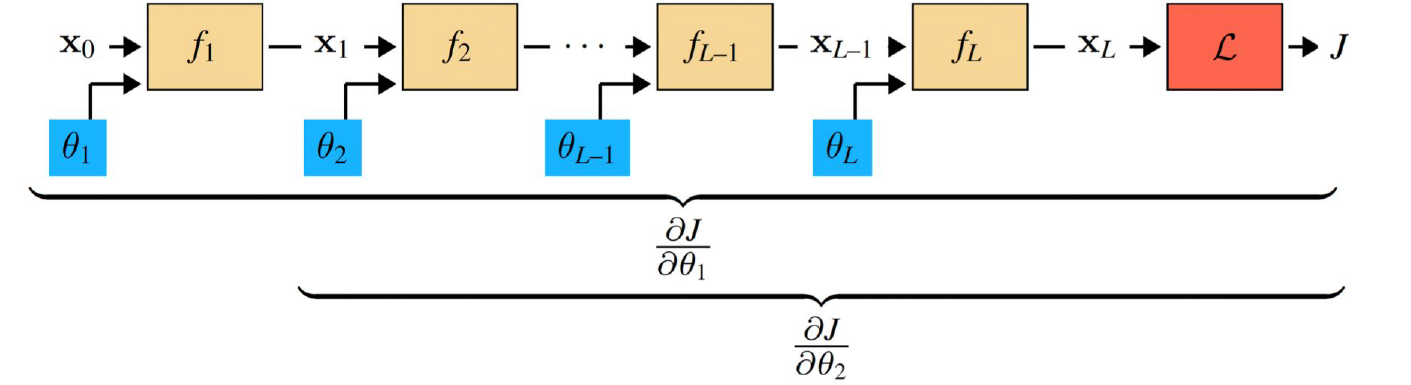
여기서 처음 Layer $f_1$에서는 $\dfrac{\partial J}{\partial \theta_1}$이 필요하고, 그 다음 Layer $f_2$에서는 $\dfrac{\partial J}{\partial \theta_2}$가 필요하다. 그런데 Chain Rule에 의해 다음이 성립한다.
\[\dfrac{\partial J}{\partial \theta_1}=\dfrac{\partial J}{\partial x_L}\dfrac{\partial x_L}{\partial x_{L-1}}\cdots\dfrac{\partial x_3}{\partial x_2}\dfrac{\partial x_2}{\partial x_1}\dfrac{\partial x_1}{\partial \theta_1}\] \[\dfrac{\partial J}{\partial \theta_2}=\dfrac{\partial J}{\partial x_L}\dfrac{\partial x_L}{\partial x_{L-1}}\cdots\dfrac{\partial x_3}{\partial x_2}\dfrac{\partial x_2}{\partial \theta_2}\]잘 보면, 앞부분의 상당수가 이미 중복됨을 알 수 있다. 그리고 저것들은 앞에서부터 Gradient를 구하다보면 자연스럽게 구해질 값들이다. 즉, Dynamic Programming을 적용하여 저 중복되는 부분을 저장했다가 다음 Layer의 Gradient 계산에 넘겨주는 식으로 계산량을 줄일 수 있다. 이를 Back Propagation이라고 한다.
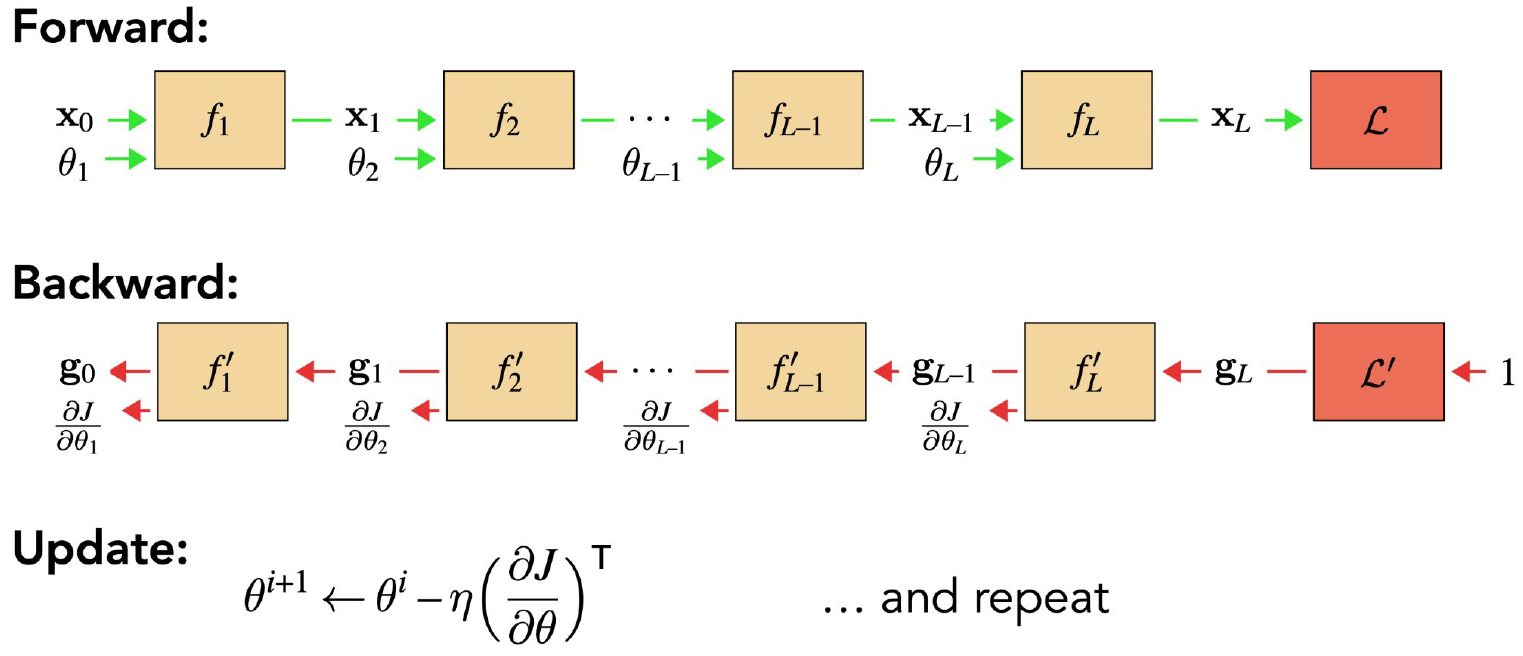
이 모든 과정을 그림 하나로 요약하면 위와 같다.