Advanced Machine Learning 4 - Estimating Probabilities from Data (1)
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Advanced Machine Learning 과목의 수업을 다룬다.
Why Probabilities?
여태까지 이 수업에선 머신러닝은 경험에 의해서 성능이 향상되는 알고리즘으로만 정의했었고, 구체적으로 어떤 식으로 예측하는지에 대해선 다루진 않았었다. 예를 들어 개와 고양이를 분류하는 문제라면 마치 결정론적으로 답을 정해지는 것처럼 다뤘었다. 하지만 실제론 그렇지 않다. 사실상 대부분의 예측값이 “그렇게 될 확률”을 리턴하는 형태이다. 왜 그럴까?
여기엔 몇 가지 이유가 있지만 우선은 직관적으로 생각해보자. 우리는 모든 것을 100% 확신할 수는 없다. 사람이 쓰레기통처럼 위장해있으면 이걸 사람, 혹은 쓰레기통이라고 100% 단정지어서 말할 수 있을까? 이 경우 오판하면 그냥 틀린 예측값이 된다. 조금의 확률이라도 있어야 양쪽 케이스를 모두 고려한다는 것을 알 수 있게 되고, 결정론적으로 대답하는 것보다 훨씬 유익할 것이다.
이는 음성 인식에서도 유효하다. “I like ice cream”과 “I like I scream”이라는 두 문장을 생각해보자. 발음은 두 문장이 동일하며, 둘을 구분하기 위해서는 앞뒤 문맥을 따져봐야 한다. 이렇기 때문에 음성 인식 단계에서는 어느 하나로 확정짓기보다는 각각이 맞을 확률로 접근을 해야 최종적으로 더 적합한 문장이 뭐였는지를 이해할 수 있다.
물론 확률로 예측한다고 다 믿을만한 정보인 것은 아니다. Confidence interval이 40~100%인 것보단 65~75%인 것이 같은 확률이더라도 더 신뢰성이 있을 것이다. 이처럼 최대한 Confidence를 높인 확률을 제공하는 것이 대부분 모델의 목표이다.
MLE & MAP
Preliminaries에서 다뤘던 코인 토스 예시를 다시 들고 와보자. 동전을 10번 던졌을 때의 결과가 $D = \lbrace H, T, T, H, H, H, T, T, T, T \rbrace$라고 할 때, 이 동전의 앞면이 나올 확률 $P(H)$는 몇이 되는 것이 자연스러울까? 물론 당연하게도 동전을 던지는 각각의 시행은 독립적이다.
Maximum Likelihood Estimator
직관적으로 생각해보면 10번 중 4번이 앞면이 나온 상황이니 $P(H) \approx \dfrac{n_H}{n_H+n_T}=\dfrac{4}{10}$이 나와야 할 것이다. 정말 그런지를 수학적으로도 증명해보자.
앞면이 나올 확률을 $\theta$라고 하자. 그러면 주어진 데이터셋을 $P(D;\theta)$라고 표현할 수 있다. 이는 파라미터 $\theta$에 의해 결정된, $D$가 일어날 확률이라는 의미이다. 이를 Likelihood라고 한다. 우리의 목표는 이 Likelihood가 최대가 되도록 만드는 $\theta$를 찾는 것이다.
\[\hat{\theta}=\arg\max_{\theta}P(D;\theta)\]그런데 동전 던지기는 매 시행이 독립적인 이항분포이므로, $P(H)=\theta$라면 $P(T)=1-\theta$가 된다. 따라서,
\[P(D;\theta)=\begin{pmatrix}n_H+n_T \\ n_H\end{pmatrix}\theta^{n_H}(1-\theta)^{n_T}\]로그함수는 단조증가하기 때문에 로그를 취해도 이 값이 최대가 되게 하는 $\theta$는 변하지 않는다.
\[\begin{aligned} \hat{\theta}&=\arg\max_{\theta}\log\begin{pmatrix}n_H+n_T \\ n_H\end{pmatrix}\theta^{n_H}(1-\theta)^{n_T} \\ &=\arg\max_{\theta}\left(\log\begin{pmatrix}n_H+n_T \\ n_H\end{pmatrix}+n_H \cdot \log\theta+n_T \cdot \log(1-\theta)\right) \\ &=\arg\max_{\theta}\left(n_H \cdot \log\theta+n_T \cdot log(1-\theta)\right) \end{aligned}\]결국 우리가 원하는 것은 $\theta$이므로 $\theta$와 관계없는 항은 아예 날려버려도 아무 지장이 없다. 여하튼 이 값을 최대화시키는 $\theta$를 찾아야 하는데, 일반적으로 함수의 최댓값, 최솟값은 도함수의 값이 0이 되는 지점에서 발생한다. 그렇기 때문에 위의 값을 $\theta$에 대해 미분하여 그 값이 0이 되는 지점을 찾아도 동일하다.
\[\dfrac{\partial}{\partial \theta}\log P(D;\theta)=\dfrac{n_H}{\theta}-\dfrac{n_T}{1-\theta}=0\] \[\therefore \hat{\theta}=\dfrac{n_H}{n_H+n_T}\]이는 제일 처음에 직관에 의해 구한 값과 동일하게 된다. 이러한 식으로 Likelihood가 최대가 되도록 파라미터를 계산하는 것을 Maximum Likelihood Estimation, 즉 MLE라고 한다.
Maximum a Posteriori Estimator
여기까지만 보면 Preliminaries에서 봤던 그 상황과 완벽히 동일하다. 이제 이 논의를 좀 더 발전시켜보자. 동일한 상황인데, 데이터의 개수가 매우 적거나 극단적이라면 어떨까? 예를 들어 2번 던져서 $D=\lbrace H, H \rbrace$를 얻었다면, MLE를 통해선 $P(H)=1$이 나올 것이다.
이는 아무리 봐도 정확한 추정으로 보이진 않는다. 동전을 2번 던져서 운좋게 둘 다 앞면이 나온 경우는 얼마든지 일어날 수 있기 때문인데, 이러한 문제를 올바르게 해결하기 위해선 추가적인 가정이 필요하다. 즉, 이미 이 동전을 던졌을 때 앞면이 나올 확률을 어느 정도 알고 있다고 가정하는 것이다. 이 사전지식(Prior)을 각각 $m_H$, $m_T$라고 하면 이 경우 $\theta$는 다음과 같이 변하게 된다.
\[\hat{\theta}=\dfrac{n_H+m_H}{n_H+n_T+m_H+m_T}\]물론 사전 지식을 얼마나 넣어주느냐에 따라서 0.5에 근접하게 될수도 있고, MLE의 결과로 나온 1보다 약간만 떨어지는 결과가 발생할 수도 있다.
이제 위에서의 이 직관을 수학적으로도 서술해보자. 그 전에 Frequentist와 Bayesian이라는, 두 종류의 확률 해석법에 대해 알아야 한다. 이들의 차이는 여러 방면으로 서술할 수 있지만, 여기서는 아까 코인토스 문제에서 다뤘던 Likelihood인 $P(D;\theta)$에 대해서만 이야기를 해보자.
Frequentist는 위에서의 논의 그대로 $P(D;\theta)$라고 생각한다. 즉, $\theta$를 우리가 최적화해야 할 파라미터로 보는 것이다. 이 관점으로 인해 위의 문제가 MLE 문제로 치환된다.
Bayesian은 조금 다르게 접근한다. $P(D\vert\theta)$, 즉 $\theta$ 또한 Random Variable로 보는 것이다. 물론 최적의 $\theta$를 구하는 것은 동일하지만, MLE가 아닌 후술할 MAP라는 다른 방식의 문제로 치환한다.
지금까지 본 풀이법은 Frequentist의 관점이었다. 이제 Bayesian의 관점에서 이 문제를 다시 생각해보자.
우리가 구해야 하는 것은 $D$가 발생했을 때의 $\theta$이다. 또한 $\theta$를 Random Variable로 보고 있기 때문에, 이 확률은 $P(\theta\vert D)$로 표기할 수 있다. (여기서 $P(D\vert\theta)$가 Likelihood가 되고, $P(\theta)$는 Prior, $P(\theta\vert D)$는 Posterior라고 부른다.)
그리고 Bayes Rule에 의해 $P(\theta\vert D)=\dfrac{P(\theta,D)}{P(D)}=\dfrac{P(D\vert\theta)P(\theta)}{P(D)}$가 되므로, 우리가 구하고자 하는 $\theta$는 다음과 같이 적을 수 있다.
\[\hat{\theta}=\arg\max_{\theta}P(\theta|D)=\arg\max_{\theta}P(D|\theta)P(\theta)\]Bayes Rule에서 도출된 공식 중 분모 $P(D)$는 $\theta$와 전혀 무관한 항이기 때문에 아예 삭제해도 무방하다.
이제 여기서, $\theta$가 베타 분포를 따른다고 가정해보자. 왜 하필 베타분포냐면 0~1 범위 내에서 우리가 원하는 가정을 손쉽게 걸어줄 수 있기 때문이다.
\[P(\theta)=\text{Beta }(\alpha,\beta)=\dfrac{\theta^{\alpha-1}(1-\theta)^{\beta-1}}{B(\alpha,\beta)}, \text{ where } B(\alpha,\beta)=\dfrac{\Gamma(\alpha)\Gamma(\beta)}{\Gamma(\alpha+\beta)}\]그러면 $P(\theta)$는 위의 PDF를 따르게 된다. 이제 이 분포를 다시 원래의 식에 대입해보면 다음과 같다.
\[\begin{aligned} P(\theta|D) \propto P(D|\theta)P(\theta) &= \begin{pmatrix} n_H+n_T \\ n_H \end{pmatrix}\dfrac{1}{B(\alpha,\beta)}\theta^{n_H}(1-\theta)^{n_T}\theta^{\alpha-1}(1-\theta)^{\beta-1} \\ &\approx \theta^{n_H+\alpha-1}(1-\theta)^{n_T+\beta-1} \\ &= \dfrac{1}{B(n_H+\alpha,n_T+\beta)}\theta^{n_H+\alpha-1}(1-\theta)^{n_T+\beta-1} \end{aligned}\]결국 이 값을 최대로 만들어야 한다는 것은 동일하므로, MLE에서 그랬던 것처럼 $\theta$와 관계없는 항은 날려버리고 로그를 취한 후 그 도함수가 0이 되는 지점을 찾으면 된다. 사실 단순히 $\theta$ 및 $(1-\theta)$의 지수만 변경된 형태라 굳이 다시 계산할 필요는 없다.
\[\hat{\theta}=\dfrac{n_H+\alpha-1}{n_H+n_T+\alpha+\beta-2}\]이는 $m_H=\alpha-1$, $m_T=\beta-1$로 두면 위의 직관과 동일한 결과이다. 그리고 이러한 방법을 Posterior를 최대화시키는 추정이라는 의미에서 Maximum a Posteriori Estimator, 즉 MAP라고 부른다.
True Bayesian Approach
그런데 위에서 다룬 MAP는 추정치를 구하기 위한 Bayesian의 방법 중 하나일 뿐이다. 보다 구체적으론, MAP를 구할 때 이미 $\arg\max_{\theta}$에서 구했기 때문에, $\hat{\theta}_{MAP}$는 그저 Posterior의 mode, 즉 최빈값만을 쓰고 있다는 것이다.
그렇기 때문에 “진정한” 베이지안의 접근법은 $P(\theta\vert D)$에서 가능한 모든 모델에 대해 다뤄야 한다.
\[P(Y|D,X)=\int_\theta P(Y,\theta|D,X)d\theta = \int_\theta P(Y|\theta,D,X)P(\theta|D)d\theta\]위의 접근법으로 아까의 코인토스 문제를 해결해보면 다음과 같다.
\[\begin{aligned} P(H|D) &= \int_\theta P(H,\theta|D)d\theta \\ &= \int_\theta P(H|\theta,D)P(\theta|D)d\theta \\ &= \int_\theta \theta\cdot P(\theta|D)d\theta \\ &= E[\theta|D] = \dfrac{n_H+\alpha}{n_H+n_T+\alpha+\beta} \end{aligned}\]MLE vs MAP
이제 MLE와 MAP를 비교해보자. MAP는 MLE에 비해 추가적인 변수 $\alpha$, $\beta$가 존재하여 우리가 원하는 대로 Bias를 걸어줄 수 있다. 이 과정을 Smoothing이라고도 부른다. 다만 데이터의 수가 무한히 많다면, 즉 $n \to \infty$라면 \(\hat{\theta}_{MAP} \rightarrow \hat{\theta}_{MLE}\)가 된다.
즉 MAP는 우리가 $\theta$에 대한 사전 지식을 알고 있을 경우, 그리고 데이터의 개수 $n$이 적은 경우에 MLE보다 큰 힘을 발휘하게 된다. 사전 지식이 올바르다는 가정 하에 MLE보다 MAP는 더 빠르게 정답을 찾아갈 것이다. 물론 이 사전 지식이 올바르지 못하다면, MLE에 비해 매우 틀린 결과를 리턴할 것이라는 단점도 존재한다. 물론 데이터의 개수가 많아지면 결국 정답을 찾아가긴 하겠지만, 괜한 리소스 낭비를 야기하게 된다.
그리고 사실 이런 식으로 Prior를 강하게 주는 것은 그리 선호되는 방식은 아니다. 결국 머신러닝은 데이터를 통해 학습을 하는 알고리즘인데, 학습하기 이전에 Prior를 강하게 주게 되면 학습보다도 Prior에 영향을 크게 받게 되어 학습의 본질적인 목적이랑 어긋나게 된다.
Linear Regression
Linear Regression, 즉 선형 회귀는 실질적으로 사용하는 모델 중 가장 간단한 모델이다. 이 모델에 적용되는 Assumption은 Linear Regression이라는 이름 그대로 $y$가 $x$에 대한 선형결합으로 이루어질 것이다는 것이다. 이를 수식으로 나타내면 다음과 같다.
\[y=w^T x + \epsilon, \text{ where } \epsilon \sim \mathcal{N}(0, \sigma^2)\]여기서 추가적인 상수 $\epsilon$은 Random Noise이며, 일반적으로 Gaussian 분포를 따르기 때문에 위의 가정에서도 노이즈가 가우시안 분포를 따른다고 가정했다. 그리고 이 모델의 Assumption에서 이미 $x$와 $y$의 함수가 나왔기 때문에 모델의 형태 역시 위와 동일하다.
그런데 노이즈가 가우시안 분포를 따른다는 것은 어떤 의미를 지닐까? 아래 그래프를 보자.
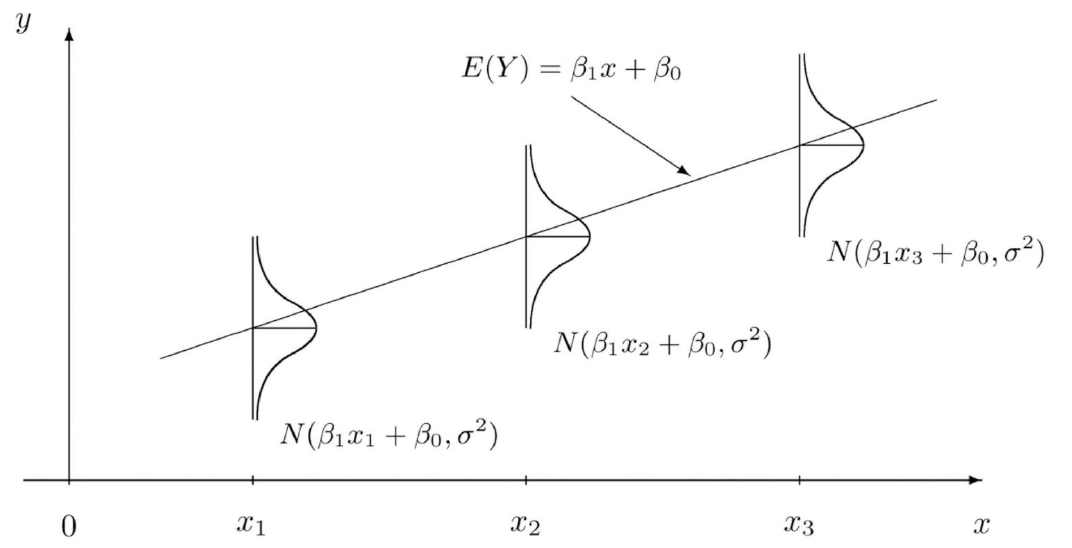
그래프에서 표현하는 그대로, 각각의 데이터의 입력값 $x_i$에서 수직 방향의 가우시안 분포를 그리고, 그 분포 이내에서 노이즈가 정해져서 그걸 더한 값이 최종적으로 $y_i$가 되는 것이다.
그렇기 때문에 $y_i$는 결국 평균이 $w^T x_i$, 분산이 $\sigma^2$이 되는 가우시안 분포를 따르게 된다. 이를 수식으로 표현하면 다음과 같다.
\[y_i|x_i \sim \mathcal{N}(w^T x_i,\sigma^2) \Rightarrow P(y_i|x_i, w)=\dfrac{1}{\sqrt{2\pi\sigma^2}}e^{-\dfrac{(w^T x_i-y_i)^2}{2\sigma^2}}\]그러면 MLE의 관점에서 $\hat{w}$을 어떻게 구할지 생각해보자.
\[\begin{aligned} \hat{w} &= \arg\max_{w}P(D;w) \\ &= \arg\max_{w}\prod_{i=1}^{n}P(y_i|x_i;w) = \arg\max_{w}\sum_{i=1}^{n}\log P(y_i|x_i;w) \\ &= \arg\max_{w}\sum_{i=1}^{n}\log\left(\dfrac{1}{\sqrt{2\pi\sigma^2}}e^{-\dfrac{(w^T x_i-y_i)^2}{2\sigma^2}}\right) \\ &= \arg\max_{w}\sum_{i=1}^{n}\left(\log\left(\dfrac{1}{\sqrt{2\pi\sigma^2}}\right)-\dfrac{(w^T x_i-y_i)^2}{2\sigma^2}\right) \\ &= \arg\min_{w}\dfrac{1}{2\sigma^2}\sum_{i=1}^{n}(w^T x_i-y_i)^2 \\ &= \arg\min_{w}\dfrac{1}{n}\sum_{i=1}^{n}(w^T x_i-y_i)^2 \end{aligned}\]복잡해보이지만 결국 하는 일은 (1)각 샘플들에 대해 독립이므로 곱으로 분리 (2)로그를 취해 합으로 변환 및 관련없는 항 제거일 뿐이다. 마지막에 $\dfrac{1}{n}$을 추가한 것은 편의상 데이터 샘플의 개수와 무관하게 손실함수의 스케일을 유지하기 위함이다.
결국 손실함수 $l$은 $l(w)=\dfrac{1}{n}\sum\limits_{i=1}^{n}(w^T x_i-y_i)^2$의 형태가 된다. 그리고 이러한 형태의 손실함수를 우리는 이미 MSE(Mean Squared Error), 혹은 OLS(Ordinary Least Squares)라고 부른다는 것을 이미 알고 있다.
즉, 이전 글에서 대충 넘어갔던 MSE는 사실 노이즈가 가우시안 분포에서 왔다는 가정 하에 가능했던 것이다. 그렇다면 해당 글에서 다룬 다른 손실함수인 MAE는 어떨까? MAE는 노이즈가 Laplace 분포라는 가정 하에 성립되는 이야기이다.
\[f(x|\mu,b)=\dfrac{1}{2b}e^{-\dfrac{|x-\mu|}{b}}\]Laplace 분포의 PDF는 위와 같이 정의된다. 가우시안 분포와 형태가 비슷한데, 지수 안에 제곱 대신 절댓값이 들어간다는 점만 다르다. 역시 같은 과정을 거쳐 계산하면 저 절댓값이 끝까지 살아남아 MAE의 형태로 손실함수가 구해지게 된다. 물론 노이즈가 다른 형태의 분포를 따른다면 손실함수도 그에 맞게 다른 형태가 될 것이다.
또 이전 글에서 MSE는 차이를 제곱하기 때문에 MAE에 비해 틀리는게 치명적으로 작용하는 문제에서 쓰기 좋다고 적었는데, Gaussian 분포와 Laplace 분포의 형태를 생각해보면 결국 같은 얘기를 하고 있음을 알 수 있다. 가우시안 분포는 종 모양으로 되어 있어 평균에서 멀어질수록 Laplace 분포에 비해 확률이 급격하게 낮아진다.
그러면 다시 MSE로 돌아와서, 이렇게 손실함수의 형태까지 구했는데, 저걸 최소화시킬 $w$는 어떻게 구할 수 있을까? 놀랍게도 MSE의 경우 최적화된 답을 일반화된 형태의 수식으로 유도가 가능하다.
우선 손실함수를 아래와 같이 벡터로 표현할 수 있다.
\[l(w)=\dfrac{1}{n}\sum_{i=1}^{n}(x_i^T w - y_i)^2=\dfrac{1}{n}\lVert Xw-y \rVert _2^2=\dfrac{1}{n}(Xw-y)^T (Xw-y)\]$\dfrac{\partial l(w)}{\partial w}=0$일 때 위의 값이 최소화된다.
\[\dfrac{\partial l(w)}{\partial w}=\dfrac{\partial}{\partial w}(w^T X^T Xw - w^T X^T y - y^T Xw + y^T y) = 2X^T Xw - 2X^T y = 0\] \[\therefore w^{\ast}=(X^T X)^{-1}X^T y, \text{ where } X=\left[ x_1,\ldots,x_n \right]^T \text{ and } y=\left[ y_1,\ldots,y_n \right]^T\]이렇게 깔끔하게 나오기는 하는데, 안타깝게도 위의 공식은 실전에서 사용하기 굉장히 난해하다. 원인은 역시 역행렬 때문인데, 우선 역행렬이라는 것이 굉장히 민감한 연산이라 데이터셋의 각 차원이 선형독립이 아닌 경우가 발생한다면 역행렬이 존재하지 않게 된다는 리스크가 있다. 이는 Pseudo-inverse 등으로 어떻게든 극복한다고 쳐도, 간단해보이는 $w^{\ast}$의 형태와는 다르게 역행렬은 상당히 무거운 연산이라는 문제점도 있다. 무려 $O(d^3)$ 연산이라 그리 효율적이지 않다.
그렇기 때문에 위와 같은 깔끔한 Closed-form solution이 있음에도 불구하고 정작 딥러닝에서 쓰이는 Gradient descent를 주로 사용하게 된다.