Advanced Machine Learning 9 - Neural Networks (2)
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Advanced Machine Learning 과목의 수업을 다룬다.
Forward Computation
MLP도 결국은 머신러닝에 속하기 때문에 추론을 어떻게 하는지, 그리고 학습을 어떻게 시킬 수 있는지를 따져봐야 한다. 먼저 추론에 대해 알아보자.
우선 $d$개의 Layer가 있는 Neural Network에서, $l$번째 Layer의 각 노드들을 $h_1^l, h_2^l, \ldots, h_{n_l}^l$로, 그리고 두 개의 노드 $h_i^{l-1}$에서 $h_j^l$ 사이의 Weight를 $w_{ij}^l$이라고 하자. 그리고 노드 $h_j^l$에서의 Input, Output을 각각 $z_j^l$, $x_j^l$이라고 하자.
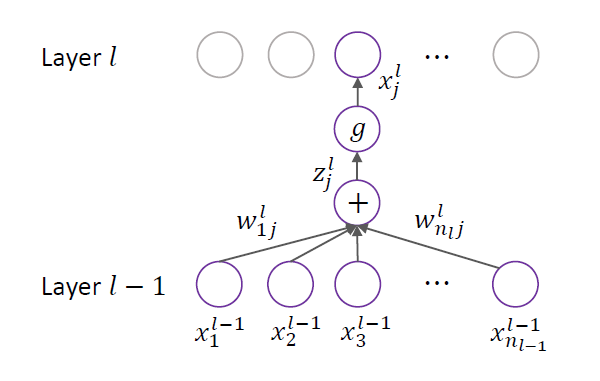
그러면 위의 그림과 같이 정의가 된다. 여기서 $g$는 비선형으로 바꿔주는 Activation Function이다. 또한 기본적으로 MLP는 Fully-connected Layer, 즉 모든 노드간의 연결이 전부 존재하기 때문에 위와 같은 상황이 모든 노드, 모든 Layer에 대해서 동일하게 이뤄지고 있다고 볼 수 있다.
\[z_j^l=\sum_{i=1}^{n_{l-1}}w_{ij}^l x_i^{l-1}, x_j^l=g(z_j^l)\]수식으로는 위와 같이 표현할 수 있다. 이 과정을 모든 노드에 대해, 그리고 모든 Layer에 대해 계산하면 된다.
Back Propagation
그러면 추론은 위와 같이 하면 된다는 것을 알았는데, 학습은 어떻게 하면 될까? 학습을 하기 위해선 ERM을 구해야 한다. 그리고 데이터셋 $D \in \lbrace (x_1,y_1),\ldots,(x_n,y_n)\rbrace$, 손실 함수를 $l(\cdot,\cdot)$이라고 하면, ERM은 다음과 같이 쓸 수 있다.
\[L(w)=\sum_{i=1}^{n}l(f_w(x_i),y_i)\]즉, 그동안 봤던 그 ERM의 형태 그대로다. 이후의 과정도 동일하다. $w^{\ast}=\min_{w} L(w)$를 만족하는 $w^{\ast}$를 찾으면 된다. 물론 $f_w$의 형태가 상당히 복잡하기 때문에 Gradient Descent를 활용해야 한다.
그런데 Gradient Descent를 활용하는건 좋은데 MLP의 모델은 여러 Layer로 분리된 그 특성상 함수의 형태가 상당히 복잡한 합성함수로 이루어져 있다. 그래서 얼핏 보면 Gradient를 구하는 것도 상당히 까다로워 보인다. 이를 어떻게 하면 효율적으로 계산할 수 있을까?
이를 위한 방법으로 제시된 것이 Back Propagation이다. 이 알고리즘은 1986년도에 처음 제시되었을 정도로 오래되었지만, 아직도 가장 효율적인 학습 방법이라서 대부분의 현대 딥러닝 모델들은 여전히 Back Propagation을 사용한다.
Back Propagation을 이해하기 위해서는 다음의 두 가지 관찰이 핵심적으로 작용한다.
합의 Gradient는 Gradient의 합과 같다.
\[\nabla_w L(w)=\sum_{i=1}^{n}\nabla_w l(f_w(x_i),y_i)\]즉 위와 같은 식이 성립하며 따라서 우리는 $\nabla_w l(f_w(x_i),y_i)$를 구하면 된다.
미분에는 Chain Rule이 존재한다. 즉 $h(w)=f(g(w))$라고 정의하면, $h$의 도함수 $h^{\prime}$은 다음과 같다.
\[h^{\prime}(w)=f^{\prime}(g(w))g^{\prime}(w)\]이것이 “Chain” Rule인 이유는, $z=f(u)$, $u=g(w)$로 두면 아래처럼 정리가 되기 때문이다.
\[\dfrac{\partial z}{\partial w} = \dfrac{\partial z}{\partial u} \cdot \dfrac{\partial u}{\partial w}\]
그럼 이제 어떻게 Gradient를 계산할 수 있을지 몇 가지 특정한 Layer 및 노드를 예시로 들어 살펴보자.
먼저 첫 번째 Layer의 경우는 다음과 같다. 이 Layer에서의 Input은 $x=(x_1,\ldots,x_{n_0})$이고, Output은 $z_1^1=\sum\limits_{i=1}^{n_0} w_{i1}^1 x_i$, $x_1^1=g(z_1^1)$이 된다. 여기서 각각의 변수의 의미는 Forward Computation을 정의했을 때 사용했던 그 notation과 동일하다.
여기서 첫 번째 노드에 대한 Gradient $\nabla_{w^1}x_1^1$을 계산하면 다음과 같다.
\[\dfrac{\partial x_1^1}{\partial w_{11}^1}=\dfrac{\partial x_1^1}{\partial z_1^1}\cdot\dfrac{\partial z_1^1}{\partial w_{11}^1}=g^{\prime}(z_1^1)\cdot x_1=dg(z_1^1)\cdot x_1\]그런데 위의 식은 모든 노드에 대해서 다 동일하게 적용이 가능하다. 즉, 첫 번째 Layer의 $i$번째 노드에 대해서는 다음과 같다.
\[\dfrac{\partial x_1^1}{\partial w_{i1}^1}=\dfrac{\partial x_1^1}{\partial z_1^1}\cdot\dfrac{\partial z_1^1}{\partial w_{i1}^1}=g^{\prime}(z_1^1)\cdot x_i=dg(z_1^1)\cdot x_i\]이제 두 번째 Layer에 대해서 같은 방식으로 구해보자. 위에서 했던 과정과 비슷하게, 이 Layer에서의 Input과 Output은 각각 $x=(x_1^1,\ldots,x_{n_1}^1)$, $z_1^2=\sum\limits_{i=1}^{n_1} w_{i1}^2 x_i^1$, $x_1^2=g(z_1^2)$가 된다.
여기서 $i$번째 노드에 대한 Gradient를 구하면 역시 같은 방법으로 다음과 같이 전개된다.
\[\dfrac{\partial x_1^2}{\partial w_{i1}^2}=\dfrac{\partial x_1^2}{\partial z_1^2}\cdot\dfrac{\partial z_1^2}{\partial w_{i1}^2}=g^{\prime}(z_1^2)\cdot x_i^1=dg(z_1^2)\cdot x_i^1\]그런데 여기서 각각의 Layer는 서로 연관되어 있다. 구체적으론 다음의 식이 성립한다.
\[\dfrac{\partial z_1^2}{\partial x_1^1}=\dfrac{\partial}{\partial x_1^1}\sum_{i=1}^{n_1}w_{i1}^2 x_i^1=w_{11}^2\] \[\dfrac{\partial z_1^1}{\partial w_{11}^1}=\dfrac{\partial}{\partial w_{11}^1}\sum_{i=1}^{n_0}w_{i1}^1 x_i=x_1\]따라서 $x_1^2$의 $w_{11}^1$에 대한 Gradient도 계산할 수 있으며, 이는 다음과 같다.
\[\begin{aligned} \dfrac{\partial x_1^2}{\partial w_{11}^1} &= \dfrac{\partial x_1^2}{\partial z_1^1}\cdot\dfrac{\partial z_1^1}{\partial w_{11}^1} \\ &= \dfrac{\partial x_1^2}{\partial x_1^1}\cdot\dfrac{\partial x_1^1}{\partial z_1^1}\cdot\dfrac{\partial z_1^1}{\partial w_{11}^1} \\ &= \dfrac{\partial x_1^2}{\partial z_1^2}\cdot\dfrac{\partial z_1^2}{\partial x_1^1}\cdot\dfrac{\partial x_1^1}{\partial z_1^1}\cdot\dfrac{\partial z_1^1}{\partial w_{11}^1} \\ &= dg(z_1^2)\cdot w_{11}^2 \cdot dg(z_1^1) \cdot x_1 \end{aligned}\]그리고 이를 $i$번째 입력에 대해 일반화하면 다음이 성립한다.
\[\dfrac{\partial x_1^2}{\partial w_{i1}^1}=dg(z_1^2)\cdot w_{i1}^2 \cdot dg(z_1^1) \cdot x_i\]여기까지 계산해보니까 비슷한 형태의 계산식이 상당히 자주 사용되고 있음을 알 수 있다. 이 아이디어를 일반화하면 다음과 같은 식으로 순서대로 계산하면 모든 Gradient를 구할 수 있다.
우선 마지막 Layer에서는 다음이 성립한다.
\[\dfrac{\partial f}{\partial x_1^d}=1, \dfrac{\partial f}{\partial z_1^d}=dg(z_1^d)\]그리고 그 이전의 $l$번째 Layer에 대해서는 다음이 성립한다.
\[\dfrac{\partial f}{\partial x_i^l}=\sum_{j=1}^{n_{l+1}}\dfrac{\partial f}{\partial z_j^{l+1}}\cdot\dfrac{\partial z_j^{l+1}}{\partial x_i^l}=\sum_{j=1}^{n_{l+1}}\dfrac{\partial f}{\partial z_j^{l+1}}\cdot w_{ij}^{l+1}\] \[\dfrac{\partial f}{\partial z_i^l}=\dfrac{\partial f}{\partial x_i^l}\cdot\dfrac{\partial x_i^l}{\partial z_i^l}=\dfrac{\partial f}{\partial x_i^l}\cdot dg(z_i^l)\]위의 값들을 이용해서, 임의의 Weight $w_{ij}^l$에 대한 Gradient는 다음과 같이 구할 수 있다.
\[\dfrac{\partial f}{\partial w_{ij}^l}=\dfrac{\partial f}{\partial z_j^l}\cdot\dfrac{\partial z_j^l}{\partial w_{ij}^l}=\dfrac{\partial f}{\partial z_j^l}\cdot x_i^{l-1}\]위의 알고리즘은 계산 순서가 마지막 Layer에서부터 내려가는 방향으로 이루어지기 때문에 Back Propagation이라고 부른다. 중복으로 필요한 정보들은 Memoization을 통해 계산을 최소화할 수 있어, 시간 복잡도가 $O(network-size)$가 되는 매우 효율적인 알고리즘이다.
또한 위의 과정에선 Bias를 빼고 계산했는데, 실제론 Bias를 넣고 계산해도 방식이나 계산 결과 등이 크게 달라지진 않는다.
Stochastic Gradient Descent
그런데 위의 방법으로 계산한 Gradient Descent는 모든 데이터셋에 대해 한번에 계산한 후 그 방향대로 이동하는 것을 의미한다. 그리고 이 방법은 그 한번의 계산에 너무 오랜 시간이 걸린다. 정확히는 $O(nd)$가 필요한데, 데이터셋이 매우 크면 이 시간조차도 상당한 부담으로 다가온다.
이를 극복하기 위해 Stochastic Gradient Descent, 즉 SGD라는 방법이 제안되었다. “Stochastic”이라는 이름 그대로, 데이터셋을 한번에 모아서 그 Gradient를 계산하는 것이 아니라, 이 중 일부를 뽑아서 이들의 Gradient를 계산하는 방식을 반복하는 방법으로 이루어진다.
SGD를 적용하게 되면 Gradient Descent와는 달리 매 순간마다 뽑는 데이터에 따라 가는 방향이 달라지게 된다. 이 말은 곧 항상 최적의 방향으로 간다는 보장이 사라지게 된다. 그 대신 매 스텝마다의 계산이 빨라진다는 이점과 Gradient의 방향에 대한 랜덤성을 얻게 되는데, 이 랜덤성 때문에 실제로 선형 모델들에서는 성능이 월등하게 떨어진다. 그래서 일반적인 ML 모델에서는 사용하지 않는 방식이었다.
그러나 딥러닝으로 오게 되면서 필요한 파라미터의 수가 너무 많아지게 되고 그에 비례하여 데이터셋의 크기 또한 굉장히 커지게 되었다. 이는 곧 랜덤성 문제를 차치하고서라도 계산이 빨라진다는 점 때문에라도 SGD를 사용할 수 밖에 없는 상황이 되었다는 의미가 된다. 그런데 재미있는 점은, 이렇게 SGD를 울며 겨자먹기로 사용했는데 이상하게 성능이 훨씬 좋아졌다는 사실이 발견되었다는 것이다.
이러한 현상의 이유는 SGD의 랜덤성으로 인해 Local Minima에 빠지지 않거나 혹은 빠지더라도 탈출할 수 있는 가능성이 주어지기 때문인 것으로 알려져 있다. 파라미터 차원이 매우 높은 특성상 수많은 Local Minima가 존재하는데, 일반적인 Gradient Descent라면 이동할 방향이 고정된 이상 각종 테크닉을 아무리 사용하더라도 이러한 Local Minima에서 벗어나기 쉽지 않다. 그러나 SGD는 그 특유의 랜덤성으로 인해 어떤 데이터가 뽑혔느냐에 따라 이를 탈출할 가능성이 주어진다는 것이고, 이것이 오히려 현재는 SGD의 핵심적인 역할로 받아들여지고 있다.
다만 원래 SGD는 데이터를 한번에 1개씩 뽑아서 계산하는 것이다. 그렇게 해야지 흔히들 얘기하는 Sampling이 되는 것이고, 그래야 Expectation의 관점으로 SGD를 설명할 수 있다. 그런데 1개씩 Sampling해서 계산하는 것은 병렬 컴퓨팅 관점에서 너무 좋지 않은 선택이다. 그렇기 때문에 Batch size $m$을 정해서, 한번에 $m$개씩 뽑아서 그들에 대한 Gradient를 구한 후 더해주는 식의 변형 SGD를 주로 사용한다.
또한 원래 SGD는 데이터를 Sampling해서 사용한다. 즉, 동일한 데이터가 여러 번 뽑혀서 Gradient 계산에 사용될 수 있다. 그런데 우리가 흔히 사용하는 SGD는 데이터 전체를 $m$개씩 나눠서 이들을 한 바퀴 돌리는 방식을 사용하는데, 이렇게 해도 전체적인 경향성은 동일하다.
Convergence of Stochastic Gradient Descent
Gradient Descent의 수렴성을 증명했던 것과 같이, SGD도 수렴성을 보장한다는 것이 수학적으로 증명되었다.
우선 다음의 두 가지를 먼저 정리하고 넘어가자. 우선, 임의의 Vector $v$에 대해, Variance $Var(v)=E[\lVert v \rVert_2^2] - \lVert E[v] \rVert_2^2$이다. 또한 SGD는 랜덤성이 가미된 알고리즘인만큼, 분석을 단순화하기 위해 다음의 가정을 하고 가자.
\[\bar{w}_k=\dfrac{1}{k}(w_1+w_2+\cdots+w_k)\]위의 가정 및 정의 하에서, 우리가 증명해야 할 명제는 다음과 같다.
“Let $f:\mathbb{R}^d \rightarrow \mathbb{R}$ be a L-Lipschitz convex function and $w^{\ast}=\arg\min\limits_w f(w)$. Consider and instance of SGD where the estimators $v_t$ have bounded variance, i.e., for all $t \geq 0$, $Var(v_t) \lt \sigma^2$. Then, for any $k \gt 1$, SGD with step-size $\alpha \leq \dfrac{1}{L}$ satisfies
\[E[f(\bar{w}_k)] \leq f(w^{\ast}) + \dfrac{\lVert w_0-w^{\ast} \rVert_2^2}{2\alpha k} + \dfrac{\alpha \sigma^2}{2}\]where $\bar{w}_k=\dfrac{1}{k}(w_1+w_2+\cdots+w_k)$.”
증명은 크게 5단계로 이루어진다.
Expand the distance.
SGD 알고리즘의 정의에 의해, $w_{t+1}=w_t-\alpha v_t$이다. 이를 $\lVert w_{t+1}-w^{\ast} \rVert_2^2$에 적용하면,
\[\begin{aligned} \lVert w_{t+1}-w^{\ast} \rVert_2^2 &= \lVert w_t-\alpha v_t-w^{\ast} \rVert_2^2 \\ &= \lVert w_t-w^{\ast} \rVert_2^2 - 2\alpha\langle v_t,w_t-w^{\ast} \rangle + \alpha^2 \lVert v_t \rVert_2^2 \end{aligned}\]따라서, 다음을 얻는다.
\[\langle v_t,w_t-w^{\ast} \rangle = \dfrac{\lVert w_t-w^{\ast} \rVert_2^2 - \lVert w_{t+1}-w^{\ast} \rVert_2^2}{2\alpha} + \dfrac{\alpha}{2}\lVert v_t \rVert_2^2\]Function value.
$f$는 Convex function이므로, 다음이 성립한다.
\[f(w^{\ast}) \geq f(w_t)+\nabla f(w_t)^T(w^{\ast}-w_t)\]따라서, 다음을 얻는다.
\[f(w_t)-f(w^{\ast}) \leq \langle \nabla f(w_t),w_t-w^{\ast} \rangle\]Expectation & Variance.
$\langle v_t,w_t-w^{\ast} \rangle$에 $w_t$에 대한 조건부 기댓값을 취하면 다음과 같다.
\[E[\langle v_t,w_t-w^{\ast} \rangle \vert w_t]=\langle \nabla f(w_t),w_t-w^{\ast} \rangle\]따라서 위에서 얻은 식들과 합치면,
\[E[f(w_t)]-f(w^{\ast}) \leq \dfrac{E[\lVert w_t-w^{\ast} \rVert_2^2] - E[\lVert w_{t+1}-w^{\ast} \rVert_2^2]}{2\alpha} + \dfrac{\alpha}{2}E[\lVert v_t \rVert_2^2]\]여기서, 위의 Variance의 정의에 의해,
\[E[\lVert v_t \rVert_2^2] = Var(v_t)+\lVert \nabla f(w_t) \rVert_2^2 \leq \sigma^2 + L^2\]따라서, 다음을 얻는다.
\[E[f(w_t)]-f(w^{\ast}) \leq \dfrac{E[\lVert w_t-w^{\ast} \rVert_2^2] - E[\lVert w_{t+1}-w^{\ast} \rVert_2^2]}{2\alpha} + \dfrac{\alpha(\sigma^2 + L^2)}{2}\]Telescoping.
3에서 얻은 부등식을 $t=0,1,\ldots,k-1$에 대해 더하면 다음과 같다.
\[\sum_{t=0}^{k-1}(E[f(w_t)]-f(w^{\ast})) \leq \dfrac{\lVert w_0-w^{\ast} \rVert_2^2 - E[\lVert w_k-w^{\ast} \rVert_2^2]}{2\alpha} + \dfrac{k\alpha(\sigma^2 + L^2)}{2}\]여기서 $E[\lVert w_k-w^{\ast} \rVert_2^2] \geq 0$이므로 소거하면 다음을 얻는다.
\[\dfrac{1}{k}\sum_{t=0}^{k-1}E[f(w_t)]-f(w^{\ast}) \leq \dfrac{\lVert w_0-w^{\ast} \rVert_2^2}{2\alpha k} + \dfrac{\alpha(\sigma^2 + L^2)}{2}\]Jensen’s Inequality.
$f$는 Convex function이므로 Jensen’s inequality에 의해,
\[f\left(\dfrac{1}{k}\sum_{t=0}^{k-1}w_t\right) \leq \dfrac{1}{k}\sum_{t=0}^{k-1}f(w_t)\]위 식에서 양변에 기댓값을 취해도 동일하므로,
\[E[f(\bar{w}_k)] \leq \dfrac{1}{k}\sum_{t=0}^{k-1}E[f(w_t)]\]이 식과 4에서 얻은 식을 결합하면 다음을 얻고 증명이 완료된다.
\[E[f(\bar{w}_k)] \leq f(w^{\ast}) + \dfrac{\lVert w_0-w^{\ast} \rVert_2^2}{2\alpha k} + \dfrac{\alpha (\sigma^2 + L^2)}{2}\]
즉, GD의 수렴성 증명과 동일하게 $E[f(\bar{w}_k)]$의 상한선이 존재하며 그 상한선은 수행횟수 $k$에 반비례하므로 SGD 알고리즘 역시 반드시 수렴함을 알 수 있다.
Subgradient
Back Propagation에서 알 수 있듯이, Neural Network를 훈련시키는 데에는 미분이 반드시 필요함을 알 수 있다. 그런데 각각의 Layer는 최종적으로 Activation function을 거치므로, 이 함수가 미분 가능해야 한다.
그런데 안타깝게도 모든 Activation function이 모든 점에 대해서 미분 가능하진 않다. 가령 흔하게 쓰이는 ReLU만 봐도, $x=0$에서는 미분이 정의되지 않는다. 그러면 이를 어떻게 해결할 수 있을까?
이를 위해 Subgradient라는 수학적 개념을 가져왔다. 함수 $f:\mathbb{R}^d \rightarrow \mathbb{R}$에서 다음을 만족하는 Vector $v$를 $x$에서의 $f$의 Subgradient라고 정의한다.
\[f(y) \geq f(x)+v^T(y-x) \forall y \in \mathbb{R}^d\]또한 $\partial f(x)$를 $x$에서의 $f$에 대한 모든 Subgradient의 집합으로 정의한다. 이를 기하학적으로 생각하면, “접선”을 의미하는 Gradient보다 범위가 좀 더 넓어서, 그래프를 아래에서 받치는 직선의 기울기를 뜻한다. 그래서 미분 가능한 점에서는 Gradient와 동일한 값이 나오고, 미분 불가능한 점에서는 조건을 만족하는 여러 개의 값이 존재한다.
예를 들어 ReLU에서 $x=0$일 때의 Gradient는 정의되지 않지만, SubGradient는 $[0, 1]$이 되고, 절댓값 함수에서도 $x=0$일 때의 Gradient는 역시 정의되지 않지만, SubGradient는 $[-1, 1]$이 된다. 물론 구간값으로 정의되는 특성상 실제로 사용할 때는 이 중 임의의 값을 하나 골라서 사용하는데, 대부분의 머신러닝 라이브러리에선 두 경우 모두 0으로 정해놓고 사용한다.
그리고 Gradient Descent에서는 Gradient 대신 Subgradient를 사용해도 그대로 적용된다. 즉, Activation function이 반드시 모든 점에서 미분 가능하지 않더라도, Subgradient가 정의되는 함수라면 Gradient Descent를 그대로 사용할 수 있다. 실제로 위의 SGD 수렴성 정리의 증명 또한 Subgradient만 정의되는 상황이더라도 증명의 논리를 그대로 적용할 수 있다.
Regularization
저번 글에서 Universal Approximator를 다루면서 Layer 2개짜리인 MLP여도 모든 함수를 표현할 수 있다는 것에 대해 이야기했다. 그러나 표현가능과 학습가능은 다른 개념이다. 실제로 Layer를 2개로 제한하고 모든 함수를 표현하려면 그 Hidden Layer에 필요한 노드의 개수는 굉장히 많을 것이고, 그 파라미터의 개수에 비례하여 요구하는 데이터의 크기도 너무 많아진다. 그렇기 때문에 이론상 학습이 가능하더라도 실제로 그걸 감당할 정도의 연산력 및 데이터셋을 구하기가 불가능에 가깝다.
그렇기 때문에 Layer를 깊게 쌓는 것을 추구하는 방식으로 발전해왔다. 이러한 방식이 어째서 더 효율적일까? 파라미터 개수가 같아도 Layer가 깊을수록 조합의 횟수가 늘어나서, 표현력이 훨씬 높아지기 때문이다. 심지어 이렇게 깊게 쌓아도 위에서 정립한 Back Propagation 덕분에 학습이 딱히 난해해지지도 않는다.
그러나 실제론 학습에 전혀 영향이 없는 것은 아니고, 일반적으로 네트워크 자체의 표현력이 너무 커지기 때문에 일반적으로 Overfitting을 막기 위한 Regularization을 좀 걸어주는 편이다.
여기에 주로 사용되는 방법들도 기본적인 L1-penalty, L2-penalty, Early-stopping 외에도 다양한 방식이 개발되어 왔으며 아래에 소개할 방법들 외에도 Sharpness Aware Minimization, Mix-up, Adversarial training같은 비교적 최근에 제안된 방법도 존재한다.
Dropout
Dropout은 학습 중 임의로 특정 유닛들을 비활성화시키는 기법이다. 비활성화시킬 유닛의 수는 Dropout Probability에 의해 정해지며, 이는 Hyper-parameter이다. 모든 유닛들이 학습 중 저 확률에 의해 수시로 연결되었다 끊겼다 하는 것이다.
이 방식이 왜 Regularization 관점에서 효율적일까? 다양한 이유가 밝혀졌지만 여기에서는 아래의 2가지 이유를 소개한다.
유닛이 학습 중 수시로 활성화/비활성화 상태를 반복하면서 각 유닛별로 데이터셋에 존재하는 Spurious pattern을 학습할 기회를 놓치게 된다는 것이다. Overfitting은 모델의 표현력이 너무 높아서 데이터의 사소한 부분까지도 잡아내는 현상이라고 했었다. Dropout은 자주 연결이 비활성화되면서 그 사소한 부분까지 학습할 기회를 주지 않는 기법이라는 것이다.
Ensemble로 해석하는 관점이 있다. 즉, 학습 중 일부 유닛을 끊어버리면 그 순간은 미세하게나마 다른 모델이 형성되었다는 것이다. 이러한 미세하게 다른 모델이 상당수 형성된 상태가 되고, 추론을 할 때엔 Dropout을 적용하지 않으므로 이러한 모델들의 평균을 취하는, 즉 일종의 Bagging이 적용된 형태니까 학습이 더 잘 되는 효과를 누린다는 것이다.
Batch Normalization
일반적으로 데이터는 분포가 골고루 퍼져있는 상태가 학습 관점에서 가장 이상적이다. 만일 그렇지 않은 상태라면 이것은 특정 방향으로 데이터가 편중되어있다는 얘기가 되고, 그러면 학습하면서 이 편중까지 고려해야 하기 때문에 학습의 난이도가 굉장히 올라간다.
이를 해결하기 위해서는 데이터를 Normalization해줘야 한다. 그리고 딥러닝에서는 설령 원래의 데이터가 Normalizing이 되어있더라도 각각의 Layer를 거친 직후의 데이터가 Normalization이 된 상태라는 보장을 전혀 할 수 없다. 이는 곧 Hidden Layer는 Normalizing된 데이터를 보지 않는다는 얘기가 되고, 이는 곧 학습 효율의 저하를 야기한다.
이러한 상황을 방지하기 위해, Batch Normalization이라는 기법이 도입되었다. 이는 Layer 사이에 끼어들어가서 출력 Data를 Normalizing하는 역할을 한다. 이러면 이전 Layer가 어떤 식으로 분포를 형성하던 Batch Normalization Layer에서 이를 다시 골고루 펴주므로 다음 Layer에서 학습을 잘 수행할 수 있게 된다.