Deep Learning 4 - RNN
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Deep Learning 과목의 수업을 다룬다.
Recurrent Neural Networks
Recurrent Neural Networks, 즉 RNN은 입력 데이터의 순서가 정해져있거나 시간 순으로 들어오는 경우에 주로 사용되는 딥러닝 아키텍쳐다.
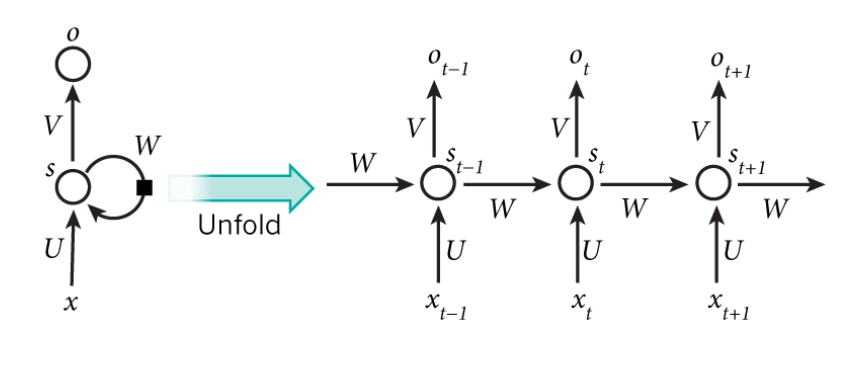
기본적인 RNN의 구조는 위와 같다. 기본적으로 Neural Network를 그래프로 그리면 Directed Acyclic Graph가 되는데, RNN의 경우는 왼쪽과 같이 루프가 생긴다. 다만 이 루프에 사각형 박스가 보이는데 이는 Time Delay를 의미한다. 즉, $W$를 거치는 쪽은 다음 단계에서 합쳐져서 되돌아온다고 생각하면 된다.
이는 왼쪽의 그래프를 시간을 기준으로 펼쳐놓은 오른쪽 그래프를 보면 더 명확하다. 즉, 이전 단계에서의 정보가 다음 단계로 전해져서 순서를 표현한다. 또 기본적인 Input/Output Layer에 해당하는 파라미터 $U$, $V$ 외에도 $W$라는 파라미터가 하나 더 있어서, 이 $W$를 타고 다음 단계로 정보가 전달된다. 이렇게 다음 단계로 전달되는 Vector를 State Vector $h_t$라고 부른다.
CNN의 Kernel과 유사하게 모든 단계에서 파라미터 $W$에 동일한 값을 사용한다는 점이 중요한데, 그렇기 때문에 시간순으로 데이터가 흐르면서 State Vector는 이전 단계까지의 데이터가 모두 반영되어 있다. 이는 마치 과거의 기록을 기억하는 것과 유사한 효과가 나오기 때문에 State Vector를 “Encoded Memory”라고도 부른다.
Process Sequences
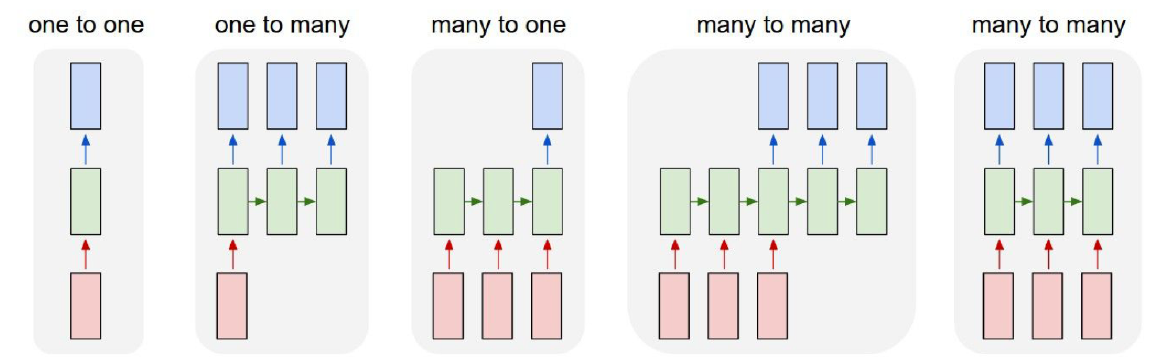
이 시간순으로 데이터가 흐른다는 점은 또 다른 장점을 야기한다. 일반적인 Neural Network들은 가장 왼쪽의 1-to-1과 같은 형태만 가능하다. 즉, 입력 사이즈나 내부 구조와는 상관없이 결국 입력 하나에 출력 하나를 만들어낸다. 그러나 RNN은 1-to-1 뿐만 아니라 굉장히 다양한 형태의 문제를 처리할 수 있다.
1-to-Many 케이스는 입력을 하나만 주는데 그걸로 Sequential한 출력이 생성되어야 하는 문제다. 대표적인 것이 Image Captioning이다. 주어진 입력 이미지 1장을 바탕으로 이를 설명하는 문장을 리턴하는 것이다. 참고로 문장은 하나의 데이터가 아니라 Word의 Sequence기 때문에 출력을 여러개로 표현해야 한다.
반대로 Many-to-1 케이스는 Sentiment Classification 문제가 대표적이다. 이는 소위 말하는 감정 분석 문제로, 주어진 문장이 의미하는 뉘앙스, 긍정/부정 등을 찾는 문제다. 역시 문장이 Word의 Sequence라 여러 데이터가 들어오는 형태고, 출력값은 단어 하나기 때문에 Many-to-1에 해당한다.
Many-to-Many 케이스는 두 가지 형태가 존재한다. 첫 번째 형태는 첫 출력이 첫 입력에 비해 어느 정도 Delay된 상태, 즉 앞의 입력 몇개를 보고 나서야 출력이 생성될 수 있는 문제다. 이러한 문제의 대표적인 예시는 Translation이다. 단어 하나만 들어온 시점에선 즉시 번역하는 것이 불가능하기 때문에 위와 같은 형태의 그래프가 형성된다.
두 번째 케이스는 위와는 반대로 첫 입력에서부터 바로 첫 출력이 도출되는 문제로, 대표적인 것이 음성 인식, 혹은 Frame 수준에서의 Video Classification 등이 해당된다.
Mathematical Details
그럼 이제 RNN을 수식으로 접근해보자.
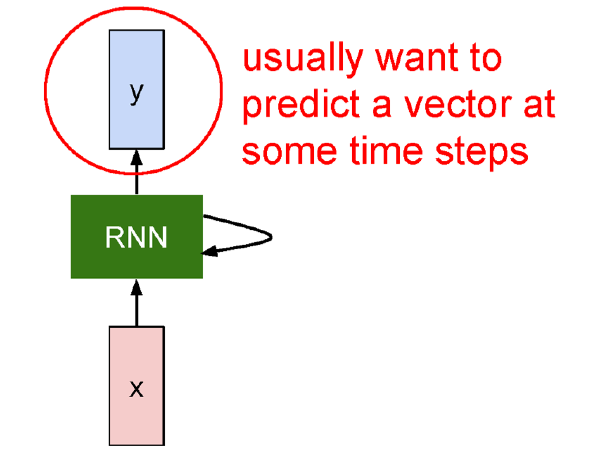
RNN에서는 보통 입력을 $x$, 출력을 $y$로 표기한다. 그리고 RNN 자체가 시간에 따른 State 기반으로 이루어지기 때문에, 어떤 순간 $t$에서의 Hidden State $h_t$는 다음과 같이 표기된다.
$h_t=f_W(h_{t-1}, x_t)$
즉 현재 단계의 Hidden State는 이전 단계의 Hidden State로부터 결정된다. 그리고 $W$가 RNN 전체에 대해서 공유되는 값이기 때문에, 당연히 $f_W$도 RNN 전체에 걸쳐서 모두 동일한 함수가 된다.
또한 RNN도 Neural Network인만큼 Activation Function을 사용하는데, CNN과는 달리 RNN에서는 ReLU 계열이 아닌 $\tanh$를 주로 사용한다. 이는 크게 두 가지 이유가 있는데, 첫 번째로 $\tanh$가 $(-1, 1)$의 출력 범위를 가져서 같은 파라미터 $W_{hh}$를 시간의 흐름에 따라 무한히 곱해나가는 RNN에서 Hidden State의 크기를 계속 유지시킬 수 있기 때문이다. ReLU는 출력 범위가 [0, $\infty$]라서 같은 조건에서 Hidden State가 발산해버릴 위험이 있다. 또한 ReLU와 같이 음수 값을 없애버리게 되면 제대로 동작하지 않는다는 실험적인 결과도 존재한다.
물론 그렇다고 ReLU가 이론적으로 불가능하지는 않으며 실제로 ReLU RNN을 시도하기도 했다. 다만 초기화 값을 잘 선택해야 하므로 여전히 일반적인 선택은 아니긴 하다.
그래서 별도의 변형이 없는, “Vanilla RNN”이라면 Hidden Vector $h$와 출력값 $y$는 다음과 같이 정의할 수 있다.
\[h_t=\tanh(W_{hh}h_{t-1}+W_{xh}x_t), y_t=W_{hy}h_t\]여기서 $W_{ab}$는 a로부터 b를 만들기 위해 곱해지는 파라미터를 의미한다. 즉 $W_{hh}$는 Hidden -> Hidden을, $W_{xh}$는 Input -> Hidden을, 그리고 $W_{hy}$는 Hidden -> Output 변환을 담당한다. 물론 위에서 본 Process Sequence에서 알 수 있듯이, $h_t$는 매 단계마다 전부 계산해야 하지만 $y_t$를 모두 계산할 필요는 없다. 문제의 성격에 따라 필요한 경우에만 $y_t$를 계산해서 출력을 얻어내면 된다. 그리고 제일 첫 단계에선 “이전 State”라는 개념 자체가 없으므로 초기값 $h_0$를 정해서 그 값을 대신 넣는다.
Bi-directional RNN
지금까지 본 RNN은 단방향으로 수행된다. 그런데 데이터를 역순으로 봐도 RNN에서 가정하는 데이터의 특성은 그대로 유지된다.
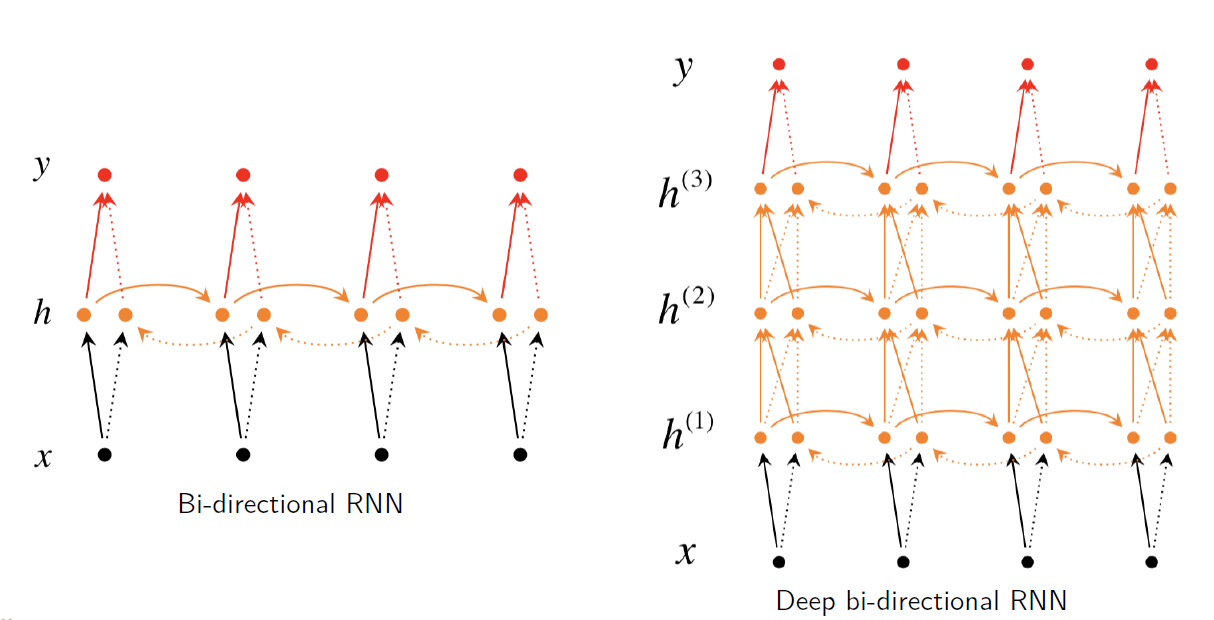
그렇기 때문에 위와 같은 Bi-directional RNN을 생각해볼 수 있다. 이 경우엔 역순으로도 데이터를 처리하기 때문에, 특정 중간 시점에서의 결과를 양쪽 방향 모두 확인하고 내릴 수 있다.
우측의 경우는 Bi-directional RNN을 좀 깊게 쌓은 형태인데, RNN은 Layer를 깊게 쌓기 어려워서 3개 이상으론 잘 쌓지 않는 편이다. 이는 시간에 따라 펼쳐지는 수평적 Layer가 이미 깊게 쌓여있기 때문으로, 실질적으론 (수직적 Layer) * (수평적 Layer)의 깊이를 가져 이미 상당히 깊은 네트워크를 형성하고 있다.
Computational Graph
위에서 논의한 내용을 바탕으로 RNN에 대한 Computational Graph를 몇 종류 살펴보자.
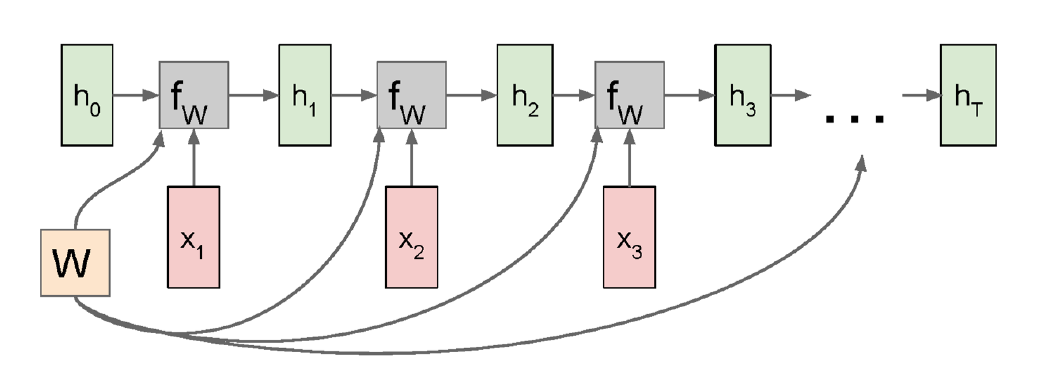
출력 $y_i$를 배제한 일반적인 Computational Graph의 형태는 위와 같다. 역시 $W$는 모든 단계에서 공유된다.
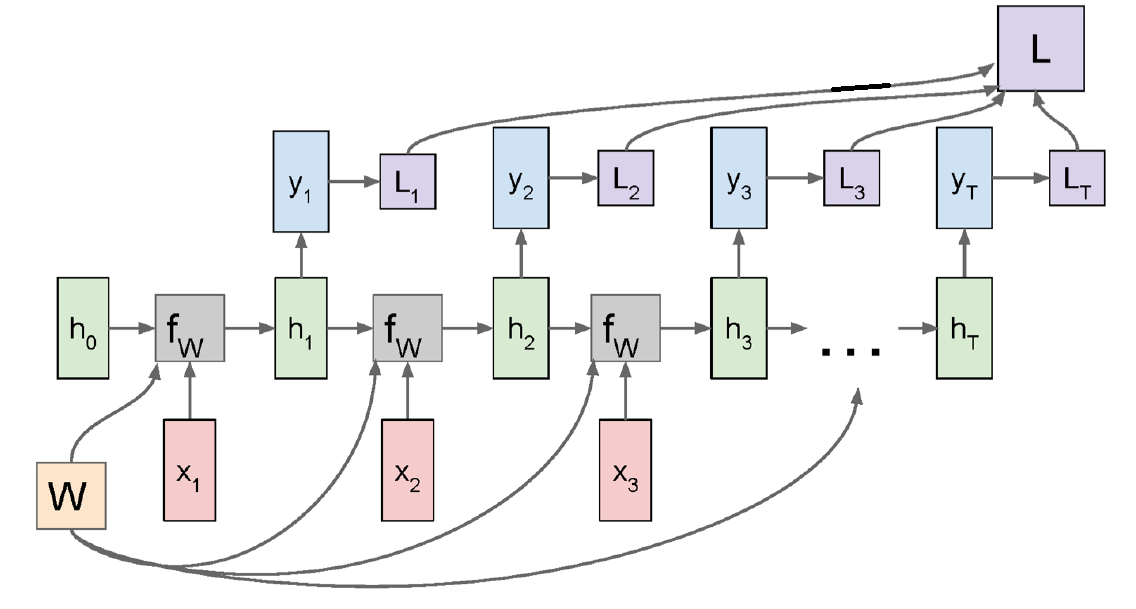
그런데 Loss는 출력 $y_i$가 나와야 계산이 가능하다. 그리고 Many-to-Many 케이스에서는 출력이 여러 단계로 나뉘어 있으므로, 각각의 출력 $y_i$로부터 계산된 Loss $L_i$를 모두 합친 $L$이 이 Neural Network의 최종 Loss가 된다.
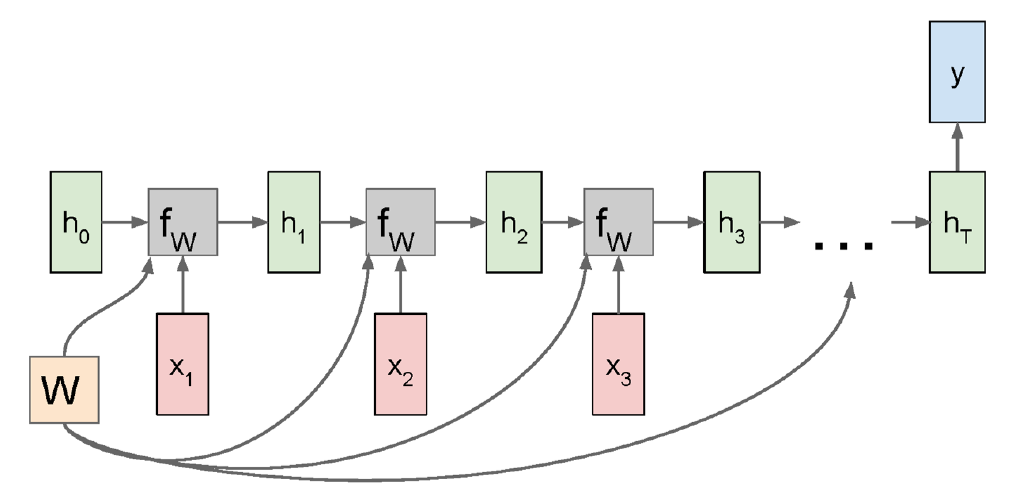
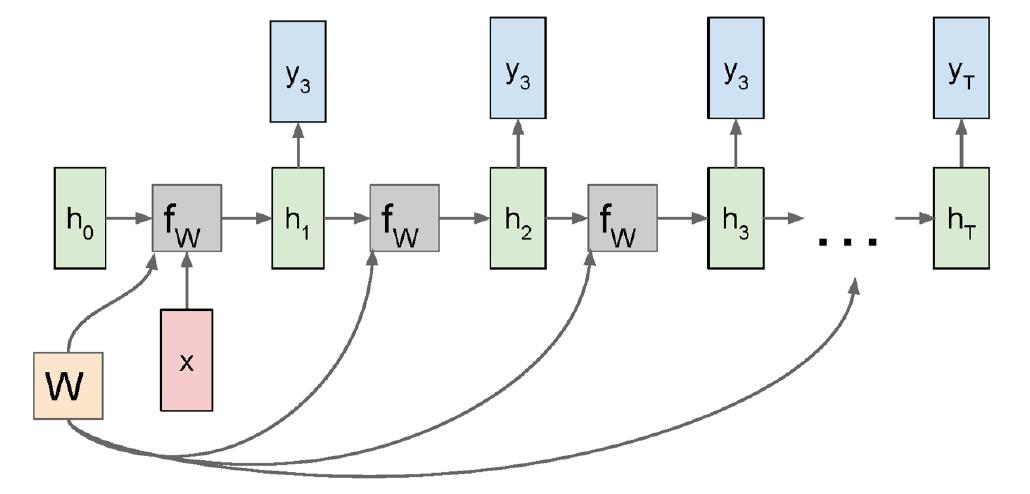
Many-to-1, 혹은 1-to-Many의 경우에도 Computational Graph가 크게 달라지진 않는다. 다만 Many-to-1의 경우는 출력이 $y$ 하나뿐이므로 $y$로부터 계산된 Loss $L$이 곧 전체 Loss와 동일하다.
다만 실제로는 각 단계별로 출력하는 값은 많은 경우 단어가 되기 때문에, 이는 Multi-class Classification 문제가 된다. 이 경우엔 각 단어의 확률을 계산한 Softmax 함수가 Output Layer 다음에 위치하게 된다. 또한 추론할 때는 일반적으로 Softmax로 계산한 최댓값을 출력하는 것이 아니라, 그 확률대로 샘플링을 해서 뽑아낸다.
Training
그럼 이 RNN을 어떻게 훈련시킬 수 있는지 알아보자. RNN에는 다양한 입/출력 구조가 있지만, 여기서는 아래와 같은 상황을 기준으로 삼는다.
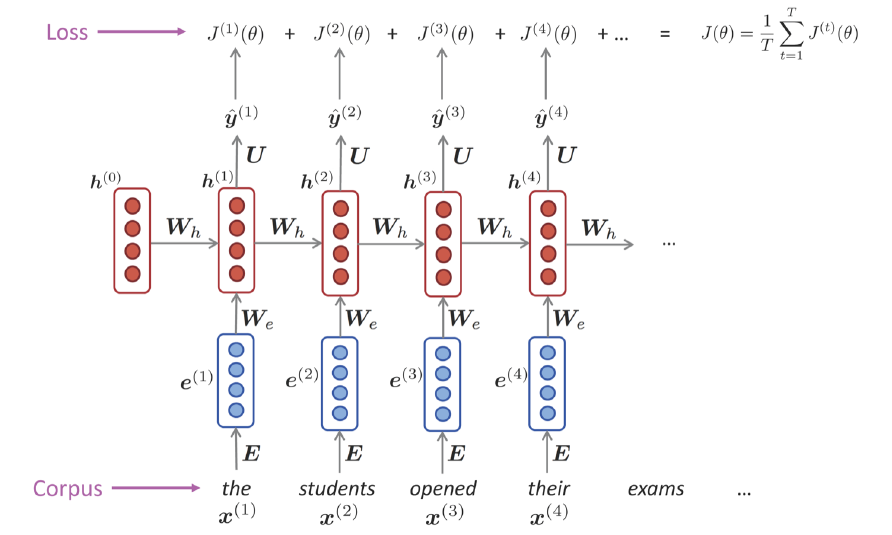
즉, 초기 State $h^{(0)}$을 기반으로 문장을 쭉 생성하는 문제다. 이 경우엔 이전 단계의 Output이 곧 다음 단계의 Input이 된다. 이러한 구조를 Auto Regressive라고 부른다. 여하튼 Loss를 계산하는 과정 자체는 크게 다를 것이 없다. 위의 상황에서는 각 단계별로 나왔어야 하는 답을 이미 알고 있기에 그와 비교해서 각 단계별 Loss를 계산할 수 있다.
그러나 학습은 단계별로 이루어지진 않는다. 역시 모든 단계에서 파라미터 $W_h$가 공유되기 때문으로, 따라서 각 단계별로 계산한 Loss의 산술평균을 구한다.
\[\dfrac{\partial J^{(t)}}{\partial W_h}=\left.\sum_{i=1}^{t}\dfrac{\partial J^{(t)}}{\partial W_h}\right\vert_{(i)}\]그렇게 되면 위와 같이 Gradient도 합으로 분리가 가능해진다. 이러한 알고리즘을 “Backpropagation through time”, 즉 BPTT라고 부른다.
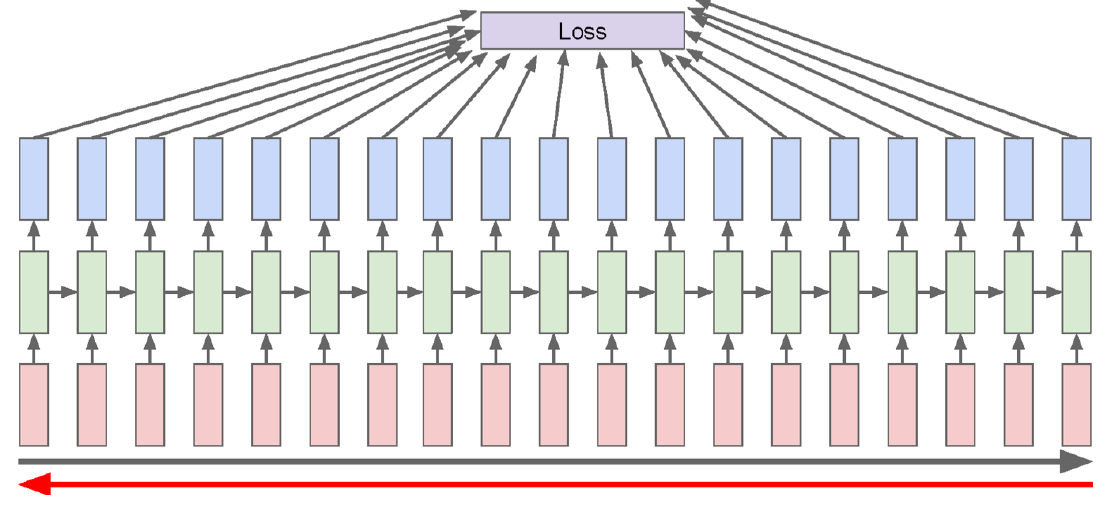
모든 단계별로 전부 이 Loss에 대한 어느 정도의 책임이 존재한다. 따라서 위와 같이 그 모든 단계에 대해서 Backpropagation을 수행해야 한다. 그런데 이 과정은 상당히 오래 걸린다.
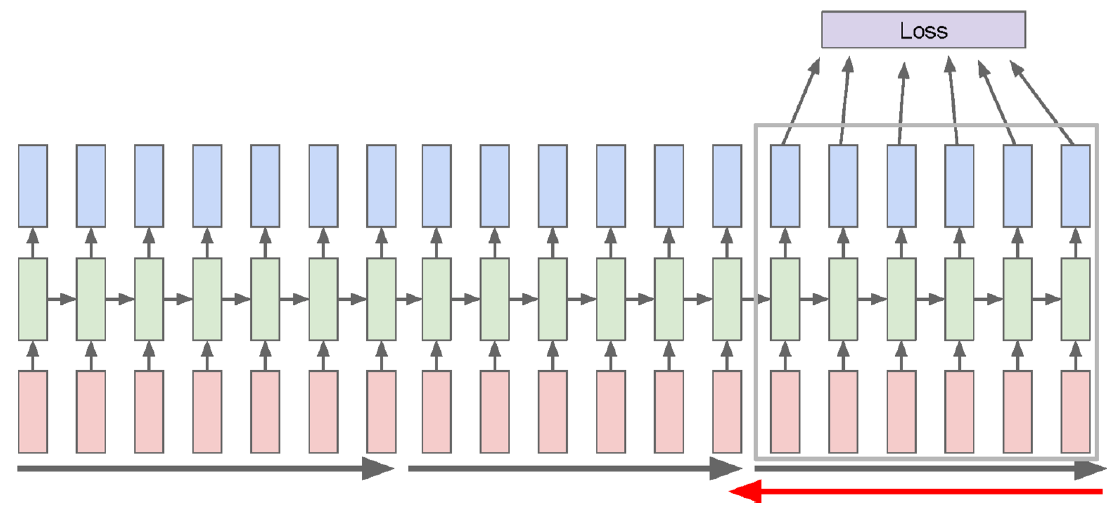
이것이 RNN의 단점 중 하나인데, 이를 해결하기 위한 방법 중 하나로 Truncated BPTT라는 것이 존재한다. 위의 거대한 RNN을 한꺼번에 하지 말고, 특정 길이만큼 잘라서 학습시키는 것이다. 이렇게 잘려진 부분을 먼저 업데이트한 후, 그걸 기반으로 다음 부분을 업데이트하는 식으로 학습하는 것이다.
여담으로, 이 RNN의 학습 방법은 상당히 비효율적이다. 대표적으로 위의 구조에서 유추가 가능하듯이 GPU를 사용함에도 시간축 방향으로는 병렬 연산이 불가능하다. 또한 위에서 학습을 시킬 때 학습률에 $t$에 대한 가중치를 줘서, 어느 시점의 데이터에 더 높은 가중치를 줄지 정할 수는 있다. 그러나 일반적으론 잘 사용되지 않는데, 그러한 가중치가 없어도 결국 의도한 대로 학습이 잘 되기 때문이다.
Examples
그럼 이 RNN을 가지고 실제로 어떤 식으로 써먹을 수 있을지 몇 가지 예시를 알아보자. 우선, 데이터에 순서가 정해져 있다는 그 특성이 가장 잘 발휘되는 곳이 어디일까? 바로 언어다. 그렇기 때문에 RNN으론 주로 대화나 문서를 생성하는 쪽의 연구가 이루어졌다. 물론 코드 또한 자연어가 아닐 뿐 RNN에서 가정하는 데이터의 특성이 잘 반영되어 있다. 그렇기 때문에 RNN으로 그럴싸한 코드를 생성하는 것도 가능하다.

또한 이는 위와 같은 문학작품에도 적용된다. 위의 모델은 Shakespeare의 Sonnet(영시의 정형시)를 학습시킨 결과인데, 학습이 진행될수록 점점 그럴싸한 문장들이 나오는 것을 확인할 수 있다.
데이터 생성 외에도 RNN을 활용하는 예시들은 다음과 같다.
Part-of-speech Tagging
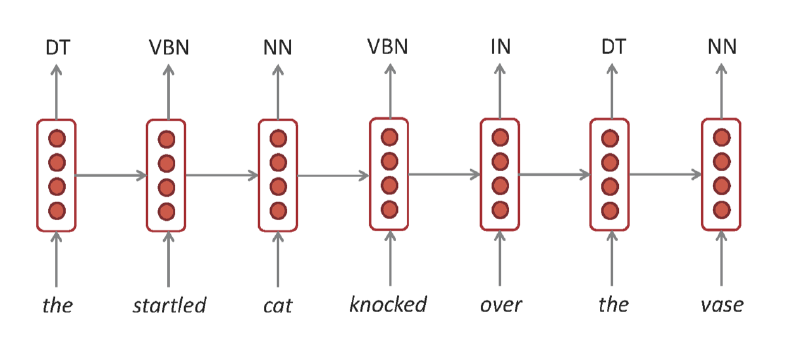
문장의 각 단어별로 문법적인 기능을 분석하는 모델이다. 당연하지만 Many-to-Many고, 그 중에서도 즉각적으로 출력하기 시작하는 부류다.
Sentiment Classification
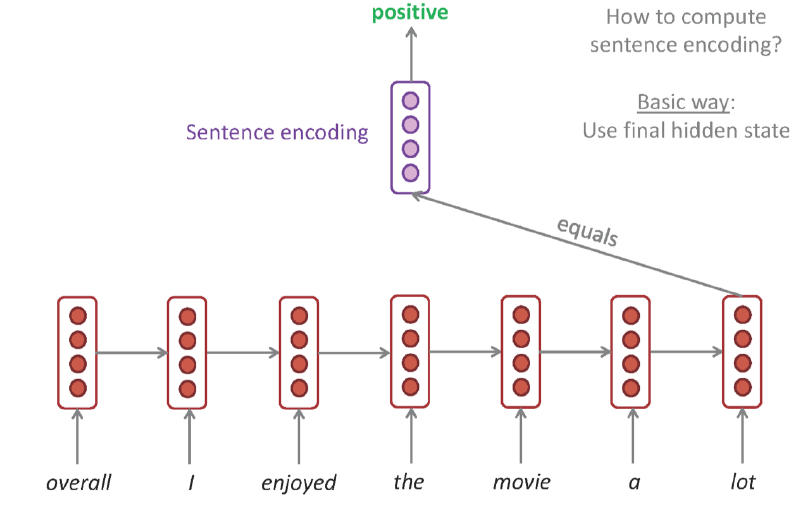
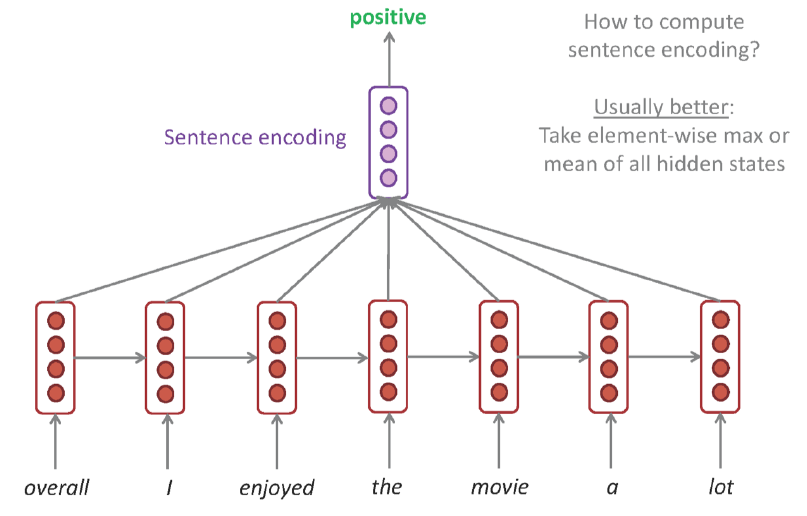
Sentiment Classification 문제는 위와 같이 두가지 방식으로 구현할 수 있다. 그러나 일반적으론 마지막 Hidden State에서 얻은 결론만을 내는 첫번째 방법보단 모든 Hidden State의 출력값을 취합하는 방식이 대체로 더 나은 편이다.
Speech Recognition
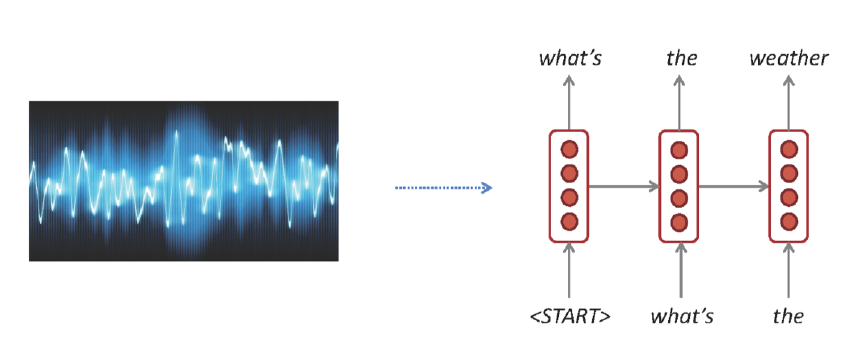
음성을 텍스트로 바꾸는 모델이다. 이 경우엔 시작 지점에 “
Question Answering
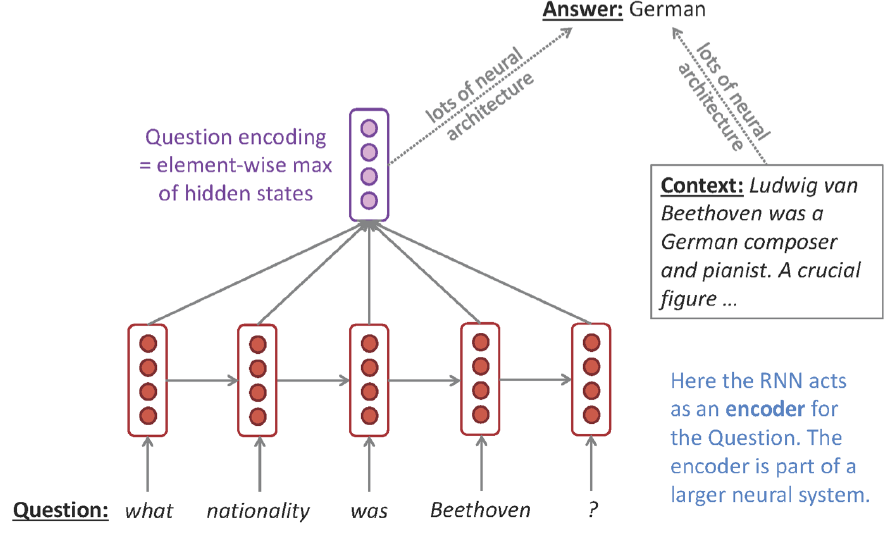
말 그대로 질문을 던져주면 그에 대한 답을 생성하는 모델이다. 위의 예시는 가장 간단한 형태로써, 질문도 Sequential하게 모델링하고, 예상 답안지도 Sequential하게 모델링하여 “이 질문을 받으면 이 답을 생성해라”라는 식으로 학습시킨 것이다.
Image Captioning
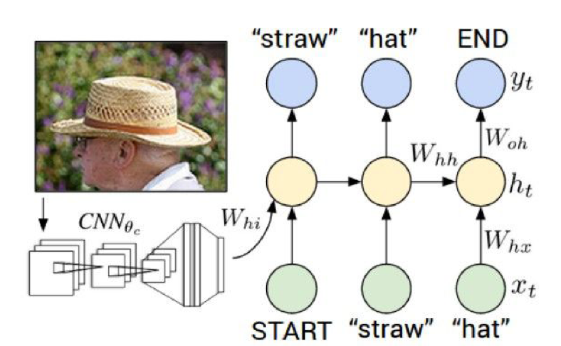
이미지를 입력으로 줘서, 이를 설명하는 짧은 문구를 생성하게 하는 모델이다. 이미지는 공간적인 구조를 가져서 RNN에서 가정하는 데이터의 형태와 잘 맞지 않기 때문에, 위 그림과 같이 CNN도 필요하다. 즉, CNN으로 분석한 결과는 이 이미지의 특성을 충분히 파악한 정보가 되고, 그 벡터를 RNN의 Initial State Vector로 넣는 것이다.
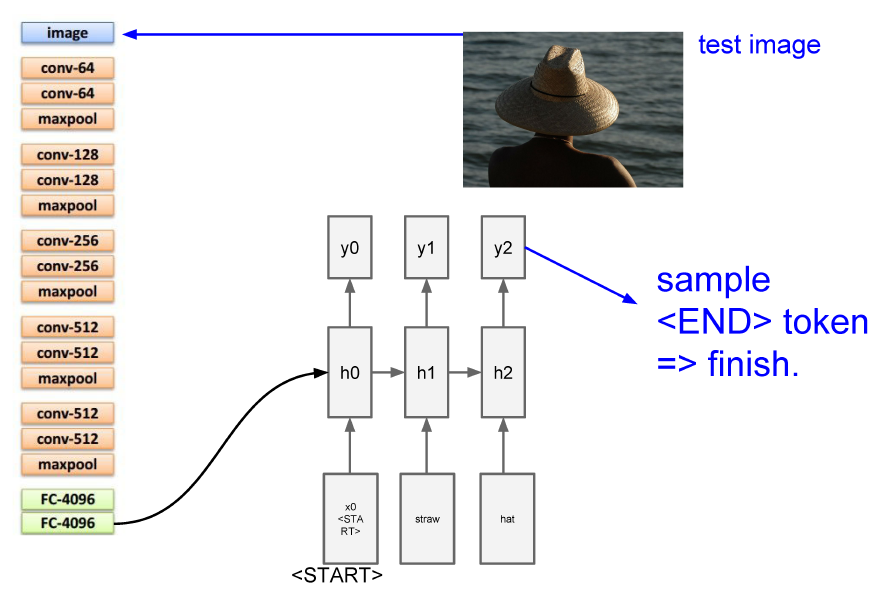
위의 그림은 CNN을 사용하는 아이디어를 좀 더 구체화시킨 모델이다. 이미지를 받아 통과시키는 모델은 VGGNet이다. 실제 VGGNet에 비해서 마지막 2개의 Layer가 빠진 형태인데, VGGNet에서 이 마지막 2개의 Layer는 Classification을 위한 Softmax와 그 직전의 Classification을 위한 Layer이기 때문이다. Classification에 특화된 이들 Layer들을 버리고, 이미지에 대한 정보를 가장 잘 가지고 있을 그 바로 직전의 Layer를 취해서 이를 Initial State Vector로 삼아 RNN을 돌리면 된다.
Interpretable Cells
이건 사실 RNN의 활용법보다는 Hidden State Vector에선 무슨 일이 벌어지는가를 확인한 연구에 가깝다. 아래의 사진들에서 빨간색 영역은 Positive, 파란색 영역은 Negative이다. 즉, 각각의 Cell에서 어떤 값에 반응했는지를 보여준다.






위의 결과들은 각각 Parenthesis, Quote, Line length, If-statement, Comment, Code depth에 반응하는 Cell들이다. 즉, 이런 식으로 학습하라고 알려주지도 않았음에도 RNN 내부적으로 각각의 Cell들이 각자 서로 다른 특정한 신호에만 반응한다는 것이다.
DNN vs CNN vs RNN
마지막으로 여태까지 배운 DNN, CNN, 그리고 RNN을 비교해보자.
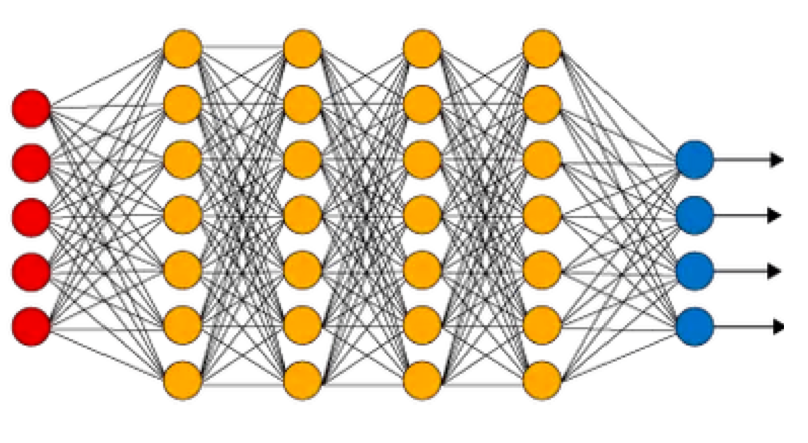
DNN은 입력 데이터에 대해 별다른 사전 지식을 가정하지 않는다. 그로 인해 입력 데이터를 Vector의 형태로 쭉 펼친 후, 각 Layer마다 모든 유닛들이 이 Vector를 전부 보면서 학습한다. 다만 같은 Layer 내의 각 유닛들은 전부 개별적으로 규칙을 습득하고, 이 유닛들이 각자 습득한 정보를 종합해서 최종적인 결과가 나온다.
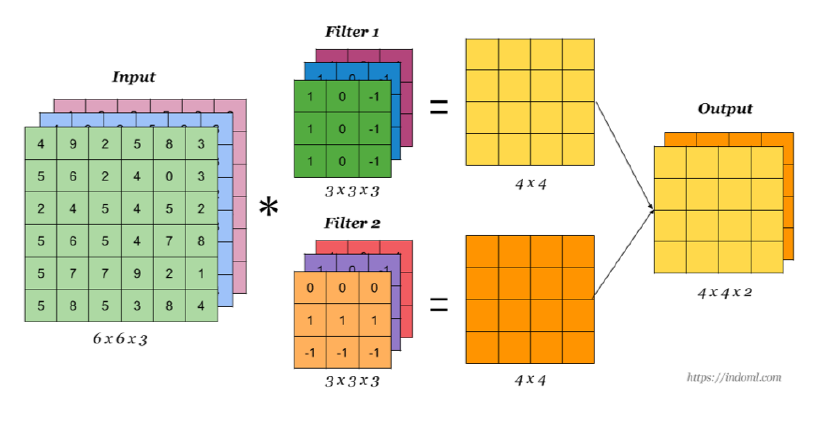
그러나 Structured Data가 주어진다는 가정이 존재한다면 어떨까? 이러한 형태의 데이터에서는 인접한 위치의 데이터는 강한 상관관계를 갖고 있기 때문에 이러한 구조를 유지하는 것이 학습에 유리하다. 그러나 DNN으로 학습시키려면 Vector로 바꾸는 정에서 이러한 “인접”에 대한 정보가 소실되기 때문에 DNN으로는 부적절하다.
이런 경우에는 DNN 대신 CNN을 사용하며, 이 CNN은 기본적으로 로컬 패턴을 찾는데 주력한다. 그로 인해 Kernel을 사용하며, 로컬 패턴을 찾기 위해 이 Kernel은 한 Feature 내에서 전부 동일한 값을 사용하며, 이를 모든 공간에 Sliding하면서 적용한다.
RNN은 CNN과는 다르게 시간을 기준으로 하는 데이터들을 다룬다. 데이터가 시간의 흐름에 따라 순차적으로 들어오는 경우, 혹은 데이터 자체에 순서가 있어서 앞에서부터 하나씩 봐야 하는 경우에 사용하며, CNN과 유사하게 이 시간축별로 동일한 파라미터를 공유한다.
그리고 순차적인 데이터를 다룬다는 특성상 입력 데이터의 크기가 유동적이어도 아무 문제 없이 처리가 가능하다. DNN이나 CNN의 경우 데이터의 크기가 고정되어야 한다. 그러나 RNN의 경우 한 단계당 들어올 데이터의 크기는 고정되지만 전체적으로 몇 단계나 수행할지는 유동적으로 정할 수 있다. 이 역시 시간축별로 동일한 파라미터를 공유하기 때문에 생기는 강점이다.