Deep Learning 5 - LSTM & GRU
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Deep Learning 과목의 수업을 다룬다.
Problems of RNN
저번 글에서 RNN에 대해 알아봤었다. 그러나 RNN 자체에는 몇 가지 치명적인 문제들이 있어서, 그 형태 그대로인 Vanilla RNN는 거의 쓰이지 않는다.
Vanishing/Exploding Gradient Problem
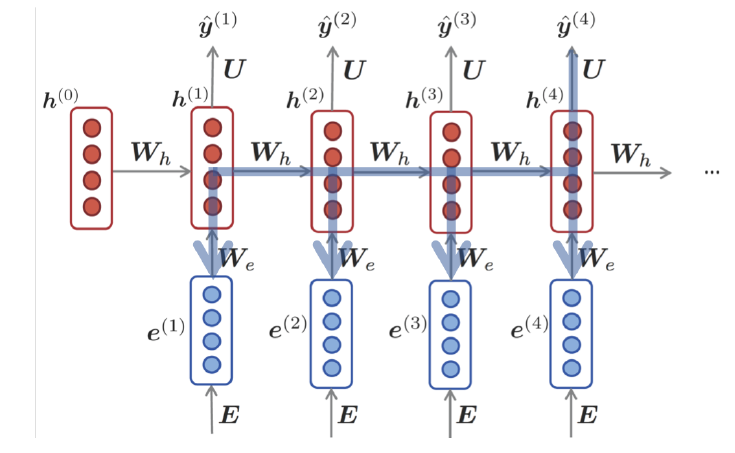
RNN의 일반적인 구조는 위와 같다. 여기서 가중치 행렬 $W_h$가 모든 단계에서 공유된다는 점이 중요하다. 이 점은 RNN의 특징이자 장점이기도 하지만, 그와 동시에 다양한 문제를 야기하는 Vanilla RNN의 단점이기도 하다.
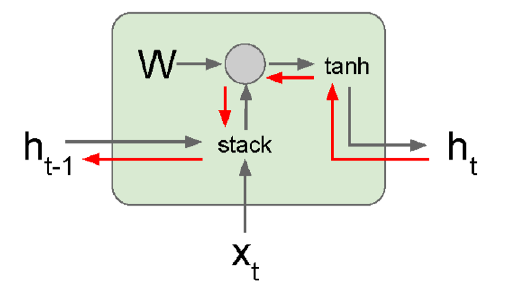
우선 Vanilla RNN의 각 단계를 위와 같이 표현해보자. 여기서 검은색 화살표는 추론 흐름을, 빨간색 화살표는 학습 흐름을 나타낸다. 위의 그림에서 “stack”은 별 의미가 있는건 아니고 그냥 두 방향에서 온 데이터를 합한다는 의미이다. 즉, 들어오는 데이터는 $t$ 시점의 입력값 $x_t$와 그동안 기억한 Hidden State $h_{t-1}$이고, 이것들과 공유되는 파라미터 $W$를 곱한 값에 $\tanh$를 취해서 다음 단계의 Hidden State $h_t$를 리턴한다. 그리고 Back Propagation은 위의 과정을 역으로 진행하면 된다.
여기까지 보면 이상할게 없지만, 모든 단계에서 $W$가 전부 같은 값이라는게 문제가 된다. 위의 과정을 여러번 반복하다보면 $W$의 eigenvalue가 1보다 크면 Back Propagation을 거치면서 Gradient가 무한대로 발산하게 되고, 반대로 eigenvalue가 1보다 작으면 Back Propagation을 거치면서 Gradient가 0으로 수렴하게 된다. 즉 저 구조 때문에 Exploding Gradient와 Vanishing Gradient를 모두 겪을 수 있다.
그나마 다행히도, Exploding Gradient 문제는 Gradient Clipping이라는 기법을 통해 간단하게 해결할 수 있다.
1
2
3
grad_norm = np.sqrt(np.sum(grad * grad))
if grad_norm > threshold:
grad *= (threshold / grad_norm)
정확히 위의 코드와 유사한 작업을 하면 된다. 즉, 적당한 Threshold를 정한 후, Gradient가 Threshold보다 크면 그 비율대로 나눠서 강제로 Gradient의 크기를 줄이면 된다.
그러나 Vanishing Gradient 문제는 이런 간단한 방법으로 해결할 수 없다. 근본적으로 0에 수렴하는 상황이라면 아무리 특정 배수만큼 곱한다 한들 그 상황 자체가 해결되는 것이 아니기 때문이다. 그렇기 때문에 Vanilla RNN의 구조로는 해결이 불가능하고, RNN의 단점을 보완할 아키텍쳐를 설계해야만 한다.
Long Dependency Problem
Vanilla RNN에는 Gradient 문제 말고도 다른 문제가 하나 더 있다. RNN은 기본적으로 시간의 흐름에 따라 데이터를 다룬다. 그리고 데이터 및 도메인에 따라 어떤 경우에는 가까운 과거를 참조해야 하는 경우가 있고, 좀 먼 과거의 데이터를 참조해야 하는 경우도 있다. 여기서 전자를 Short-term Dependency, 후자를 Long-term Dependency라고 부른다.
그런데 Vanilla RNN에서는 과거로부터 이어진 모든 데이터는 Hidden State에서 전부 인코딩되어 있다. 이러한 특성상 시간이 지날수록 옛날의 일에 대한 정보까지 다 담기는 부족한 경우가 생긴다. 그렇다고 Hidden State의 크기나 깊이를 늘리면 이는 곧 파라미터 개수의 증가로 이어지므로 쉽게 선택할 수 없다. 이러한 문제를 Long Dependency Problem이라고 한다.
이 문제 또한 Hidden State가 모든 부담을 지게 만드는 Vanilla RNN의 구조 내에선 간단하게 해결할만한 방법이 딱히 존재하지 않아 새로운 아키텍쳐를 설계해야 한다.
Long Short-Term Memory
위의 두 문제를 해결하기 위한 첫 시도가 Long Short-Term Memory(LSTM) [Hochreiter & Schmidhuber, 1997]이다.
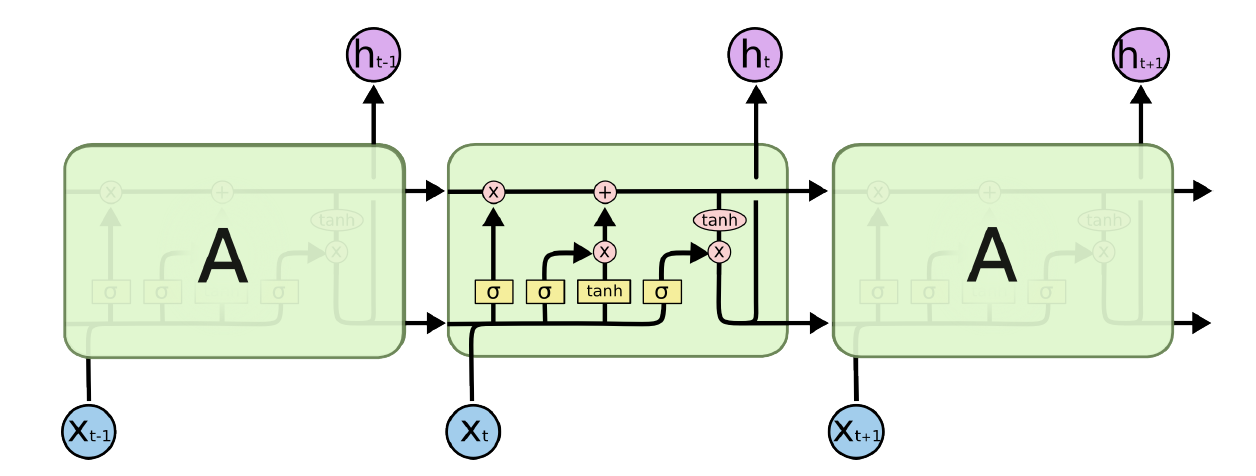
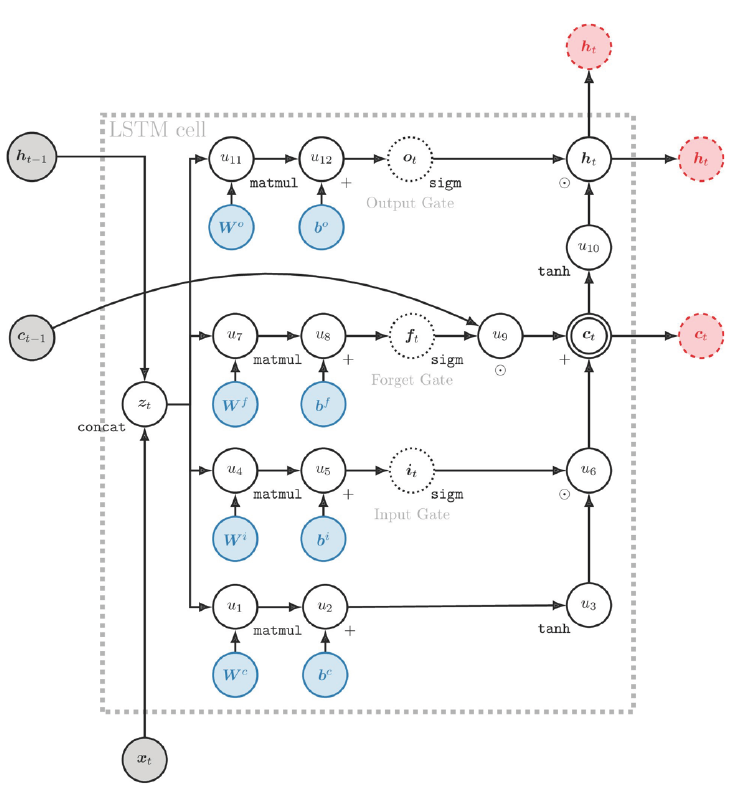
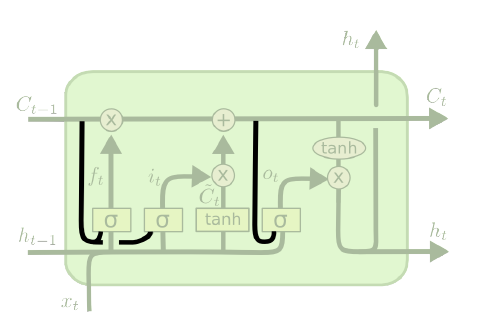
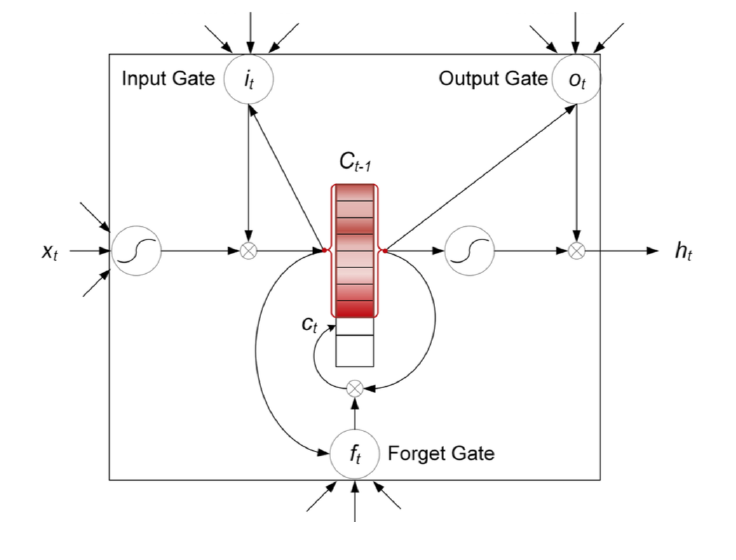
LSTM에서 유닛 하나의 구조는 위 사진과 같다. RNN에 비해 뭔가 많이 추가된 모습을 볼 수 있다. 여기서 $\sigma$는 Sigmoid 함수를 의미한다. Sigmoid 함수는 0~1로 떨어지기 때문에 특정 정보를 반영할 비율을 결정하는 역할을 한다. 그리고 이게 일종의 수문장 역할을 하기 때문에 “Gate”라고 부른다.
그럼 이제 LSTM의 구조를 하나씩 살펴보자.
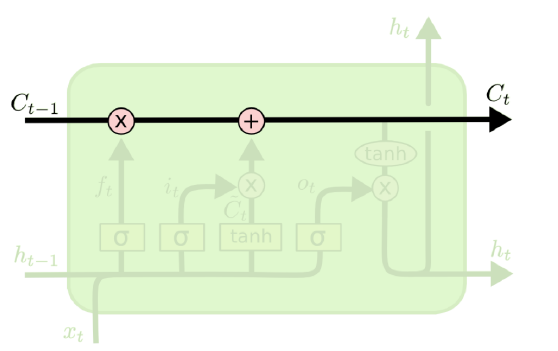
우선 Hidden State 외에도 각 유닛을 가로지르는 다른 State가 존재함을 알 수 있다. 이를 Cell State $C_t$라고 부른다. 이것이 Vanilla RNN과의 가장 큰 차이점으로, 과거의 데이터들 중 어떤 것을 지우고 어떤 것을 유지할지에 대한 정보를 담고 있다. 이 Cell State는 후술할 Gate들에 의해 관리된다.
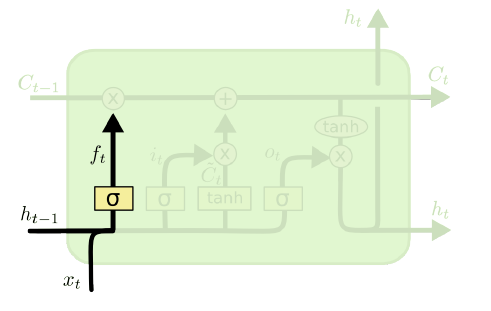
우선 Unit 구조도에서 가장 왼쪽에 있는 이 녀석을 Forget Gate $f_t$라고 부른다. 이번 단계의 Cell State $C_t$를 계산할 때 저번 단계의 Cell State $C_{t-1}$을 얼마나 반영할지를 결정하는 Gate로, 아래와 같이 계산된다.
\[f_t=\sigma(W_f\cdot[h_{t-1},x_t]+b_f)\]여기서 $W_f$와 $b_f$는 Forget Gate의 파라미터 및 Bias이다.
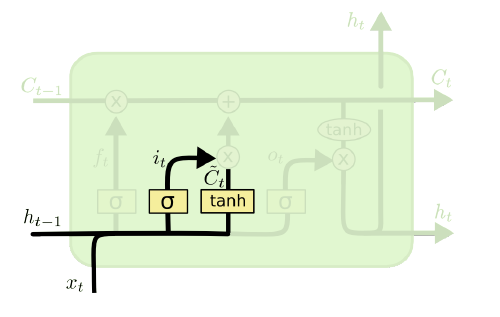
다음으로 마주하게 되는 것은 Input Gate $i_t$이다. 여기서는 위와는 반대로 이번 단계에 새로 들어온 정보 $x_t$를 얼마나 Cell State에 저장할지를 결정하는 Gate로, 다음과 같이 두 단계에 걸쳐서 계산된다.
\[\begin{aligned} i_t&=\sigma(W_i\cdot[h_{t-1},x_t]+b_i) \\ \tilde{C_t}&=\tanh(W_C\cdot[h_{t-1},x_t]+b_C) \end{aligned}\]여기선 추가적인 변수 $\tilde{C_t}$가 등장하는데, Input Gate 자체는 비율만 결정하고 실제로 어떤 데이터를 반영할 것인가를 Candidate Value $\tilde{C_t}$로 계산한다. 이 값은 Sigmoid가 아니라 $\tanh$로 계산하는데, 이는 $\tanh$는 스케일이 $[-1,1]$이기 때문이다. 즉, 정보량을 빼버리는 경우까지도 고려한 함수 선택이라고 볼 수 있다.
Forget Gate에서의 $W_f$, $b_f$와 마찬가지로, 여기서 등장하는 각 파라미터 및 Bias들은 각각 Input Gate나 Candidate value의 파라미터 및 Bias이다.
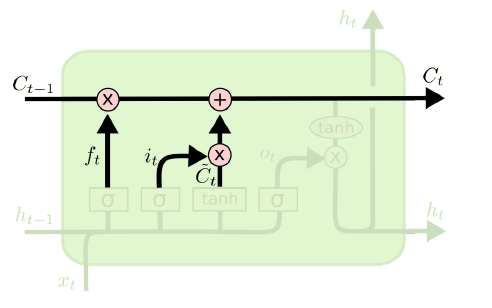
이렇게 얻은 정보들을 취합해서 Cell State $C_t$에 반영한다. 반영하는 방식은 아래와 같다.
\[C_t=f_t\ast C_{t-1} + i_t\ast\tilde{C_t}\]각 Gate 및 Candidate Value의 의미가 그대로 반영되었다.
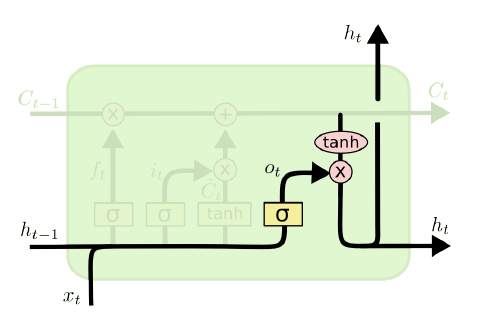
이렇게 Cell State를 업데이트시키면, 이제 이걸 바탕으로 Hidden State $h_t$를 구해야 한다. 이는 다음과 같이 계산된다.
\[\begin{aligned} o_t&=\sigma(W_o\cdot[h_{t-1},x_t]+b_o) \\ h_t&=o_t\ast\tanh(C_t) \end{aligned}\]위 식을 보면, 추가적인 변수 $o_t$가 등장했다. 이는 Output Gate라고 부르며, 현재 단계의 Cell State $C_t$를 얼마나 Hidden State에 반영할지를 결정한다. 이렇게 Hidden State를 구했으면 그 다음은 Vanilla RNN과 동일하다.
LSTM의 구조를 보면, Cell State가 상당히 중요한 위치를 차지하고 있음을 알 수 있다. 그렇기 때문에 이 Cell State를 분석하면 어느 시점에 정보들을 지웠고 어느 시점에 누적하는지 등의 네트워크의 움직임을 분석할 수 있다.
위 그림은 LSTM의 구조를 다르게 표현한 것이다.
그러면 LSTM은 Vanilla RNN이 갖고 있는 문제를 어떻게 해결했을까?
우선 Long Dependency Problem의 경우, Cell State를 도입함으로써 자연스럽게 해결되었다. 각 단계별로 과거 정보를 얼마나 반영할지를 따로따로 관리하기 때문에 Short-term Dependency나 Long-term Dependency 모두 커버가 가능하다.
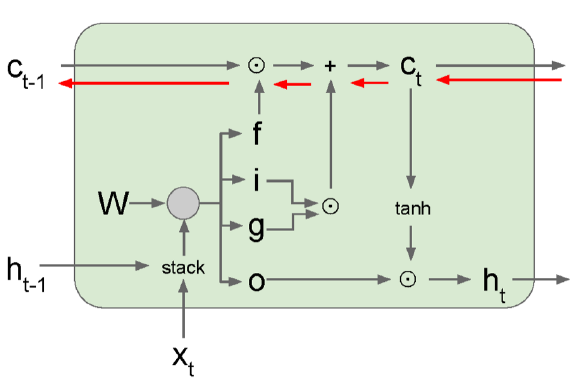
Gradient 관점에서 생각해보면 어떨까? 위 그림은 LSTM의 유닛을 간단하게 표현한건데, Back Propagation을 위해선 저 화살표들의 역방향으로 Gradient가 흘러야 한다. 그런데 잘 보면, Cell State를 통과하는 화살표는 위에 일종의 Short-cut이 생겼음을 확인할 수 있다.
이것은 곧 ResNet에서의 Gradient Shortcut과 유사한 역할을 하게 된다. Gradient가 보존되는 이유도 ResNet과 동일하다. 즉, 저 부분은 덧셈과 $\ast$ 연산만 사용하기 때문에 이것이 Gradient를 계산할 때 Shortcut 역할을 해서 Gradient가 잘 흐를 수 있게 해준다.
Variants
위에서 알아본 형태는 가장 기본적인 LSTM, 즉 Vanilla LSTM이라고 할 수 있다. 그런데 LSTM 자체가 역사가 오래된 만큼 이걸 더 개선하기 위한 변종 LSTM도 존재한다.
먼저 위의 구조는 Peephole LSTM [Gers & Schmidhuber, 2000]이다. Vanilla LSTM와 달리 각각의 Gate에서 Cell State를 같이 확인한다.
\[\begin{aligned} f_t&=\sigma(W_f\cdot[C_{t-1},h_{t-1},x_t]+b_f) \\ i_t&=\sigma(W_i\cdot[C_{t-1},h_{t-1},x_t]+b_i) \\ o_t&=\sigma(W_o\cdot[C_t,h_{t-1},x_t]+b_o) \end{aligned}\]이를 수식으로 표현하면 위와 같다.
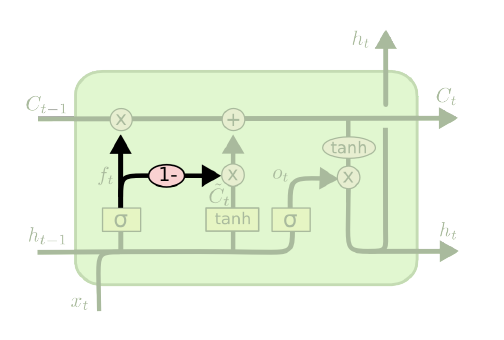
위의 구조는 LSTM의 또 다른 변종으로, Coupled forget and input gates라고 부른다. Vanilla LSTM에서는 Forget Gate와 Input Gate를 독립적으로 계산했는데, 이걸 하나로 묶어놓은 아키텍쳐다. Forget Gate와 Input Gate는 사실 서로 상반된 개념이니 이걸 분리하지 말고 하나로 써서 계산하자는 아이디어로, 이 아키텍쳐에서 $C_t$는 다음과 같이 계산된다.
\[C_t=f_t\ast C_{t-1}+(1-f_t)\ast\tilde{C_t}\]Long Short-Term Memory-Networks (LSTMN)
LSTM은 RNN의 구조를 잘 개선한 아키텍쳐긴 하지만, 여전히 문제가 남아있다. 결국 LSTM 또한 과거의 정보들을 단 하나의 Cell State에 압축해서 저장하는 형태라는 점은 변하지 않는데, 이로 인해 Sequence가 길어질수록 점점 정보가 섞이고 손실되어서, 특정 시점의 과거 데이터를 참조하기 어려워진다.
LSTMN [Cheng et al., 2016]은 이러한 문제를 해결하기 위해 고안된 아키텍쳐다.
LSTMN의 유닛은 위와 같이 생겼다. Cell State가 있어야 할 자리에 배열이 생겼는데, 이를 Memory Tape이라고 부른다. 이것이 LSTMN의 핵심 아이디어이다. 즉, 과거의 모든 정보를 하나의 Cell State Vector에 압축하는 것이 아니라, 모든 정보를 Memory Tape에 그대로 갖고 있고 어디서 어떤 정보를 꺼내올지에 대한 가중치만 계산하는 식으로 동작한다.
재미있는 점은, LSTMN에서의 이 동작은 Self-attention에 가까운데 정작 LSTMN 자체는 Transformer보다 1년 일찍 발표된 아키텍쳐라는 것이다.
Gated Recurrent Unit
Gated Recurrent Unit(GRU) [Cho et al., 2014]은 LSTM과 마찬가지로 Vanilla RNN의 치명적인 두 문제를 해결하기 위해 고안된 아키텍쳐로, LSTM의 복잡한 구조를 간소화하는 것에 초점을 맞췄다. 그렇기 때문에 성능 자체는 LSTM과 거의 비슷하다. 다만 구조가 간단하다, 즉 파라미터 숫자가 적다는 장점 덕분에 보다 단순한 상황에서는 LSTM보다 GRU로 시도하기 더 좋은 편이다.
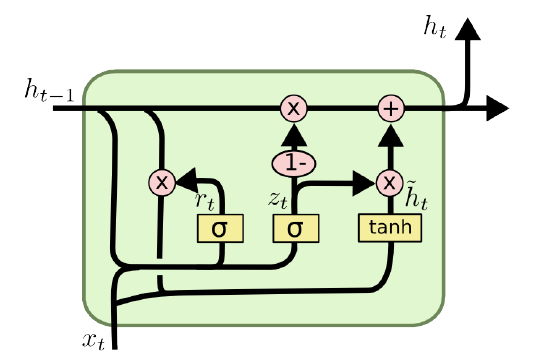
GRU에서 유닛 하나의 구조는 위 사진과 같다. LSTM에 비해 구조가 상당히 간단해져서, Cell State가 딱히 존재하지 않고 Gate도 2개로 줄었다.
\[\begin{aligned} z_t&=\sigma(W_z\cdot[h_{t-1},x_t]) \\ r_t&=\sigma(W_r\cdot[h_{t-1},x_t]) \\ \tilde{h_t}&=\tanh(W\cdot[r_t\ast h_{t-1},x_t]) \\ h_t&=(1-z_t)\ast h_{t-1}+z_t\ast\tilde{h_t} \end{aligned}\]GRU의 전 과정을 수식으로 쓰면 위와 같다. 여기서 $\ast$는 Element-wise multiplication이며, $z_t$는 Update gate, $r_t$는 Reset gate(혹은 Forget gate)라고 부르며, $\tilde{h_t}$는 New Memory Content라고 부른다.
이 흐름을 순서대로 따라가보자. 먼저 Update gate $z_t$는 이번 단계에 새로 들어오는 데이터의 비중을 결정하는 Gate이다. 여기서 사용하는 파라미터 $W_z$는 학습의 대상이다. 그리고 Reset gate $r_t$는 이번 단계의 New Memory Content $\tilde{h_t}$에 과거에서 온 정보를 얼마나 반영할 것인지를 결정하는 Gate이다. LSTM과 마찬가지로, 각 Gate에서 사용하는 파라미터 $W_r$ 역시 학습의 대상이다.
Reset gate에 의해 과거에서 온 정보 $h_{t-1}$이 $r_t$만큼만 반영되고, 여기에 이번 단계의 새로운 정보 $x_t$를 결합하여 이번 단계의 “New Content” $\tilde{h_t}$를 결정한다. 그리고 Update gate로부터 정해진 비율만큼만 반영하고, 그 나머지 비율만큼 과거에서 온 데이터를 반영하여 최종적으로 $h_t$를 계산한다. 역시 LSTM과 마찬가지로 $h_t$를 가지고 하는 이후의 작업들은 Vanilla RNN과 동일하다.
그럼 GRU는 Cell State 없이 어떻게 RNN의 두가지 문제를 해결하는지 알아보자.
먼저 어느 시점 $t$에서의 Reset gate $r_t$가 0에 가깝게 되면 무슨 일이 일어날까? 이 경우 $\tilde{h_t}$에서 과거의 정보를 거의 반영하지 않는다. 즉, 현재의 입력값을 구성하는 데에는 과거의 데이터가 거의 의미없다는 뜻이 되며, 이는 곧 Short-term Dependency를 해결한 상황이 된다. 반대로 $r_t$가 1에 가깝게 되면 과거 맥락을 적극 반영하여 $\tilde{h_t}$를 생성할 것이다.
다음으로 어느 시점 $t$에서의 Update gate $z_t$가 0에 가깝게 되면 무슨 일이 일어날까? 이 경우엔 $h_t$를 계산할 때 현재 정보 $\tilde{h_t}$를 거의 확인하지 않고 과거 정보에 큰 비중을 둔다는 얘기가 된다. 이는 곧 과거 정보를 그대로 유지한다는 의미가 되므로 Long-term Dependency를 해결한 상황이 된다. 반대로 $z_t$가 1에 가깝게 되면 과거 정보를 거의 무시하고 현재 정보로 업데이트를 하게 될 것이다.
이제 Gradient 관점에서 생각해보자. GRU에서 $h_t$를 계산하는 마지막 식만 갖고오면,
\[h_t=(1-z_t)\ast h_{t-1}+z_t\ast\tilde{h_t}\]이 식의 Gradient를 계산하기 위해 $h_t$를 $h_{t-1}$에 대해 미분하게 되면 $1-z_t$라는 상수항이 그대로 살아남는다.
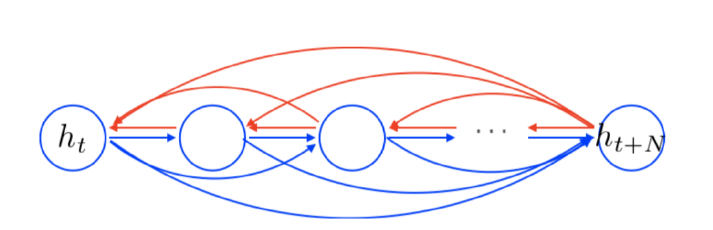
즉 LSTM의 Cell State Shortcut과 동일한 역할을 하게 된다. 즉, 순수히 곱셈으로만 전개되는 RNN에 비해 덧셈이 계산에 추가되어서 Gradient를 유지할 수 있게 된다.