Linear Algebra 6 - VAE & GAN
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Linear Algebra 과목의 수업을 다룬다…만, 과목명은 페이크고 사실은 생성형 모델을 다루는 수업이다.
Variational Autoencoder - Continued
이전 글에서 살펴본 Loss는 데이터 1개에 대한 손실값이었다.
\[L_{\theta,\phi}(x)=-\mathbb{E}_{z\sim q_{\phi}(z\vert x)}\left[ \log p_{\theta}(x\vert z) \right]+D_{KL}\left( q_{\phi}(z\vert x) \Vert p(z)\right)\]위의 ELBO를 바탕으로 전체 데이터셋에 대한 손실함수를 구하려면 다음과 같이 기댓값을 취해주면 된다.
\[L_{\theta,\phi}=\mathbb{E}_{x\sim p_{data}(x)}\left[-\mathbb{E}_{z\sim q_{\phi}(z\vert x)}\left[ \log p_{\theta}(x\vert z) \right]+D_{KL}\left( q_{\phi}(z\vert x) \Vert p(z)\right)\right]\]VAE를 요약하면 우리가 명확하게 조작할 수는 없는 어떤 “Latent Space”가 있다고 가정해서, 우리가 갖고 있는 데이터셋을 Latent Distribution으로 매핑해주는 Encoder와 이 Latent Distribution을 다시 Data Distribution으로 매핑해주는 Decoder를 갖고 있는 구조이다. 학습이 끝나고 추론 목적으로 사용할 때는 이 중 Decoder만 가져다가 사용하게 된다.
2D Latent Space
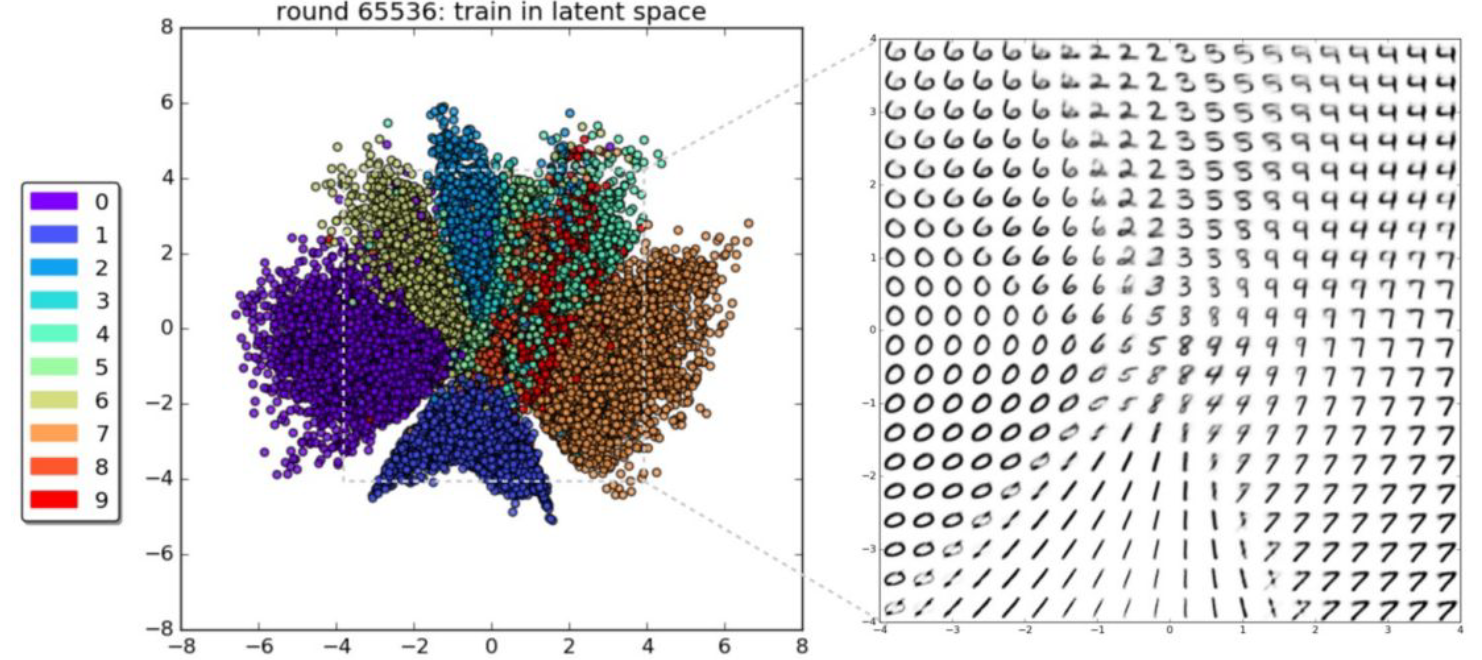
위의 사진은 MNIST를 학습시킨 어떤 Latent Variable Model의 학습 결과를 그림으로 나타낸 것이다. 비슷하게 생긴 이미지끼리는 비교적 가까운 거리에 매핑된 것을 알 수 있는데, 재밌게도 사실 확률론적으로는 이렇게 나와야 할 당위성이 부족하다. 이러한 현상을 해석하려면 기하학적으로 봤을 때 각각의 생성모델들이 어떻게 거동하는지를 봐야 한다고 하며, 현대 생성 모델은 전부 이런 특성을 갖고 있다고 한다.
Generative Adversarial Networks
Generative Adversarial Networks, 즉 GAN은 VAE와는 다른 방식을 사용하는 생성모델이다. 역시 VAE와 마찬가지로 2개의 모델을 사용하는데, Adversarial이라는 말에서 알 수 있듯이 이 모델들이 서로 적대적인 움직임을 취한다.
GAN에서는 Generator $G$와 Discriminator $D$가 존재한다. $G$는 VAE에서의 Decoder와 같은 역할을 하는, 이미지를 생성하는 모델이다. 그리고 $D$는 $G$가 생성한 이미지를 판별하는 역할을 한다. 즉, $G$가 생성한 이미지, 혹은 Ground Truth 이미지를 보고 이것이 진짜인지 가짜인지를 결정하는 역할을 한다. 그러면 $D$는 전형적인 Binary Classifier이기 때문에, $D$의 입장에서 보면 아래와 같은 최적화 문제가 된다.
\[\arg\max_{D}\mathbb{E}_{x,y}\left[ \log D(G(x))+\log (1-D(y)) \right]\]즉, Generator가 만든 가짜 이미지 $G(x)$와 Ground Truth 이미지 $y$ 간의 Binary Classifier이다. 그런데 여기서, $G$의 목표는 $D$가 최대한 구별을 어렵게 만드는 것이다. 즉, 위에서 구한 $D$ 시점의 최적화 문제를 $G$는 반대 방향으로 풀어야 한다.
\[\arg\min_{G}\mathbb{E}_{x,y}\left[ \log D(G(x))+\log (1-D(y)) \right]\]이들을 종합하면, 아래와 같은 하나의 식으로 표현할 수 있다.
\[\arg\min_{G}\max_{D}\mathbb{E}_{x,y}\left[ \log D(G(x))+\log (1-D(y)) \right]\]이렇게 하나의 손실함수를 두고 두 네트워크가 지향하는 바가 다르기 때문에 “적대적”이라는 말이 붙었다. 여담으로 이건 게임 이론에서 다루는 내용 중 하나인 Min-Max Game으로 볼 수 있다.
이런 식으로 서로가 서로를 견제하면서 학습하는 과정에서 Generator가 만들어내는 이미지의 퀄리티가 좋아지게 된다. 그런데 이걸 게임 이론의 한 갈래로 본다면, 결국에는 최종적으로 승자가 나와야 한다. GAN에서는 의도적으로 최종 승자가 $G$가 되도록 조정한다. 우리의 목적은 생성 모델, 즉 Generator이기 때문이고 $D$는 어디까지나 그 Generator를 잘 훈련시키게 도와주는 보조적인 역할일 뿐이기 때문이다. 이러한 구조는 강화학습의 Actor-Critic 구조와 유사하다고도 볼 수 있다.
그렇기 때문에 위의 식에서 $\arg\min\limits_{G}\max\limits_{D}$로 적혀있다. 즉, $D$에 의해 최대화된 값을 그 후에 $G$가 줄이는 것이다.
GAN에서만 보이는 또 하나의 특징으로는 Extrapolation이 있다. 다른 생성 모델과 달리 GAN의 Generator는 데이터셋을 직접적으로 보지 못하고 오로지 Discriminator의 정확도를 낮추는 방향으로만 학습한다. 그렇기 때문에 Generator가 자체적으로 학습을 하면서 데이터셋에 전혀 없는 특이한 추론을 하는 경우가 종종 발생한다.
여기까지 보면 상당히 이상적인 알고리즘으로 보인다. 그러나 GAN에는 치명적인 문제가 하나 있는데, 바로 이 두 네트워크를 학습시키기가 굉장히 까다롭다는 것이다. 애초에 둘 다 Neural Network이기 때문에 사실상 Black Box에 가까운데, 그걸 2개를 동시에 다뤄야 하면서 미묘한 균형까지도 맞춰야 하며, 심지어 최종적으로 Generator가 승리할 수 있게끔 유도까지 해야한다. 이 까다로운 문제를 해결하기 위해 수많은 ML 엔지니어들이 다양한 트릭과 노가다를 시도했었으나 결국 실패하여 최종적으로 비주류 모델이 되었다. 다만 Adversarial Training이라는 개념 자체는 살아남아서, GAN의 특징인 Extrapolation이 의도적으로 필요한 경우에는 이러한 방식을 채택해서 활용한다.
Optimal Solution for GAN
그런데 GAN에서 Generator는 Ground Truth를 보지 못한다. 그러면 전혀 이상한 답을 최적해랍시고 내놓는 경우가 생길 수도 있지 않을까? 다행스럽게도 이 문제에 대해서는 수학적으로 증명되어 있어서 GAN을 사용해도 분포 자체가 이상한 값으로 튀는 경우는 없다는 것이 보장된다.
이에 대한 증명은 다음의 2개의 정리로 나눠서 볼 수 있다. 우선, $G$가 고정되었다고 가정할 때, Discriminator $D$의 최적해 $D^{\ast}$는 다음과 같다.
\[D_{G}^{\ast}(x)=\dfrac{p_{data}(x)}{p_{data}(x)+p_g(x)}\]이를 증명하기 위해서, 앞에서 본 Objective Function을 생각해보자.
\[\begin{aligned} V(G,D) &=\int_{x}p_{data}(x)\log(D(x))dx + \int_{z}p_z(z)\log(1-D(g(z)))dz \\ &= \int_{x}\left(p_{data}(x)\log(D(x))+p_g(x)\log(1-D(x))\right)dx \end{aligned}\]임의의 $(a,b)\in \mathbb{R}^2 \backslash \lbrace 0,0 \rbrace$에 대해, 함수 $f(x)=a\log x + b\log(1-x)$의 구간 $[0,1]$ 내의 최댓값은 $\dfrac{a}{a+b}$이다. 따라서 위의 $D_{G}^{\ast}$의 최적해는 $\dfrac{p_{data}(x)}{p_{data}(x)+p_g(x)}$이 된다.
다음으로, $p_g=p_{data}$가 GAN에서의 유일한 Global minimizer임을 증명해보자.
\[\begin{aligned} C(G) &=\max_{D}V(G,D) \\ &= \mathbb{E}_{x\sim p_{data}}\left[\log D_{G}^{\ast}(x)\right]+\mathbb{E}_{z\sim p_z}\left[\log(1-D_{G}^{\ast}(G(z)))\right] \\ &= \mathbb{E}_{x\sim p_{data}}\left[\log D_{G}^{\ast}(x)\right]+\mathbb{E}_{x\sim p_g}\left[\log(1-D_{G}^{\ast}(G(x)))\right] \\ &= \mathbb{E}_{x\sim p_{data}}\left[\log\dfrac{p_{data}(x)}{p_{data}(x)+p_g(x)}\right]+\mathbb{E}_{x\sim p_g}\left[\log\dfrac{p_g(x)}{p_{data}(x)+p_g(x)}\right] \\ &= -\log 4 + D_{KL}\left(p_{data}\Vert \dfrac{p_{data}+p_g}{2}\right) + D_{KL}\left(p_g\Vert \dfrac{p_{data}+p_g}{2}\right) \\ &= -\log 4 + 2\cdot JSD(p_{data}\Vert p_g) \end{aligned}\]여기서 JSD는 Jensen-Shannon Divergence를 뜻하며, KL Divergence와 같이 분포 간 거리를 측정하는 다른 방법이다. KL Divergence의 단점인 비대칭이라는 점을 해결한 방식으로써, 다음과 같이 정의된다.
\[M=\dfrac{P+Q}{2}\] \[JSD(P\Vert Q)=\dfrac{1}{2}D_{KL}(P\Vert M)+\dfrac{1}{2}D_{KL}(Q\Vert M)\]즉, 두 분포 P와 Q 사이의 중간 분포 M을 정의한 후, P와 M과의 KL과 Q와 M과의 KL의 평균으로 구한다. 그렇기 때문에 JSD는 항상 0보다 크게 되고, 이 값이 최솟값 0을 가지게 될 때는 두 분포가 일치하게 될 경우이다.
다시 $C(G)$로 돌아가서 보면, 결국 $C(G)$는 $p_{data}$와 $p_g$의 JSD에 상수항을 곱하고 더하는 형태로 계산된다. 즉 $C(G)$가 최솟값이 되려면 $JSD(p_{data}\Vert p_g)=0$이어야 하고, 그 경우는 $p_g=p_{data}$인 경우밖에 없다.
이렇게 GAN의 최적해가 이상한 다른 분포로 튀는 경우가 없음을 증명할 수 있다.
VAE vs GAN
그러면 VAE와 GAN을 비교해보자. 한마디로 요약하면, VAE의 Encoder-Decoder의 순서를 뒤집은 것이 GAN이다. 세부적으로 들어가면 수행 방식은 좀 다르지만, 크게 보면 VAE는 Encoder가 Latent 분포를 만든 후 그 Latent 분포로부터 이미지를 생성하는 Decoder가 배치되는 것이고, GAN은 일단 Decoder를 통해 이미지를 만든 후 이를 Encoder가 자기가 알고 있는 분포에서 온게 맞는지 판별하는 알고리즘이라고 생각해도 무방하다.

그리고 기본적으로 이러한 차이 때문에 VAE와 GAN으로 생성한 이미지도 좀 다른 형태를 띈다. VAE는 Ground Truth에 존재하지 않는 데이터를 만들진 않는다. 다만 퀄리티가 낮을 뿐이다. 그렇기 때문에 데이터셋에 자주 등장하지 않는 부분에 대해서는 전체적으로 흐릿한 형태를 띈다. 말 그대로 “모르기” 때문이다. 그러나 GAN의 경우는 애초에 Ground Truth를 본 적도 없어서, VAE와 같이 흐릿하게 뭉개는 부분은 딱히 존재하지 않는다. 다만 데이터셋에 아예 없는 데이터를 창조해내는 경우가 발생해서, 때로는 그게 기괴하게 보이기도 한다.