Linear Algebra 5 - Generative Model & VAE
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Linear Algebra 과목의 수업을 다룬다…만, 과목명은 페이크고 사실은 생성형 모델을 다루는 수업이다.
General Concept
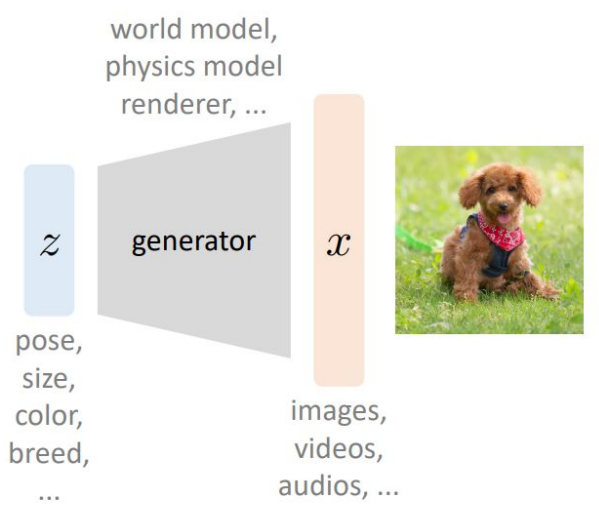
“Generative Model”이란 뭘까? 가장 대표적인 이미지 생성 모델을 생각해보자.
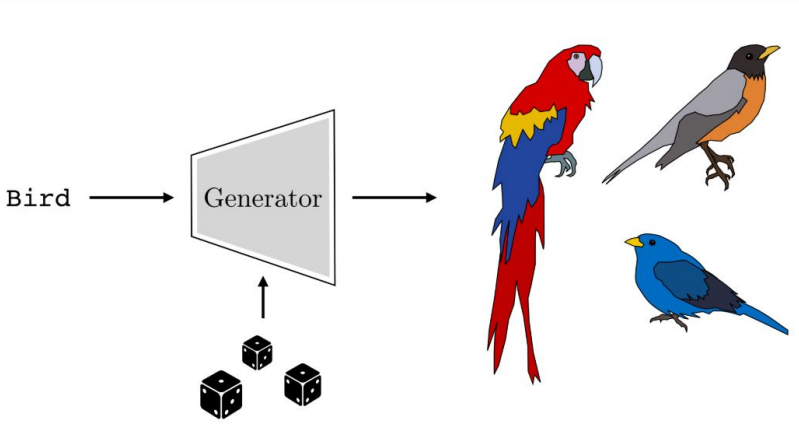
만일 새의 이미지를 출력해달라는 요청을 받았다고 가정해보자. 그런데 이 정보만으로는 명확한 이미지가 나오지 않는다. “새”라는 정보 외에도, 크기, 색상, 각도 등등 주어지지 않은 수많은 값들을 다 정해야 비로소 이미지가 하나로 구체화되기 때문이다. 이러한 정보, 즉 각각의 Component를 이 모델이 알고 있는 분포에서 랜덤하게 가져와서 각각의 특징들을 부여해줘야 비로소 이미지를 그릴 수 있다.
물론 매 실행시마다 Component에서 정해지는 값들은 달라질 것이다. 그렇기 때문에 매 실행시마다 “새”라는 형태만 유지한 채 다른 모든 것들이 새롭게 정해지며 아예 다른 이미지가 나오게 된다.
그렇기 때문에 Generative Model이 우리가 원하는 이미지를 잘 그려내려면, 출력값으로 나오는 이미지 자체에 주목하기보다는 각각의 Component에 대한 정보를 잘 정리하는 것이 더 중요하다는 이야기가 된다.
이를 수학적으로 얘기하면 데이터의 분포 그 자체를 학습한다고 볼 수 있다. 일반적인 모델과 마찬가지로, 생성모델 역시 training data만 제대로 흉내내는 것이 목적이 아니기 때문이다. 한 번도 본 적 없는 데이터를 생성할 줄 알아야 하기 때문에, training data로부터 만들어야 할 이미지들의 분포를 학습해야 한다.
이러한 Generative Model은 접근 방법에 따라 크게 Direct Model과 Indirect Model의 두 종류로 나뉜다.
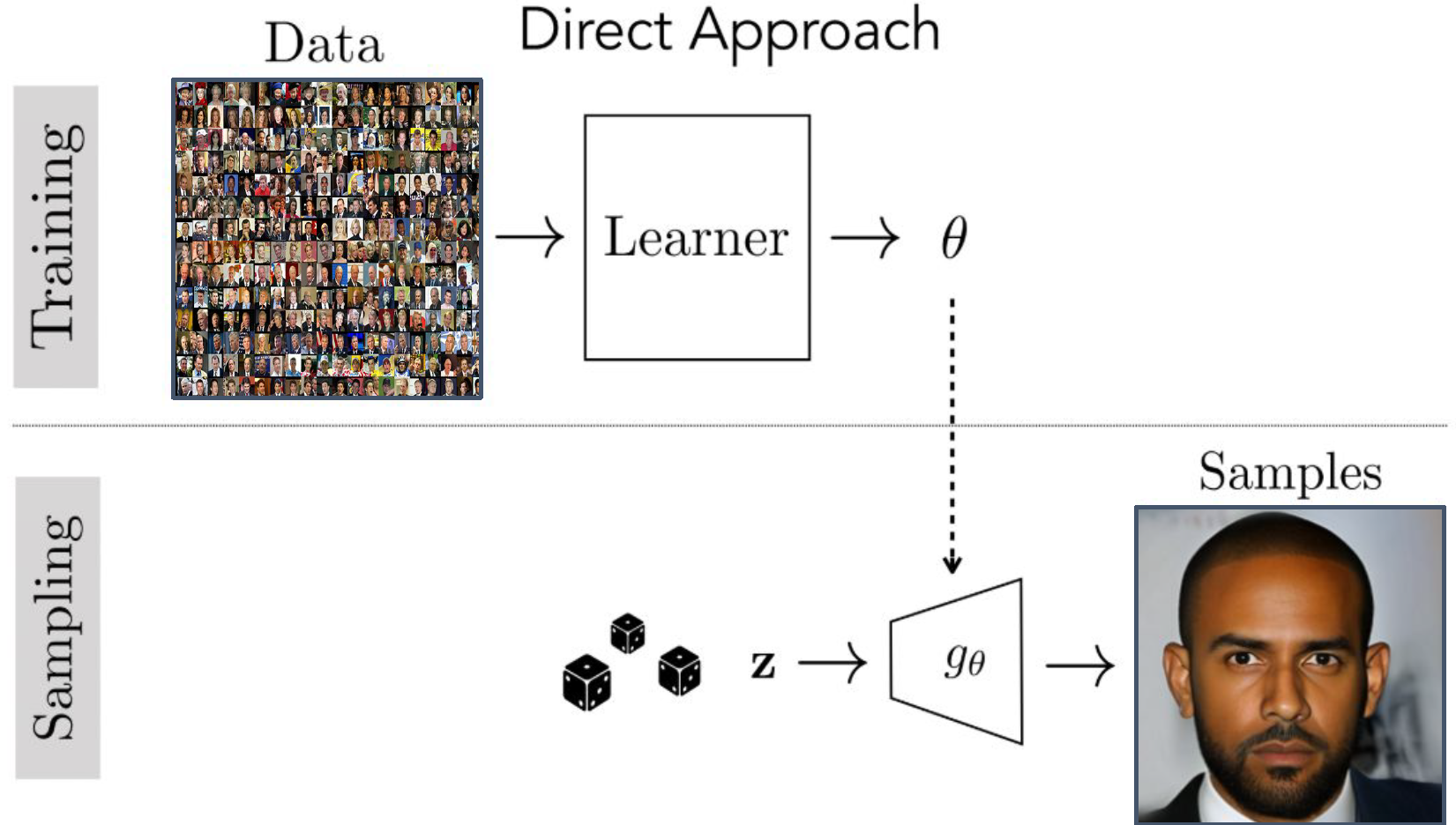
Direct Approach는 우리가 흔히 생각하는, “데이터를 생성하는 함수”를 직접 배우는 모델이다. $G: Z \rightarrow X$라고 표현할 수 있는데, $Z$는 Generator의 입력 공간, 그리고 $X$는 생성될 데이터의 공간이다. 뒤에서 다룰 Variational Autoencoder(VAE)와 Generative Adversarial Network(GAN)이 여기에 속한다. 좀 헷갈리지만 “Implicit Generative Model”이라고도 부르는데, 우리가 학습할 출력의 분포 $p(x)$가 명시적으로 제시되지 않고 Generator 안에 숨겨져 있는 형태이기 때문이다.
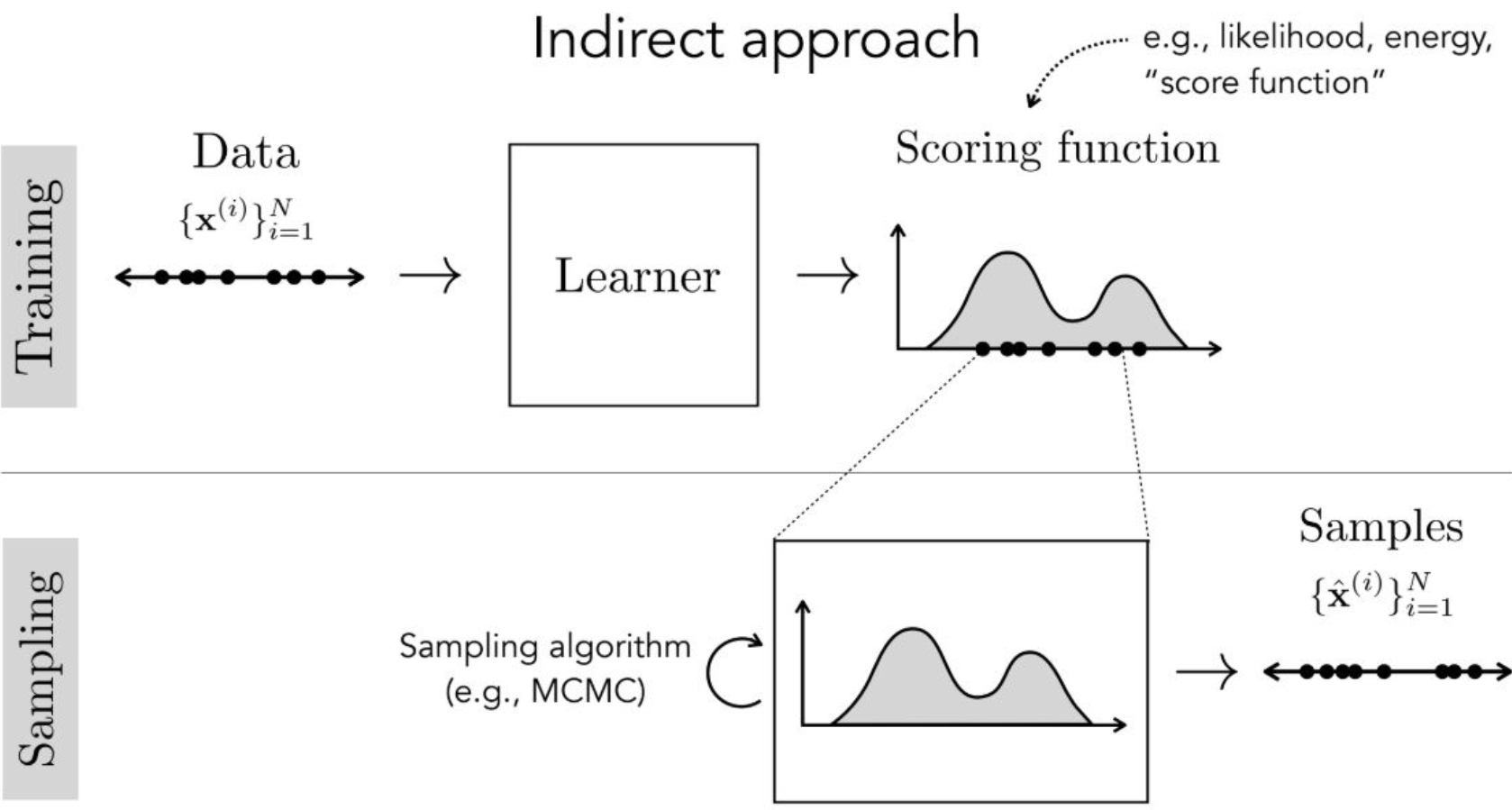
Indirect Approach는 위와는 반대로 Scoring function을 학습하는 모델이며, Scoring function이라는 표현 대신 Energy function이라고 표현하기도 한다. $E: X \rightarrow \mathbb{R}$이라고 쓸 수 있다. 즉 이 모델은 최초에 입력으로 주어진 데이터에 점수를 매기는 역할이고, 이 점수를 기반으로 Generator가 올바른 데이터를 생성하게 유도한다. 여기서 Generator는 MCMC 등의 비교적 계산이 간단한 알고리즘이나 모델을 사용한다. 생성 모델은 확률분포를 학습한다는 위의 내용과 같이 생각해보면, 모델이 출력하는 이 점수 자체가 일종의 분포가 된다고 생각하면 된다. Diffusion 계열의 모델들이 여기에 속한다.
Density-based Models
위에서 생성모델은 분포를 학습하는 모델이라는 것을 알았다. 그러면 이 분포를 학습한다는게 어떤 의미인지 Density-based Model을 통해 알아보자. 이 방법은 이름에서도 알 수 있듯 우리가 학습해야 할 분포 $p(x)$의 PDF가 명확히 존재한다는 가정 하에 진행된다.
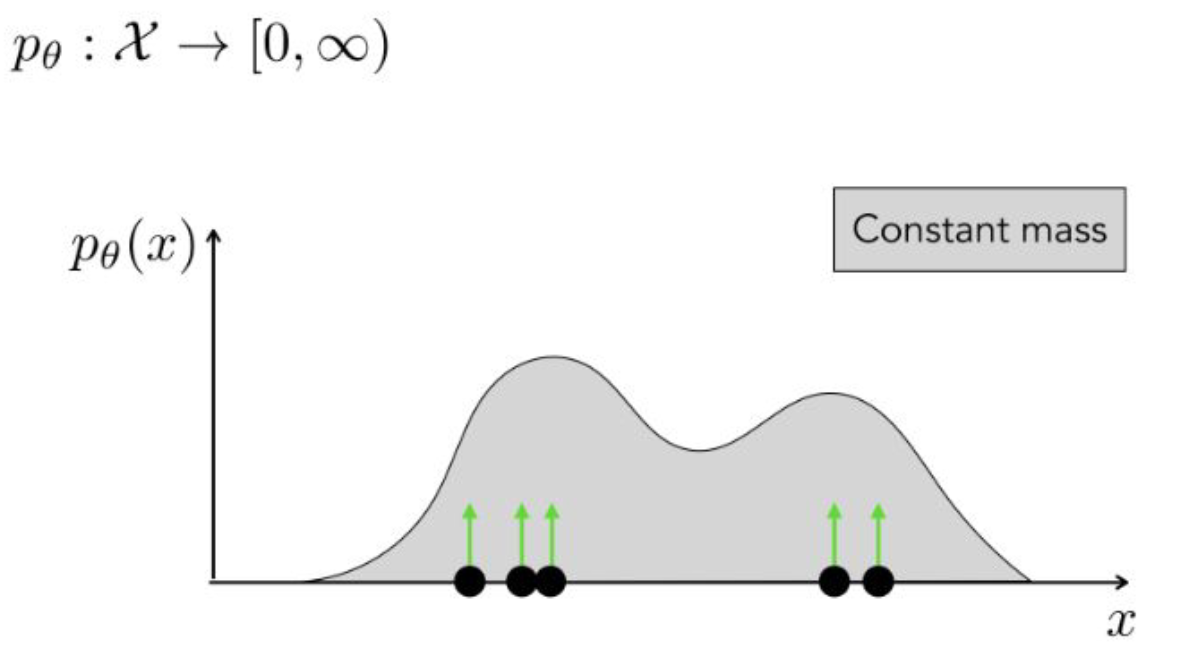
위의 그림에서 $x$축 위의 점이 우리가 갖고 있는 training set이라고 가정해보자. 이 지점에서 데이터가 발견되었기 때문에, 해당 지점의 $p_\theta(x)$는 높아져야 할 것이다. 그렇게 되면 PDF의 특성상 적분한 값이 1로 고정되어야 하므로 데이터가 발견되지 않은 다른 영역은 그만큼 값이 줄어들게 된다.
결국 이렇게 $p_\theta$를 우리가 갖고 있는 데이터에 맞게 조절하는 것이 학습이 된다. 이 방식은 물론 Maximum Likelihood Estimation을 통해 계산한다.
Direct Approach는 여기서 이 $p(x)$를 직접 수식으로 끌고오는 것이라 Explicit Density Model이라고 부르고, Indirect Approach는 Energy function을 통해 이 $p(x)$의 형태를 간접적으로 추론해서 Implicit Density Model이라고 부른다.
Latent Variable Model
그럼 이제 Direct Approach의 한 종류인 Latent Variable Model에 대해 알아보자. 이는 특정 한 모델을 지칭하는 것은 아니고, Direct Approach의 방법 중 하나이다.
Latent Variable Model이라는 이름에서도 알 수 있듯이, 우리가 직접 관측할 수 없는 잠재적인 변수 $z$가 존재하며 이를 통해 관측 데이터 $x$를 만들어낸다는 가정을 깔고 들어간다.
그러면 이 잠재적인 변수 또한 특정한 분포 $p_{data}(z)$에서부터 샘플링된다고 볼 수 있으며, 관측 데이터 $x$ 또한 다른 분포 $p_\theta(x)$를 따른다고 가정할 수 있다.
여기까지 진행되면, 우리의 목표는 $p_{data}(x)$와 $p_\theta(x)$를 최대한 유사하게 만드는 것이 된다. 즉, 생성되는 각각의 데이터 $x$가 완벽히 일치하는지는 더 이상 우리에게 중요한 요소가 아니다. 두 확률분포가 유사하다면 이들의 KL Divergence가 최소화 되어야 한다.
\[\theta^{\ast}=\arg\min_{\theta}D_{KL}(p_{data} \Vert p_{\theta})\]이는 MLE 문제가 되니 다음과 같이 정리할 수 있다.
\[\begin{aligned} \theta^{\ast} &=\arg\min_{\theta}D_{KL}(p_{data} \Vert p_{\theta}) \\ &= \arg\min_{\theta}\sum_{x}p_{data}(x)\log\dfrac{p_{data}(x)}{p_{\theta}(x)} \\ &= \arg\min_{\theta}\sum_{x}\left(p_{data}(x)\log p_{data}(x)-p_{data}(x)\log p_{\theta}(x)\right) \\ &= \arg\max_{\theta}\sum_{x}p_{data}(x)\log p_{\theta}(x) \\ &= \arg\max_{\theta}\mathbb{E}_{x\sim p_{data}}\log p_{\theta}(x) \end{aligned}\]그런데 $p_{\theta}(x)$는 우리의 학습 대상이고, 아직은 이게 어떠한 형태를 갖고 있는지도 모른다. 그렇기 때문에 어떻게든 이 $p_{\theta}$를 우리가 계산할 수 있는 형태로 표현해야 한다.
\[p_{\theta}(x)=\int_{z}p_{\theta}(x \vert z)p(z)\,dz\]우선 가장 간단히 생각해볼 수 있는건 위의 형태일 것이다. 그런데 이것도 문제가 있다. $z$가 존재한다고 가정은 했지만, 우리는 $z$ 및 그 확률분포 $p(z)$가 어떠한 형태인지 모른다. 즉 이들도 우리가 다룰 수 없는(Intractable) 변수이다.
어떻게든 $\log p_{\theta}(x)$를 우리가 다룰 수 있는 형태로 만들기 위해, 임의의 확률분포 $q(z)$를 도입한 후 $\int q(z)\,dz=1$을 이용해서 아래와 같이 전개해보자.
\[\begin{aligned} \log p_{\theta}(x) &= \int_{z}q(z)\log p_{\theta}(x)\,dz \\ &= \int_{z}q(z)\log\dfrac{p_{\theta}(x\vert z)p_{\theta}(z)}{p_{\theta}(z\vert x)}\,dz \\ &= \int_{z}q(z)\log\left(\dfrac{p_{\theta}(x\vert z)p_{\theta}(z)}{p_{\theta}(z\vert x)}\dfrac{q(z)}{q(z)}\right)\,dz \\ &= \int_{z}q(z)\left(\log p_{\theta}(x\vert z)+\log\dfrac{p_{\theta}(z)}{q(z)}+\log\dfrac{q(z)}{p_{\theta}(z\vert x)}\right)\,dz \\ &= \mathbb{E}_{z\sim q(z)}\left[\log p_{\theta}(x\vert z)\right]-D_{KL}\left(q(z) \Vert p_{\theta}(z)\right) + D_{KL}\left(q(z) \Vert p_{\theta}(z\vert x)\right) \end{aligned}\]위 식에서 앞의 두 항들은 우리가 $q(z)$를 임의로 정할 수 있기 때문에 tractable하고, 마지막 항의 경우 $p_{\theta}(z\vert x)$이 포함되어 있어 이를 계산하기 위해선 또다시 $p_{\theta}(x)=\int_{z}p_{\theta}(x \vert z)p(z)\,dz$를 이용해야 하기 때문에 그냥 intractable로 취급한다. 그러면 intractable한 항을 전부 좌변으로 넘기면 다음과 같이 된다.
\[\log p_{\theta}(x)-D_{KL}\left(q(z) \Vert p_{\theta}(z\vert x)\right)=\mathbb{E}_{z\sim q(z)}\left[\log p_{\theta}(x\vert z)\right]-D_{KL}\left(q(z) \Vert p_{\theta}(z)\right)\]이 식의 우측항은 전부 우리가 계산할 수 있는 값이며, 이를 Evidence Lower Bound(ELBO)라고 부른다. 말 그대로 $\log p_{\theta}(x)$의 Lower bound가 되는 것이다.
여기까지의 내용들은 임의의 확률분포 $q(z)$에 대해서 성립한다. 이제 이 $q(z)$를 어떻게 정의하느냐에 따라 Latent Variable Model을 어떻게 구체화시킬지 나뉜다.
Variational Autoencoder
Variational Autoencoder, 즉 VAE는 위에서 논의한 Latent Variable Model의 한 종류이다.
\[\log p_{\theta}(x)-D_{KL}\left(q(z) \Vert p_{\theta}(z\vert x)\right)=\mathbb{E}_{z\sim q(z)}\left[\log p_{\theta}(x\vert z)\right]-D_{KL}\left(q(z) \Vert p_{\theta}(z)\right)\]우리의 목표는 이 ELBO를 최대화하는 것이다. 좌변의 항들을 직접 계산할 수는 없지만 이 값이 크게 되려면 어떻게 해야하는지는 명확한데, $\log p_{\theta}(x)$를 크게 만들거나, $D_{KL}\left(q(z) \Vert p_{\theta}(z)\right)$를 작게 만들어야 한다.
$\log p_{\theta}(x)$를 크게 만드려면 좋은 데이터를 생성해야 하고 이건 우리가 수식적으로 계산할 수 없기 때문에, 두 번째 항에 주목해보자. 이 KL Divergence를 최대한 작게, 즉 0으로 만드는 가장 이상적인 방법은 당연히 $q(z)=p_{\theta}(z \vert x)$를 택하는 것이다.
그런데 우리는 이미 $p_{\theta}(z \vert x)$를 계산할 수 없다는 것을 알고 있다. 그래서 대신 Tractable한 분포로 근사시키려고 한다. 여기서 $q(z)$는 $x$에 영향을 받아야 하는데, 이는 이상적인 분포 $p_{\theta}(z\vert x)$가 $x$마다 다른 분포라 $q(z)$가 $x$에 영향을 받지 않으면 이 이상적인 분포를 따라갈 수 없기 때문이다. 그렇기 때문에 파라미터 $\phi$를 가진 또 다른 신경망을 만들어서, $q(z)$를 $q_{\phi}(z\vert x)$로 취한다. 이러한 접근법을 Variational Inference라고 하며, VAE의 “Variational”도 여기에서 따온 것이다.
여기까지 봤을 때 이 모델의 Learner와 Generator는 각각 다음의 구조를 만족해야 한다.
- Learner: $q_{\phi}(z\vert x)$, $x$를 받아서 Latent Variable $z$의 분포를 출력 (Encoder)
- Generator: $p_{\theta}(x\vert z)$, $z$를 받아서 $x$를 재구성 (Decoder)
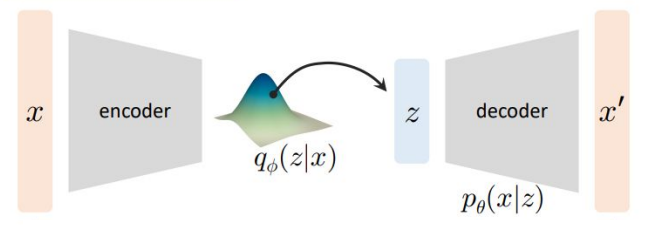
이를 그림으로 그려보면 위와 같은데, 이건 Autoencoder와 동일한 형태가 된다. VAE가 “Autoencoder”인 이유가 여기에 있다. 물론 Autoencoder와 형태만 동일할 뿐이고, Encoder가 $z$ 자체가 아니라 $z$의 분포를 출력한다는 점에서 실제로 같은 일을 하는 것은 아니다.
여기까지의 내용을 반영하면 ELBO는 다음과 같이 바뀐다.
\[L_{\theta,\phi}(x)=\mathbb{E}_{z\sim q_{\phi}(z\vert x)}\left[\log p_{\theta}(x\vert z)\right]-D_{KL}\left(q_{\phi}(z\vert x) \Vert p(z)\right)\]여기서 $p_{\theta}(z)$가 $p(z)$로 바뀐 것을 알 수 있는데, 이는 $p(z)$, 즉 Prior를 학습 대상에서 제외하고 고정된 분포로 가정하겠다는 의미이다. 이 고정된 분포로는 Latent space를 Gaussian 근방으로 유도하기 위해 $N(0,I)$를 많이 쓴다.
이제 이렇게 변경된 ELBO의 첫 번째 항을 생각해보자.
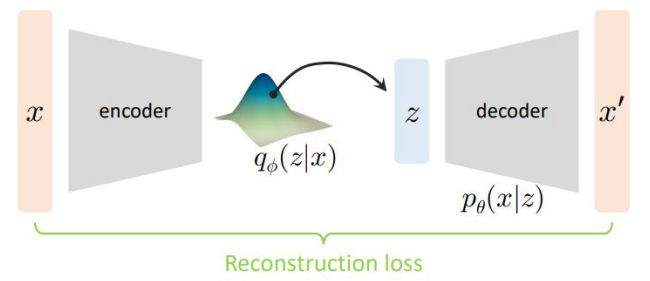
우선 $z$를 $q_{\phi}(z\vert x)$에서, 즉 Encoder에서 나온 분포로 샘플링한다. 이렇게 얻은 $z$를 Decoder에 넣었을 때 원본인 $x$가 나올 확률이 $p_{\theta}(x\vert z)$이다. 즉, $x^{\prime}$이 원본 $x$가 될 확률을 의미하며, 이 값에 로그를 취한 것의 평균을 구한 것이므로 결국 $x$와 $x^{\prime}$이 얼마나 일치하는지를 따지는 Loss값이라고 볼 수 있다. 그렇기 때문에 이를 Reconstruction Loss라고 부른다.
이제 두 번째 항을 생각해보자.
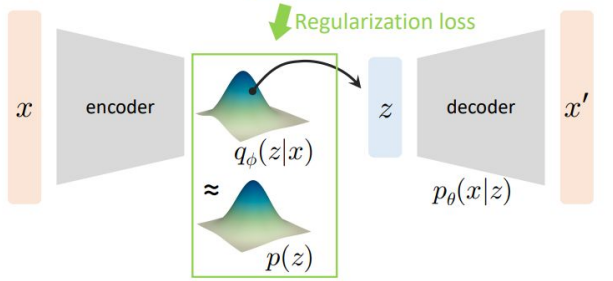
이 항은 우리가 학습시킨 Encoder인 $q_{\phi}(z \vert x)$가 실제 분포 $p(z)$와 얼마나 유사한지를 나타낸다. 그렇기 때문에 이 항을 Regularization Loss라고 부른다.
위의 두 항 모두 중요하다. Reconstruction Loss를 고려하지 않으면 아무리 분포를 잘 학습했더라도 결국 $x$와 $x^{\prime}$을 비슷하게 만들지 못해 이상한 이미지가 나올 것이다. Regularization Loss를 고려하지 않으면 Decoder는 이미지를 제대로 만들 수는 있겠으나 그러기 위해서 어떤 input을 넣어줘야 하는지를 알 수 없다. Encoder가 그 입력값의 분포 $p(z)$와 유사하다는 보장이 사라져 Encoder의 결과가 이상한 값이 되기 때문이다.