Advanced Machine Learning 8 - Neural Networks (1)
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Advanced Machine Learning 과목의 수업을 다룬다. 그리고 수업 때 중간고사 문제 풀이를 먼저 했기 때문에 이번 글은 양이 좀 짧다.
Perceptron
Perceptron은 예전 글에서 언급만 하고 넘어갔던, 현재 딥러닝의 근간이 되는 최초의 인공 신경망의 유닛이다. Perceptron의 동작 방식에 대해 간단히 알아보자.
Perceptron의 Assumption은 크게 다음의 두가지이다.
- Label이 $\lbrace -1,1 \rbrace$인 Binary Classification 문제.
- 각 레이블을 완벽히 가르는 Linear hyperplane $w^Tx+b=0$이 존재한다.
즉, 선형 모델을 가정했기 때문에 표현 가능한 모든 선형 모델이 Hypothesis Class가 되며, 따라서 $H=\lbrace w:w^Tx+b=0\rbrace$가 된다. 그리고 이 선형 모델이 데이터를 가르는 기준점이 되므로, 여기서부터 도출되는 모델 $h(x)=sign(w^Tx+b)$가 된다. 즉, $w^Tx+b$의 부호에 따라 데이터가 분류된다.
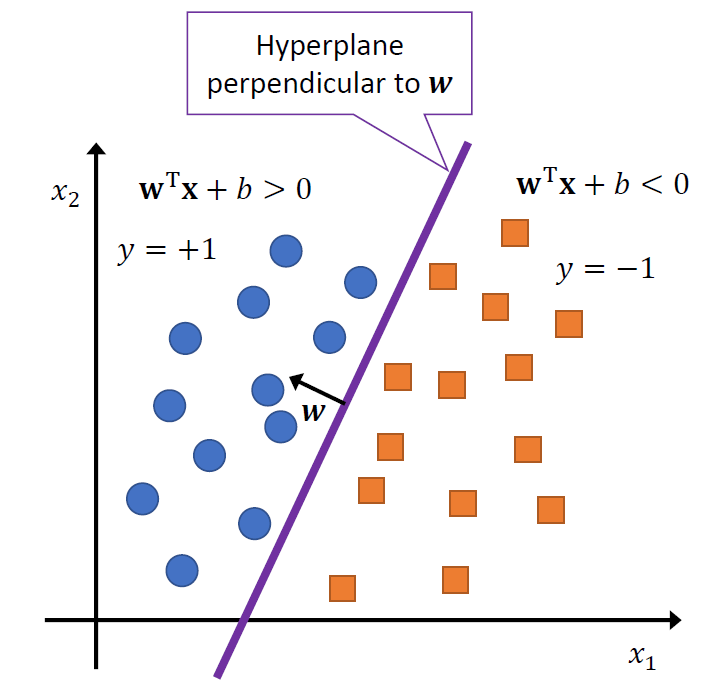
이 Perceptron은 사실 표현력이 굉장히 떨어진다. 애초에 Linear model인데다가 너무 제한적인 상황을 가정하고 있기 때문이다. 애초에 두 class가 선형적으로 구분이 불가능한 경우 Perceptron만으론 절대 구분할 수 없다.
이를 타파하기 위해서는 Non-linear한 함수를 Perceptron만으로 표현할 수 있어야 한다. 이를 위해 생각할 수 있는 방법 중 하나는, 이 Perceptron을 여러 겹 쌓는 것이다. 즉, Perceptron으로 만들어지는 여러 값들을 다시 입력으로 생각해서, 그들을 대상으로 한 Perceptron을 배치하고, 이 과정을 여러 번 반복하는 것이다.
이렇게 배치된 네트워크를 Multi Layer Perceptron, 즉 MLP라고 부른다. 여담으로 이 MLP라는 용어는 지금까지도 살아남아서, Fully-connected Network를 아직도 MLP라고 많이 부른다.
Motivations
이렇게 MLP를 만들어보니까 몇 가지 문제가 발생했는데, 주된 이유는 Perceptron은 $sign$을 따지기 때문이다. $sign$을 따지는 특성상 표현력에 상당한 한계가 있는 것은 물론이고, 이 함수는 미분이 불가능하기 때문에 학습하기도 어려웠다.
그래서 $sign$ 대신 다른 적합한 함수를 찾았는데, 처음에는 Sigmoid를 사용했었다. 그러나 Sigmoid 역시 학습이 그렇게 수월하진 않았는데, 이는 Sigmoid의 미분값은 최댓값이 대략 0.25이며, 특정 구간을 제외하면 대부분 0에 수렴하기 때문이다. 그로 인해 Gradient가 너무 쉽게 0으로 수렴해버리는 문제가 발생한다. 이를 Vanishing Gradient Problem이라고 한다.
이를 해결하기 위해 고안된 함수가 Rectified Linear Unit, 즉 ReLU다. $ReLU(x)=\max(0,x)$로 정의되는데, $x>0$이라면 미분값이 1이 나와 항상 Gradient가 잘 흐르게 된다.
위의 알고리즘적인 이슈 외에도 계산이 느리다는 하드웨어적인 이슈는 GPU 및 GPGPU의 발달로 해결이 되었고, 점점 더 거대한 데이터셋이 등장함에 따라 데이터 공급의 문제도 해결되었다.
마지막으로 Gradient Descent를 다룬 글에서 마지막에 잠깐 언급한, Gradient를 “적절하게 나눠서 계산할 수 있다”는 점이 여기서 상당한 이득으로 돌아왔다. 그저 계산의 병렬성을 위해 고안되었던 Stochastic Gradient Descent, 즉 SGD가 사실은 Local minimum을 피해갈 수 있는 가능성을 제시해준다는 점이 발견되어서, 학습 효율도 상당히 올라가게 되었다.
여기에 이러한 네트워크를 “Deep Learning”이라고 명명한 리브랜딩까지 더해져서 다시 사람들의 관심을 끌게 되었고, 그것이 현대 딥러닝의 시초가 되었다.
Universal Approximator
이렇게 잘 구성된 MLP는 모든 함수를 다 학습할 능력이 있다는 것이 증명되었으며, 이를 Universal Approximation Theorem이라고 한다. 이에 대한 증명 방법은 여러 가지가 있지만, 여기서는 가장 개념적으로 이해하기 쉬운 방법을 소개한다.
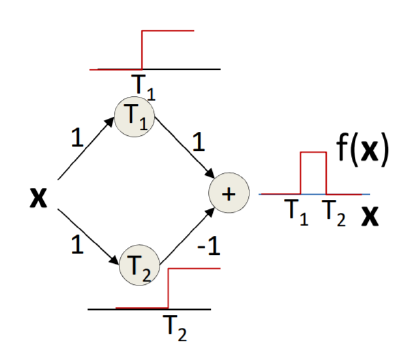
먼저 위와 같은 간단한 MLP를 생각해보자. 특정한 수 $T_1$, $T_2$에 대해서 Bias가 걸려있는 형태로 구성하게 되면, 이를 통해 학습하게 되는 함수의 형태는 다음과 같다.
\[f(x)=\begin{cases}1&x\in[T_1,T_2]\\0&\text{otherwise}\end{cases}\]즉, 구간 $[T_1,T_2]$에서만 1, 그 외의 구간에서는 0이 나온다. 그리고 이 MLP의 상수값들을 조절해서, 구간의 경계값 $T_1$, $T_2$, 그리고 출력값 $1$을 우리가 원하는대로 바꿀 수 있다.
그러면 임의의 적분가능한 함수를 생각해보자. 아주 좁은 구간에 대한 이러한 “막대기” 형태의 직사각형을 이어붙이면 그게 곧 적분가능한 함수의 형태가 된다. 즉, 유닛들을 충분히 많이 배치하면, MLP는 항상 단일 변수 $x$에 대한 임의의 적분가능한 함수로 근사할 수 있다는 것을 알 수 있다.
그럼 다변수 함수라면 어떻게 하면 될까? 방법은 간단한데, 이러한 좁은 구간의 “막대기”가 여러 변수들에 대한 $N$차원으로 확장되었으니 이 “막대기”를 학습하는 MLP가 모든 변수에 대해서 입력을 받아서 출력해주면 된다. 그리고 이를 $N$차원 공간에 투영시키면 그대로 성립함을 알 수 있다.
이렇게 “유닛 수가 충분히 많으면” 어떠한 함수도 MLP만으로 표현가능하다는 것을 알 수 있다. 그런데 현실적으론 “유닛 수가 충분히 많으면”이라는 조건을 만족하는 것은 불가능에 가깝다. 위의 사고실험만 봐도, 저 방식으로 학습시키려면 아주 간단한 함수조차도 무수히 많은 수의 유닛이 필요해진다. 그렇기 때문에 유닛이 무수히 많은 Single hidden layer 대신 hidden layer의 깊이를 늘리는 방향으로 연구가 이루어진다.