Linear Algebra 4 - Convolutional Neural Network
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Linear Algebra 과목의 수업을 다룬다…만, 과목명은 페이크고 사실은 생성형 모델을 다루는 수업이다.
Back Propagation - Recap.
먼저, Back Propagation은 중요한 개념이니 다시 한번 복습하고 넘어가자.
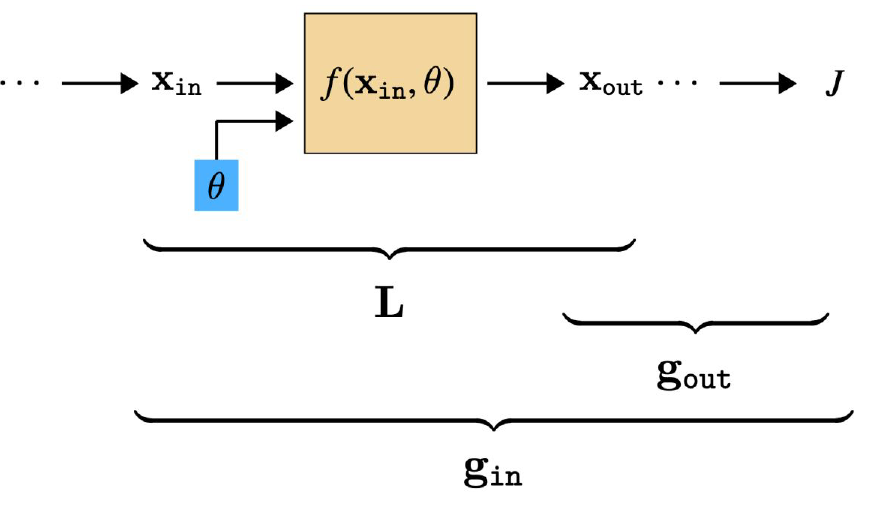
위의 그림고 같은 식으로 레이어가 구성되어 있다고 가정하자. 여기서 $L$, $g$는 다음과 같이 정의된다.
\[L \triangleq \dfrac{\partial x_{out}}{\partial [x_{in}, \theta]}, g \triangleq \dfrac{\partial J}{\partial x}\]즉 $L$은 Layer의 input에 대한 output의 Gradient고, $g$는 Activation에 대한 $J$의 Gradient이다.
우리의 목표는 $\theta$를 구하는 것이고, 이를 위해선 $\dfrac{\partial J}{\partial \theta}$를 구해야 한다. 그리고 이는 다음과 같이 표현할 수 있다.
\[\dfrac{\partial J}{\partial \theta}=\dfrac{\partial J}{\partial x_{out}} \dfrac{\partial x_{out}}{\partial \theta} = g_{out}L^{\theta}\]그런데 잘 생각해보면, $L$이란 것은 이미 우리의 정의에서 $L=f^{\prime}(x_{in}, \theta)$이고, $g$는 위의 식을 바로 앞 레이어에 적용하면 $g_{in}=g_{out}L^x$가 된다.
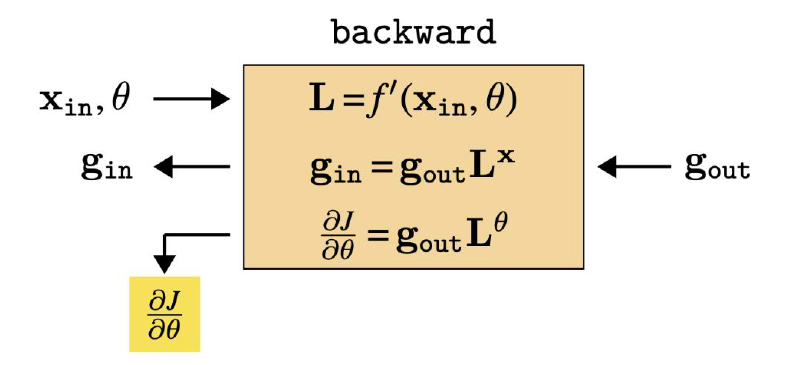
그렇기 때문에 바로 앞 레이어에서 계산하고 나온 $g_{out}$을 가지고, 현재 레이어에서 필요한 모든 Gradient를 계산함과 동시에 바로 전 레이어에서 필요한 $g_{in}$을 도출할 수 있다. 이러한 식으로 마지막 레이어에서부터 거꾸로 거슬러 올라가면서 모든 파라미터를 업데이트 할 수 있으며, 이것을 Back Propagation이라고 한다.
Generalization vs Architectures
이제 다른 이야기를 해보자. 우리가 지금까지 배운 레이어는 Linear Layer뿐이다. 그리고 이는 모든 파라미터의 선형 결합으로 이루어져 있는, Fully-connected Layer이다. 얼핏 생각하면 모든 연결을 다 표현할 수 있으니 Fully-connected Layer만 써도 되지 않을까 하는 의구심이 든다.
이 의구심을 해결하기 위해, 다음의 예시를 확인해보자.
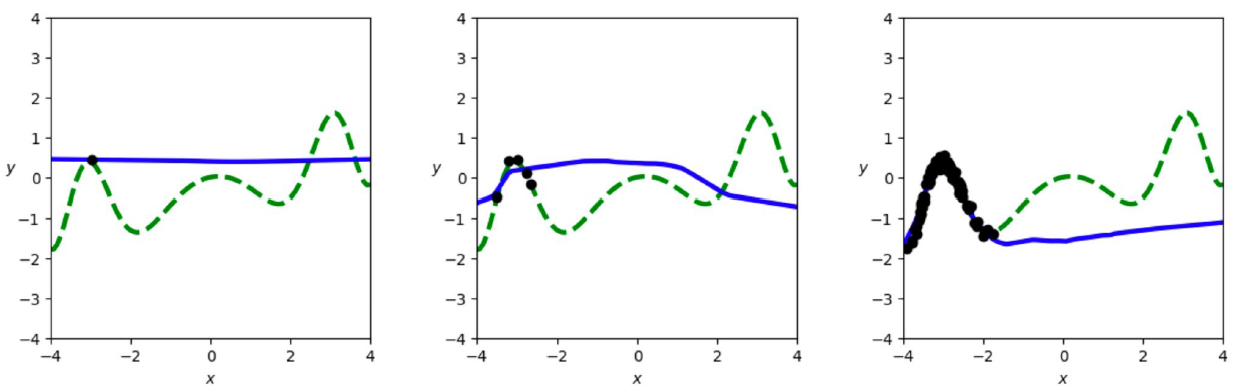
위의 그래프에서 녹색 점선이 Ground Truth, 그리고 검은색 점이 우리가 가진 Sample Data이다. 훈련 결과는 파란색 실선으로 표시되었다. 일반적인 Linear Layer 5개로 NN을 구성했다. Activation function도 무난하게 ReLU를 택했다. 이 경우 갖고 있는 Data Set의 범위 내에서는 굉장히 잘 추론하는 모습을 보인다. 하지만 그 외의 영역은 추론 결과가 엉망이다. Data Set의 범위가 너무 억까같다고 생각할 수 있지만, 우리가 실제로 어느 범위의 데이터를 갖고 있는지는 우리도 모르니 실제로 일어날 수도 있는 상황이다.
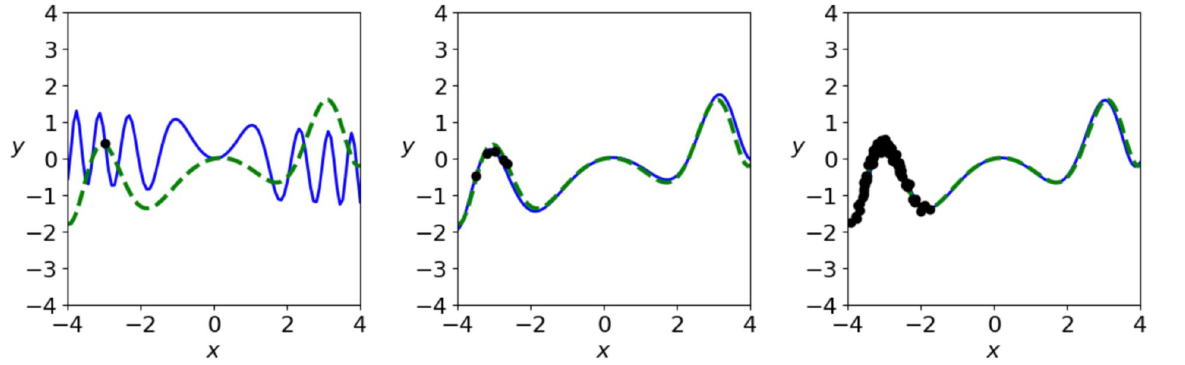
이번에는 같은 상황인데 다만 우리가 데이터의 특성을 완벽하게 알고 있다고 가정하자. 우리는 모델이 $y=ax+\sin (bx^2)$ 형태로 구성되어야 한다는 Prior를 이미 알고 있어서, 그 가정을 바탕으로 학습을 진행했다. 여담으로, 이러한 사전 지식을 Inductive Bias라고 부른다.
이 경우 우리가 갖고 있지 않은 Data의 범위도 정확하게 추론하는 모습을 볼 수 있다. 심지어 이 모델은 딥러닝도 아니다. Layer를 1개만 사용한 매우 단순한 모델인데도 5개의 Layer를 사용한 MLP보다도 높은 성능을 보인다. 즉, 데이터의 특성을 이해하고 그에 적합한 모델을 설계하는 것이 단순히 NN의 복잡도를 올리는 것보다 좋은 모습을 보인다.
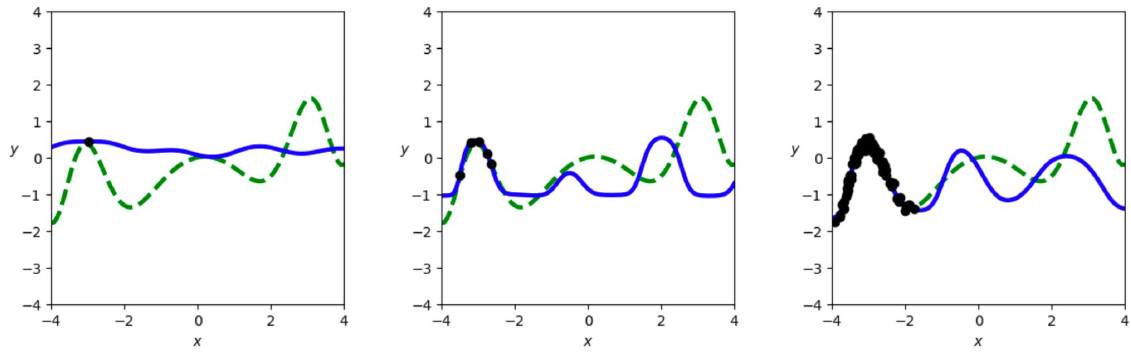
그런데 사실 두번째 예시는 현실성이 없다. 저렇게까지 정확하게 Prior를 줄 수 있는 일이 현실에선 사실상 불가능하기 때문이다. 그렇기 때문에 저 정도로 정확한 Prior를 주는 것을 이상향으로 두되, 우리의 실질적인 목표는 이번 예시일 것이다. 이 경우엔 첫번째 예시와 동일하게 Linear Layer 5개를 사용했으나, Activation function을 sin-net(SIREN)으로 사용했다. sin-net은 이름 그대로 $\sin$과 $\cos$를 결합하여 구성한 Activation function을 사용하는 MLP이다.
정확한 형태는 모르지만 아무튼 $\sin$ 기반으로 표현된다는 Inductive Bias를 알고 있으면, 첫 번째 예시에 비해서는 장족의 발전을 이룰 수 있다. 그리고 이 정도는 데이터의 특성에서 얻을 수 있다.
여기서 배울 수 있는 것은, 단순히 모든 파라미터를 다 연결시키는 Fully-connected Layer가 모든 상황에서 만능은 아니라는 것이다. 데이터를 충분히 많이 확보할 수 있다면 Fully-connected Layer가 당연히 우위를 가지겠지만, 데이터가 한정되어 있으면 Generalization, 즉 “아무 데이터에 대한 일관적인 추론 능력”을 보장하기 어렵게 된다. 모델의 Capacity가 크다면 Expressivity가 좋긴 하지만, 그것이 무조건 정답이 될 수는 없다는 이야기이다.
오히려 적절한 Inductive Bias를 걸어 주면 Fully-connected Layer보다 훨씬 적은 수의 데이터로도 더 높은 예측 성능을 보장할 수 있게 된다. 그리고 이를 위해서는 데이터의 특성을 파악하는 것이 무엇보다 중요하다.
Convolutional Layer
위의 고찰에서 Locally-connected Layer라는 개념이 등장했다. 즉, 데이터의 특성에 따라 모든 unit이 다음 Layer의 모든 unit에 연결될 필요가 없을 수 있다는 것이고, 그 경우엔 어차피 데이터의 개수는 동일하므로 “관계 없는 connection”을 지우는게 오히려 성능이 더 좋다는 것이다.
Convolutional Layer, 즉 Conv Layer는 이러한 시도에서 나온 Locally-connected Layer 중 하나이다. Convolution Layer는 주로 이미지 등의 멀티미디어에 사용되는데, 왜냐하면 모든 픽셀 간의 관계가 항상 중요한 것은 아니기 때문이다.
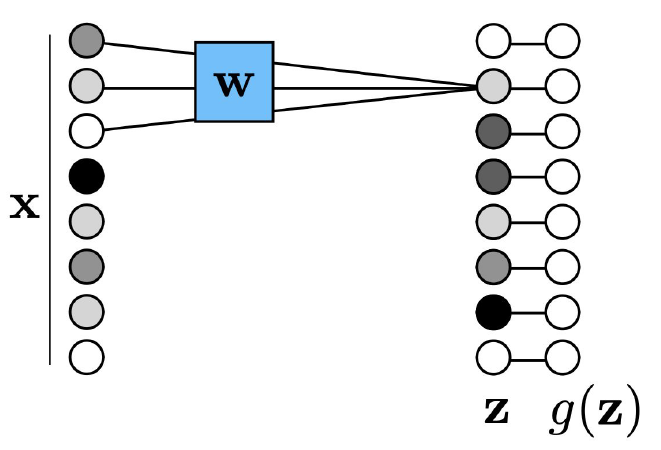
즉, $z=w \ast x + b$가 되는데, 여기서 $\ast$ 연산은 합성곱(Convolution)이라고 부르며 Linear, shift-invariant transformation을 수행한다. 이걸 자세하게 표현하면 다음과 같다.
\[x_{out}[n,m]=b+\sum_{k_1,k_2=-K}^{K}w[k_1,k_2]x_{in}[n+k_1,m+k_2]\]여기서 $w$는 필터의 역할을 하게 되며, 동일한 필터가 계속 Sliding을 하면서 데이터 전체를 스캔하는 역할을 한다. 이러한 개념을 Weight Sharing이라고 부른다. 그리고 우리의 학습 대상이 바로 이 필터가 된다.
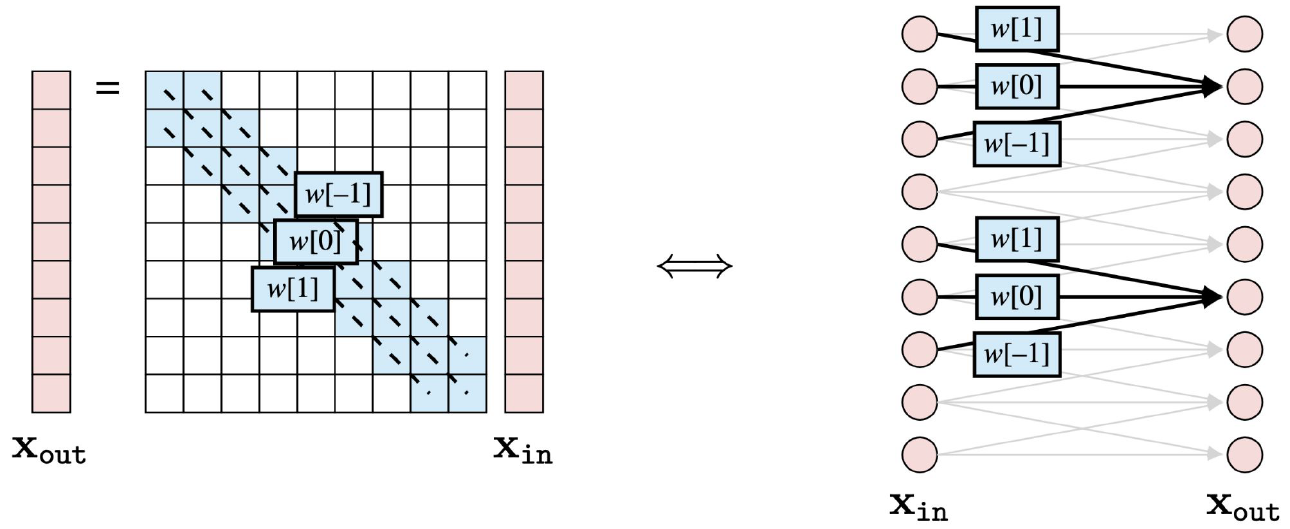
이러한 식으로 필터가 데이터 전체를 스캔하면, 아래와 같은 출력이 나오게 된다.
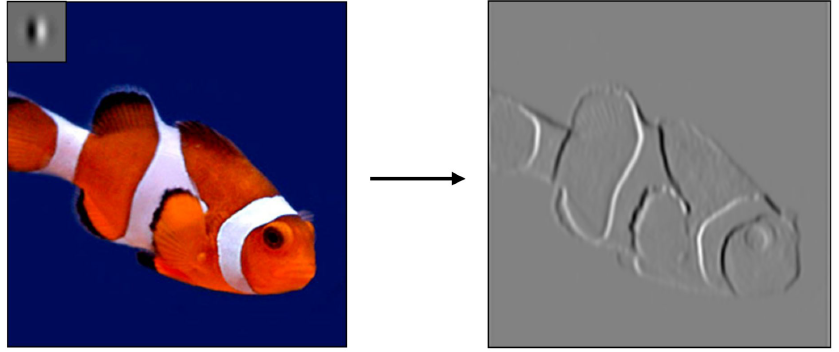
물고기 그림의 좌상단에 있는 영역이 우리가 설정한 필터가 되고, 이미지 전체에 이 필터를 한번씩 통과시켜서 우측의 그림을 얻었다. 이 그림은 원래 그림과 비교하면 많은 정보가 소실되었는데, 그러한 정보를 다 쳐내고 그림의 구조만을 남긴 형태이다.
이러한 식으로 정보를 가공 및 압축하는 것이 Convolutional Layer의 역할이다. 이는 Convolutional Layer부터가 특정 데이터(멀티미디어)를 타겟으로 했고, 그 데이터의 특성(모든 구성 요소가 서로 연결될 필요가 없다)를 잘 반영한 좋은 예시라고 할 수 있겠다.
그런데 사실 이미지는 각 픽셀마다 RGB 값이 있기 때문에, 한 픽셀당 3개의 차원을 갖고 있다. 그렇기 때문에 실제로는 아래와 같은 Multichannel Convolutional Layer를 사용하게 된다.
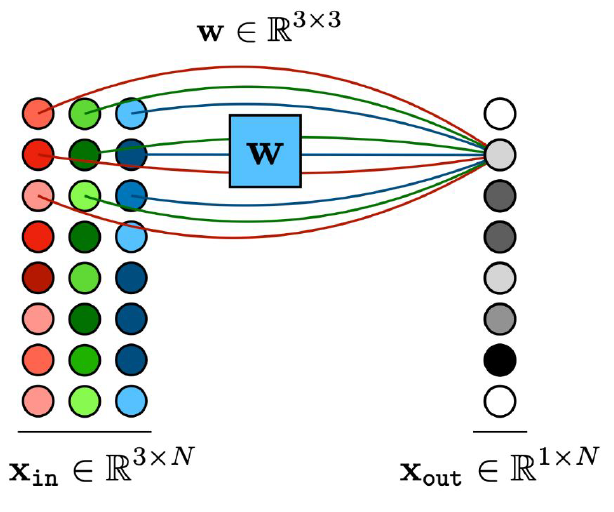
이 경우 $x_{out}=\sum\limits_{c}w[c,:]\ast x_{in}[c,:]+b[c]$가 된다. 수식에서 보다시피, Single channel일 때와 별 차이는 없긴 하다.
Pooling
Pooling은 앞서 살펴본 Convolution Layer의 output에 특정한 연산을 취해서 구조를 압축시키기 위해 쓰이는 Layer이다. 크게 Max Pooling과 Mean Pooling이 있는데, 둘 다 파라미터가 존재하지 않아 학습이 되는 Layer는 아니다.
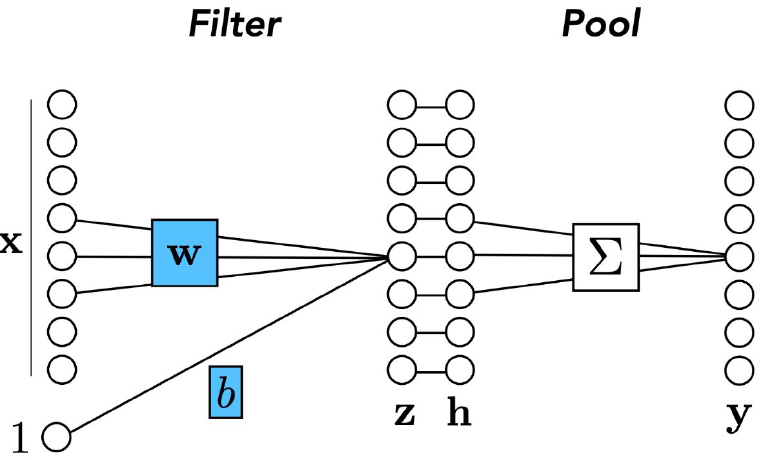
Max Pooling은 주변 이웃들 중 최댓값만을 취하는 연산($y_j=\max_{k\in N(j)}h_k$)이고, Mean Pooling은 주변 이웃들의 평균값을 취하는 연산($y_j=\dfrac{1}{\vert N \vert}\sum\limits_{k\in N(j)}h_k$)이다.
그럼 이 Pooling Layer는 왜 필요한걸까? 가장 큰 목적은 정보를 압축하는 것이다. Inductive Bias를 걸어 Convolution Layer를 설계했음에도 불구하고, 그것조차도 Hypothesis space가 너무 크기 때문에 여기서 더 압축(즉, Downsampling)을 하기 위함이다. 결국 이미지를 텐서로 변환하면 $3 \ast W\ast H$이라는 굉장히 큰 차원이 나오는데, 우리가 원하는 출력 차원은 대체로 상당히 작기 때문이라고 할 수 있다.
그래서 실제로 CNN을 사용할 때는 Filter(Convolution Layer) - ReLU - Downsample(Pooling)의 과정을 한 세트로 엮어서 사용하는 일이 많다. 이 세트를 묶어서 Convolution Block이라고도 부른다. 그럼 이러한 Convolution Block이 사용되는 실제 구조를 몇 가지 살펴보자.
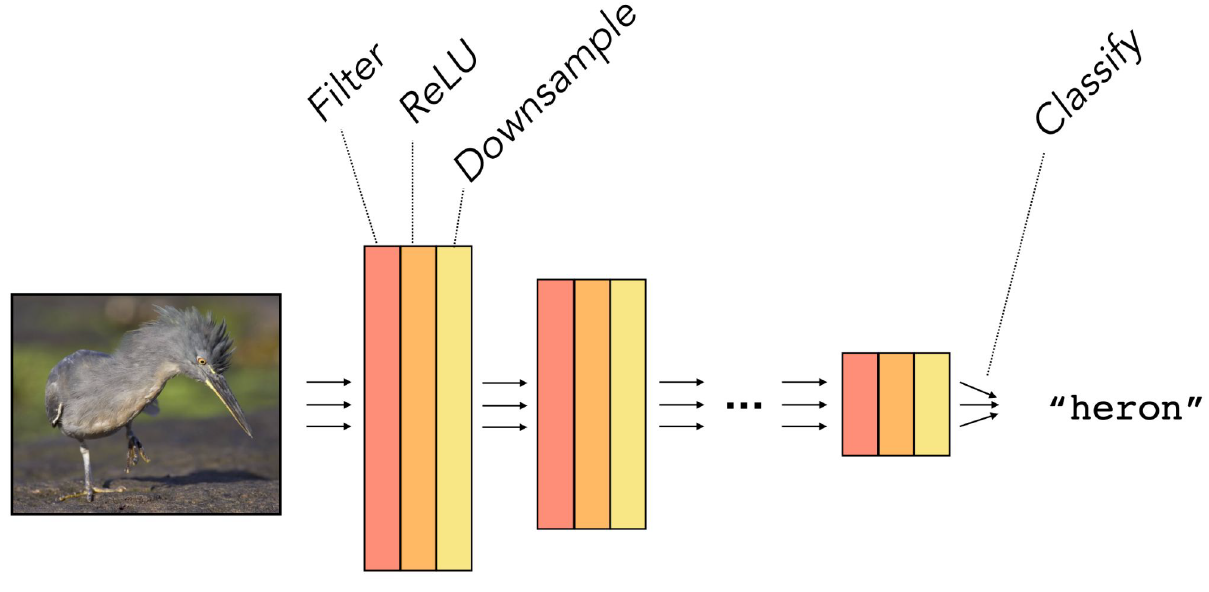
이미지의 Classification 문제를 풀 때는 위와 같이 Convolution Block을 여러 번 반복하여 1D까지 내리게 된다.
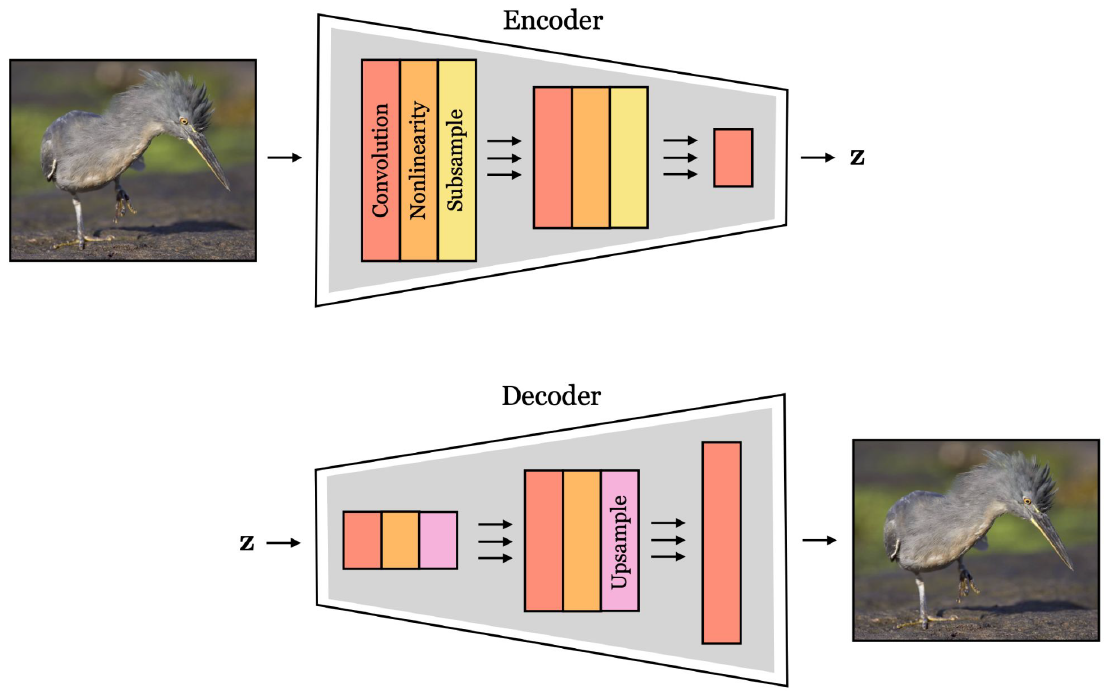
만일 이미지를 생성하고 싶다면, 먼저 Encoder를 통해 우리가 원하는 답 $z$를 찾을 때까지 줄인 후, 거기서부터 Decoder를 통해 다시 늘리는 방식을 취한다.
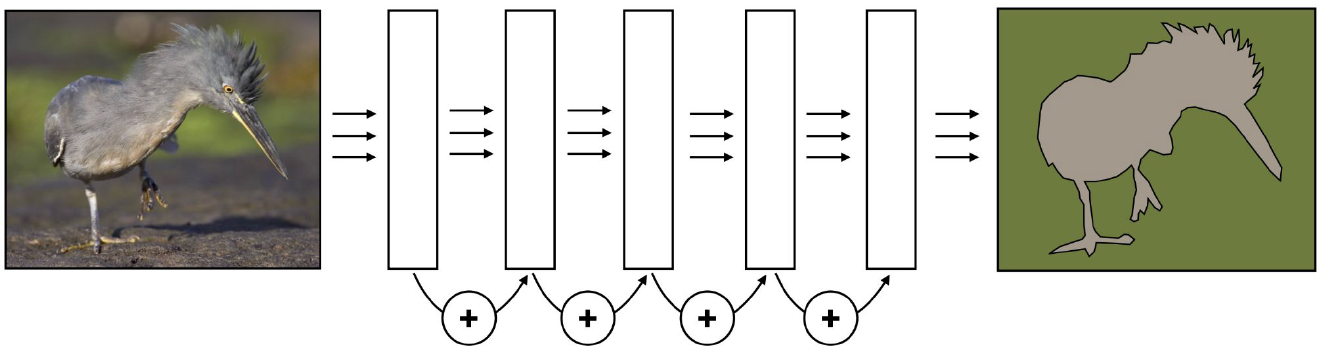
딥러닝 연구 초기에 굉장히 유행했던 ResNet이라는 녀석이다. 여기서는 $x_{out}=F(x_{in})+x_{in}$이라는 형태의 Residual connection을 사용했는데, 이는 역전파 시에 $\dfrac{\partial x_{out}}{\partial x_{in}}=\dfrac{\partial J}{\partial x_{in}}+1$이 되어 깊은 Layer에서도 Gradient가 최소 1 이상이 유지됨을 보장하기 위함이다.

위의 ResNet과 거의 동시기에 등장한 U-Net이다. 여기서는 각각의 Decoder가 같은 단계의 Encoder 출력값을 바로 가져와서 Upsampling에 사용한다. 이러한 형태를 Skip connection이라고 부르며, 이 구조가 Diffusion 계열의 현대 생성 모델의 베이스가 되고 있다.