Deep Learning 2 - FNN & DNN
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Deep Learning 과목의 수업을 다룬다.
Perceptron
인공지능, 혹은 인공신경망은 실제로 동물이 갖고 있는 신경을 모방한 것이다. 이 구조를 간단하게 살펴보면 다음과 같다.
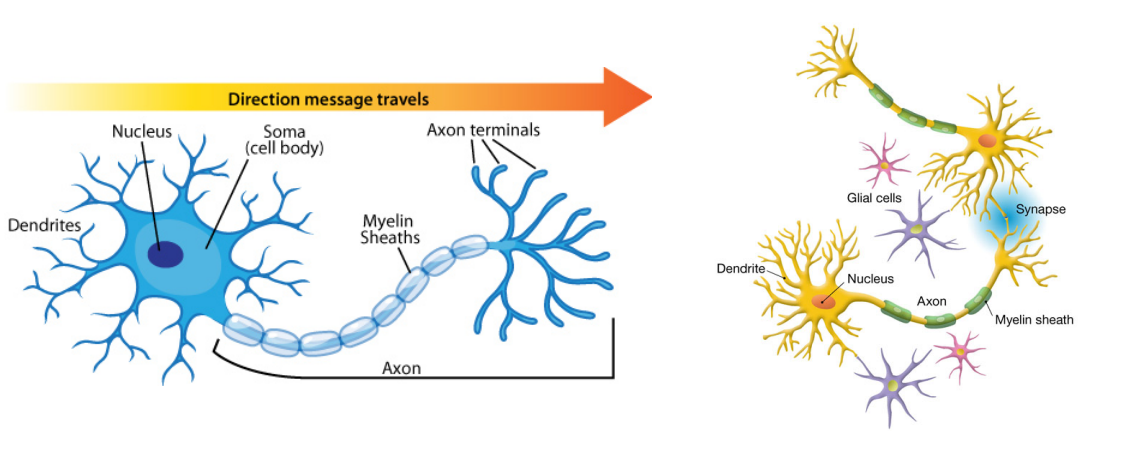
각각의 뉴런 안에는 Dendrite라는 것이 있고 이것이 수용체다. 즉, 입력을 받아들인다. 사진에서도 보이듯 Dendrite는 여러 개가 존재하므로 입력 또한 여러 곳에서 받아들인다. 이 입력을 취합하는 곳이 Soma, 즉 Cell body다. 이렇게 취합한 입력을 Axon을 통해서 밖으로 전달하게 된다. 인공 신경망은 위 구조를 그대로 모델링을 한 것이다.
최초의 인공 뉴런은 1958년도에 Perceptron이라는 이름으로 고안되었다. Perceptron의 구조는 다음과 같이 생겼으며, 실제 생명체의 신경세포와 동일한 구조를 모방했다.
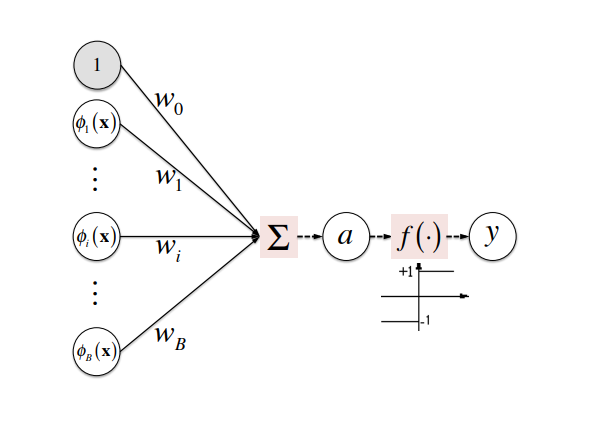
전체적인 구조는 뉴런과 동일하다. 외부로부터 입력 $\phi_{i}(x)$가 들어오고, 이들을 취합해서 이걸 어떤 식으로 전달할지 정한 후 그대로 출력한다. 여기서 “어떤 식으로 들어올지 정하는” 함수가 위의 그림에 $f$로 표기되어 있는 Activation function이다.
\[y(x)=f(w^T \phi(x)), \text{ where } f(a) = \begin{cases} +1 (a \geq 0) \\ -1 (a \lt 0) \end{cases}\]위의 과정을 한줄로 요약하면 위의 식이 된다. 여기서 Activation function이 $+1, -1$로 리턴하는 이유는 역시 뉴런을 모방하여 활성화할건지($+1$), 아니면 죽일건지($-1$)를 모델링했기 때문이다.
이 때 당시의 손실함수는 “오분류된 샘플들의 개수”로 정해졌었다. 이는 직관적으로 봐도 미분이 불가능하고, 이를 최소화할 수 있는 계산 또한 불가능하다. 그래서 당시엔 샘플을 직접 보면서 맞으면 넘어가고, 틀리면 업데이트 하는 방식으로 계산했었다.
이를 후대에 수식으로 표현한 것이 Perceptron Criterion이다. 이는 다음과 같이 정의되었다.
\[E_P(w)=-\sum\limits_{n \in M} w^T \phi(x_n)t_n\]여기서 $M$은 “오분류된 샘플들의 집합”이다.
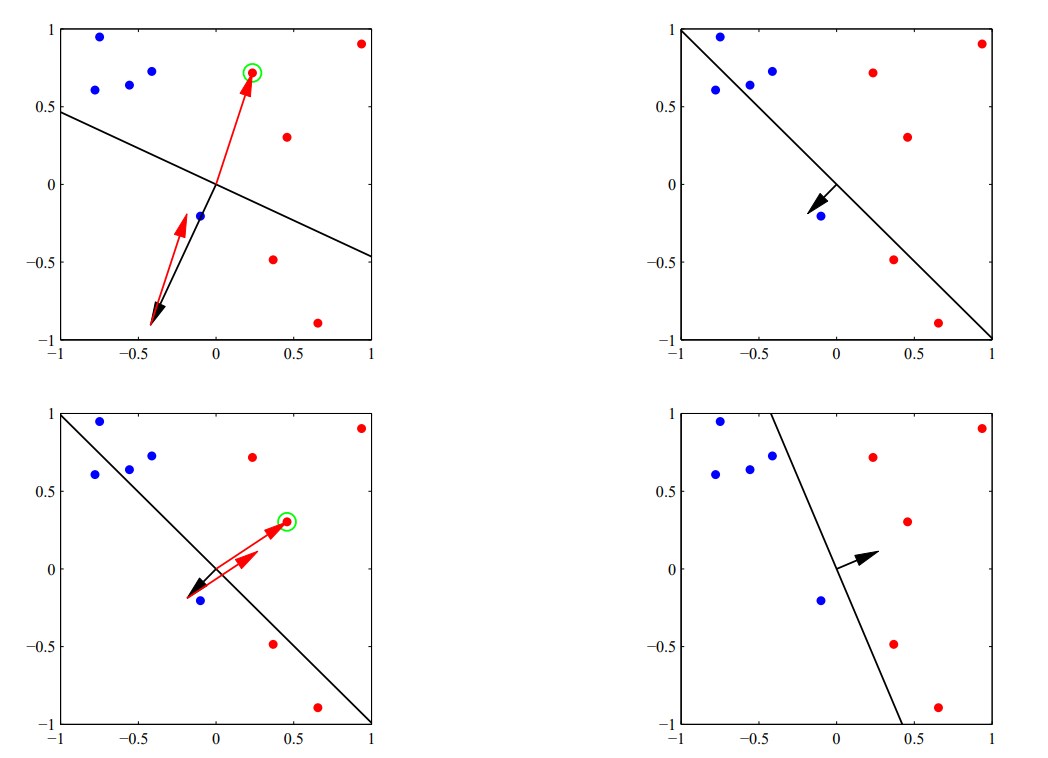
위의 그림들은 당시의 Perceptron이 어떻게 동작했는지를 보여준다. 우선, 격자 전체를 가로지르는 검은색 선을 결정경계(Decision Body)라고 부르고, 파라미터 $w$는 그 결정경계에 수직인 벡터로 존재한다. 이를 법선 벡터라고 부른다.
이 선을 경계로 데이터를 분류하는데, 만일 오분류된 샘플이 발견되면 $w$에 그 샘플이 가리키는 벡터를 더해서 새로운 법선 벡터로 삼는다. 그러면 결국 결정경계가 회전하는 효과와 동일하다. 이러한 방식을 오분류된 샘플이 없을 때까지 반복하는 것이다.
이를 수식으로 표현하면 다음과 같다.
\[w^{(\tau+1)}=w^{(\tau)}-\eta\nabla E_P(W)=w^{(\tau)}+\eta\phi(x_n)t_n, \text{ where } n \in M\]여기서 $\eta$는 Learning rate, $\tau$는 Step index라고 불렀다.
이것이 1958년도에 발표되었던 최초의 학습 가능한 신경망이다. 그런데 Perceptron에는 크게 두 가지 문제점이 있었는데, 첫번째로 선형으로 분리가 불가능한 문제에 대해선 답을 영원히 찾지 못한다는 점이다. 이 경우 항상 오분류된 샘플이 발생하여 영원히 업데이트가 일어나게 된다.
두번째 문제는 Perceptron에서 사용한 활성화 함수이다. 앞에서 짚었듯, 이 함수는 미분이 안된다는 문제점이 있어 계산하기가 너무 어렵다. 이 문제의 답은 1980년도에 Sigmoid 및 $\tanh$를 찾아냈고, 그 후엔 2010년도에 들어서야 Rectified Linear Unit, 즉 ReLU 함수로 바뀌게 되었다.
Feed-Forward Neural Networks
저번 글에서 모델의 복잡도를 끌어올리기 위해 샘플 데이터 $x$에 대한 선형결합이 아니라 다른 비선형 함수 $\phi_j(x)$를 basis function으로 사용할 수 있다는 내용을 다뤘었다.
이 basis function을 어떻게 정의하느냐에 따라 다양한 모델들이 결정되는데, 대표적으로 Support Vector Machine, 즉 SVM은 데이터셋 중 내가 중요한 샘플이 되는 Support Vecotr $X_i$를 찾고, 새 입력이 들어오면 이 Support Vector와의 유사도를 비교하는 식으로 수행되며, 여기서의 basis function은 이 유사도 계산 함수가 된다.
그런데 생각해보면, 모델도 결국 $x$에 대한 함수로 정해지니까 이 basis function에 모델을 넣으면, 즉 학습 가능한 형태로 만들면 좀 더 복잡한 문제에 대응할 수 있지 않을까?
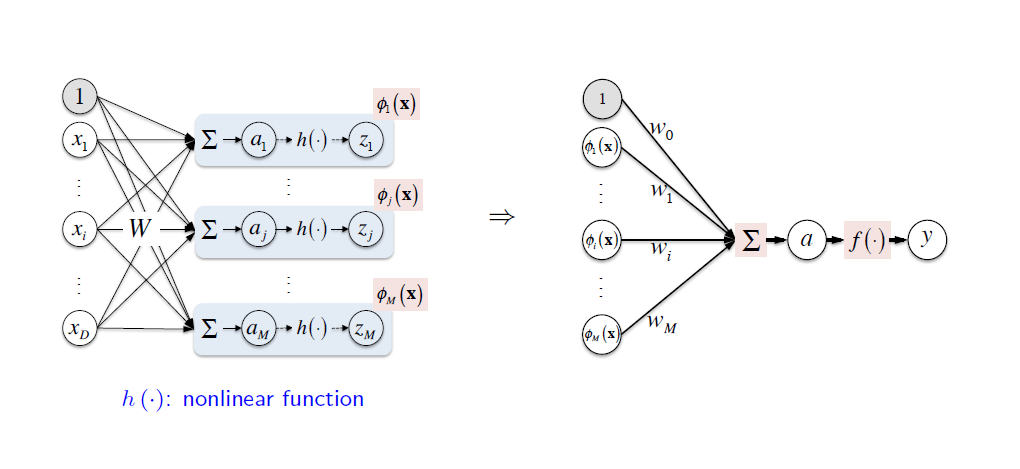
즉, 위의 그림과 같이 입력 샘플을 함수 $h$에 통과시킨 값을 $\phi_j(x)$로 하고, 이걸 다시 통과시켜서 최종적인 값을 얻는 것이다. 이걸 FNN(Feed-Forward Network), 혹은 MLP(Multi Layer Perceptron)이라고 부른다.
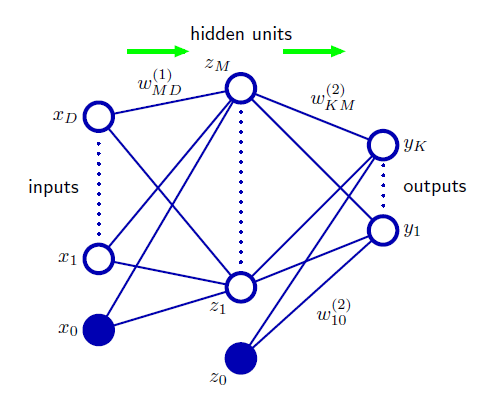
위의 그림은 레이어가 2개인 FNN이다. 이를 수식으로 표현하면 다음과 같은 구조가 된다.
\[\phi(x)=h(W^{(1)}x)=z, W^{(1)}=\left[w_{ji}^{(1)}\right] \in \mathbb{R}^{M \times (D+1)}\] \[y=f(W^{(2)}z), W^{(2)}=\left[w_{kj}^{(2)}\right] \in \mathbb{R}^{K \times (M+1)}\]그냥 우리가 알고 있는 그 모델이 겹쳐져 있는 형태일 뿐이다. 물론 이 이후에 이 문제가 Regression 문제냐, Binary classification 문제냐, 혹은 Multiclass classification 문제냐에 따라 최종 출력값을 그대로 쓸지, Sigmoid를 적용할지, Softmax를 적용할지 결정하는 것은 동일하다.
이러한 인공 신경망에서 가운데 레이어를 hidden layer라고 부르는데, 이는 단순히 이 Layer가 생성해야 할 정답이 가려져 있기 때문이다. 이 네트워크의 전체적인 입력값과 출력값은 알고 있지만, 각 레이어마다의 입/출력값은 아무도 모르기 때문에 “hidden”이라고 하는 것이다.
또한 네트워크의 설계는 자유고 모든 레이어가 반드시 Fully-connected일 필요는 없다. 경우에 따라 서로 다른 레이어로 연결되거나 혹은 아예 특정 레이어를 건너뛰는 Skip connection 등도 충분히 가능하며 실제로 ResNet과 같이 이런 식으로 디자인된 네트워크가 존재한다.
다만 Feed-Forward라는 이름답게, 역방향으로 돌아가는 식의 네트워크 구축은 불가능하다. 반드시 입력에서 출력으로 가는 방향으로만 구성되어야 한다.
Network Training
그렇다면 이제 이러한 FNN을 어떻게 학습시킬 수 있는지 알아보자. 먼저 손실함수의 구조는 동일하다. 간단히 복습해보면 다음과 같다. Input vector를 $\left\lbrace x_n \right\rbrace_{n=1}^N$, 그리고 Target vector를 $\left\lbrace y_n \right\rbrace_{n=1}^N$라고 하자.
Regression 최종적으로 구해진 예측값을 그대로 사용한다. 이 때 손실함수의 형태는 다음과 같이 MSE, 혹은 경우에 따라 MAE 등을 사용한다.
\[E(w)=\dfrac{1}{2}\sum_{n=1}^{N}\lVert y(x_n,w)-t_n \rVert^2\]Binary Classification 최종적으로 구해진 예측값에 Activation function으로 Sigmoid를 씌운다. 이 때 손실함수의 형태는 다음과 같은 Cross-entropy가 된다.
\[E(w)=-\sum_{n=1}^{N}\left\lbrace t_n \ln y_n + (1-t_n)\ln (1-y_n) \right\rbrace\]Multiclass Classification 최종적으로 구해진 예측값에 Softmax를 씌운다. 손실함수의 형태는 Binary classification과 동일한 Cross-entropy를 사용한다.
\[E(w)=-\sum_{n=1}^{N}\sum_{k=1}^{K}t_{kn}\ln y_{kn}\]
이제 위에서 구한 손실함수를 최소화시킬 방법을 생각해보자. 우리가 찾고자 하는 것은 파라미터 $w$이다. 그리고 함수의 변화량을 알 수 있는 방법은 미분이다. 그러면 위의 손실함수를 각각의 파라미터 $w_1,\ldots,w_d$에 대해서 미분하면 각각의 파라미터별로 최소화시킬 방향을 알 수 있지 않을까? 이러한 개념으로 등장한 것이 Gradient Descent다.
Gradient는 각 변수에 대한 편미분을 성분으로 갖는 벡터를 의미하며, 수식으로 표현하면 다음과 같다.
\[\nabla E = \left[ \dfrac{\partial E}{\partial w_1}, \dfrac{\partial E}{\partial w_2}, \ldots, \dfrac{\partial E}{\partial w_d} \right]^T\]손실함수의 Gradient를 구하면, 위의 정의에 의해 어떤 벡터가 나올 것이다. 이 벡터는 손실함수의 값이 커지는 방향을 가리키므로, 우리는 이와 정 반대의 방향으로 파라미터를 조정하면 되는 것이다. 이를 Gradient Descent라고 한다.
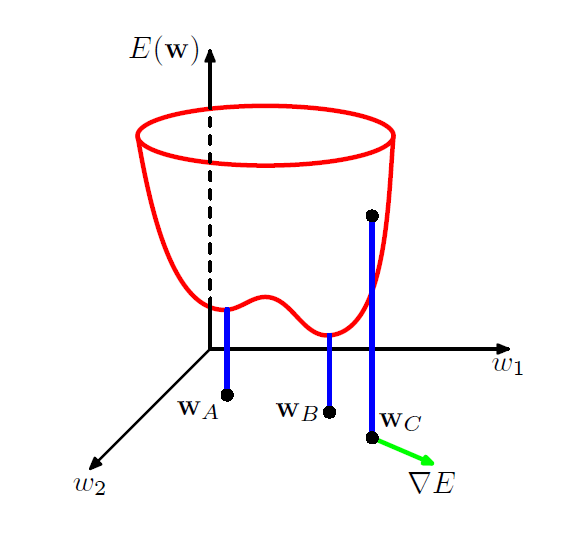
위와 같이 그림으로 보면 좀 더 이해하기 쉽다. 손실함수가 $w_1$, $w_2$에 대해서 저런 형태를 띄고, 우리는 현재 파라미터 $w_C$에 있다고 가정하자. 이 지점에서의 Gradient를 계산해보면 녹색 벡터 $\nabla E$가 나오게 된다. 그러면 우리는 $\nabla E$와 정 반대 방향인 $w_B$ 방향으로 가면 되는 것이다.
이것이 딥러닝 학습의 전부이다. 그러나 이대로만 두고 끝내면 너무 많은 것을 운에 의존해야 하고, 성능도 보장이 되지 않기 때문에 위의 과정을 최적화할 여러 가지 방법들이 존재한다.
우선 파라미터 공간의 차원이 굉장히 높기 때문에 Gradient Descent가 알려준 그대로 이동하면 무슨 일이 일어날지 모른다. 그로 인해 일정 비율만큼씩만 이동한다.
\[w^{(\tau+1)}=w^{(\tau)}-\eta \nabla E(w^{(\tau)})\]여기서 추가로 등장하는 변수 $\eta$가 이 이동의 비율을 결정하며, 이걸 Learning rate라고 부른다. 그리고 이는 대부분의 딥러닝 아키텍쳐에 등장하는 Hyper parameter이다. 일반적으로 $\eta$는 0.001 이하의 매우 작은 값을 사용한다. 이 값을 너무 크게 하면 최저점을 이탈해버리는 경우가 발생하기 쉽고, 또 너무 작게 하면 시간이 굉장히 오래 걸리기 때문에 적절한 균형이 중요한데, 이 $\eta$를 유동적으로 변경하는 Scheduling 관련 최적화도 존재한다.
다음으로, 한번에 몇 개의 샘플 데이터를 Gradient 계산에 사용할지도 정해야 한다. Batch는 전체 데이터셋을 한 번에 계산한 Total Gradient를 구하는 방식이다. 이 경우 내가 갖고 있는 모든 데이터에 대한 Gradient가 바로 나오니 신뢰도도 높고 업데이트 횟수도 적지만, 한 스텝당 계산이 굉장히 느리고 손실함수 전체의 최저점이 아닌 Local Optima에 빠질 위험이 매우 높다. 심지어 Local Optima에 빠지면 자력으로 나갈 방법이 존재하지 않는다.
이와 정 반대되는 방법이 On-line이다. Batch와는 정 반대로 한 번에 하나의 샘플만 가지고 Gradient를 계산한다. 다만 여러 번 학습을 시킬 떄 넣는 샘플의 순서가 고정되면 FNN이 이것조차도 학습하기 때문에 각 epoch마다 샘플의 순서는 계속 랜덤으로 정해진다. 이 때문에 이 방식을 Stochastic이라고도 부른다. 이 경우엔 Batch와는 정 반대로 각각의 Gradient에 대한 신뢰도가 낮다. 하지만 각 스텝당 계산은 빨리 끝나며 Local Optima에서 자력으로 빠져나갈 방법이 존재한다는 장점이 있다. 이 장점 때문에 위의 두 방식을 중에선 On-line이 더 낫다고 평가된다.
마지막으로 둘의 장점만을 취한 Mini-batch가 있다. 방법도 둘을 적절히 섞었는데, 한 번에 특정 개수의 샘플만을 Gradient 계산에 사용하는 것이다. 각각의 Mini batch별 순서는 여전히 랜덤으로 동작하는 등 나머지 규칙은 위의 두 방식을 그대로 활용한다. 현재는 이 Mini-batch가 가장 성능이 좋다고 알려져 있다.
Back Propagation
그럼 위에서의 학습 방법을 여러 Layer가 겹쳐있는 네트워크에서 사용하려면 어떻게 해야 할까? 중간에 끼어있는 hidden Layer는 어떤 값을 가져야하는지 아무도 모르는데, 어떻게 손실함수를 계산하고 Gradient Descent를 적용할 수 있을까? 이것에 대한 답이 Back Propagation이다.
MLP에서, 각각의 unit은 자기한테 들어오는 input의 weighted sum을 계산하고, 이를 Activation function $h$에 통과시켜 다음 층으로 전달해준다.
\[a_j^{(l)}=\sum_{i}w_{ji}^{(l)}z_i^{(l-1)}, z_j^{(l)}=h(a_j^{(l)})\]그러면 이 함수의 Gradient 계산을 위해 $w_{ji}^{(l)}$에 대해 편미분을 했다고 가정하면, chain rule에 의해 다음과 같이 정리된다.
\[\begin{aligned} \dfrac{\partial E_n}{\partial w_{ji}^{(l)}} &= \dfrac{\partial E_n}{\partial a_j^{(l)}} \dfrac{\partial a_j^{(l)}}{\partial w_{ji}^{(l)}} \\ &= \delta_j^{(l)} z_i^{(l-1)} \end{aligned}\]여기서 $\delta_j^{(l)}$은 $a_j^{(l)}$에 대한 손실함수의 Gradient이다. 결국 중요한건 Output layer에서부터 자신에게 필요한 Gradient를 계산하고, 그 중 일부를 그 이전 layer로 넘겨주면서 계산이 역방향으로 전파될 수 있다는 것이다. 이를 도식화하면 다음과 같다.
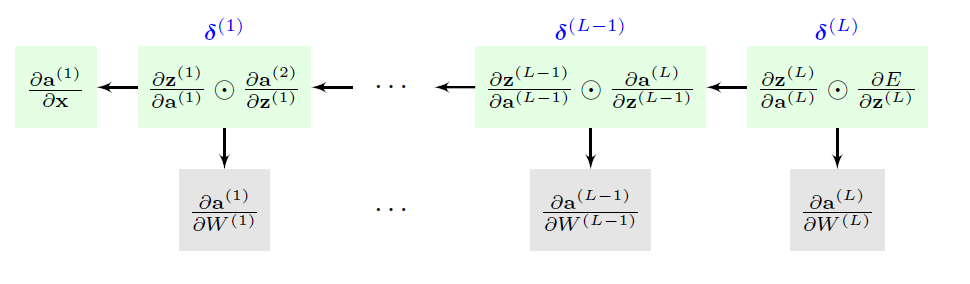
이러한 방식으로 모든 레이어에 대한 각각의 손실함수를 계산할 수 있고, 모든 layer의 파라미터를 최적화 할 수 있게 된다. 이 일련의 과정을 Back Propagation이라고 부른다.
Computational Graph
그런데, 위의 모든 과정을 적용하면 FNN을 학습시킬 수 있다고 하지만, 이걸 어느 세월에 다 계산할까? 예를 들어 Activation function을 다른 것으로 바꾸고자 하면 위의 모든 레이어에 대한 편미분을 다시 다 계산해서 넣어줘야 하는 것일까? 이걸 수동으로 하는 것은 굉장히 어렵고 까다로운 일일 것이라는 것은 자명해보인다. 그리고 이러한 과정들을 좀 간단하게 하기 위해 Computational Graph라는 개념이 고안되었다.
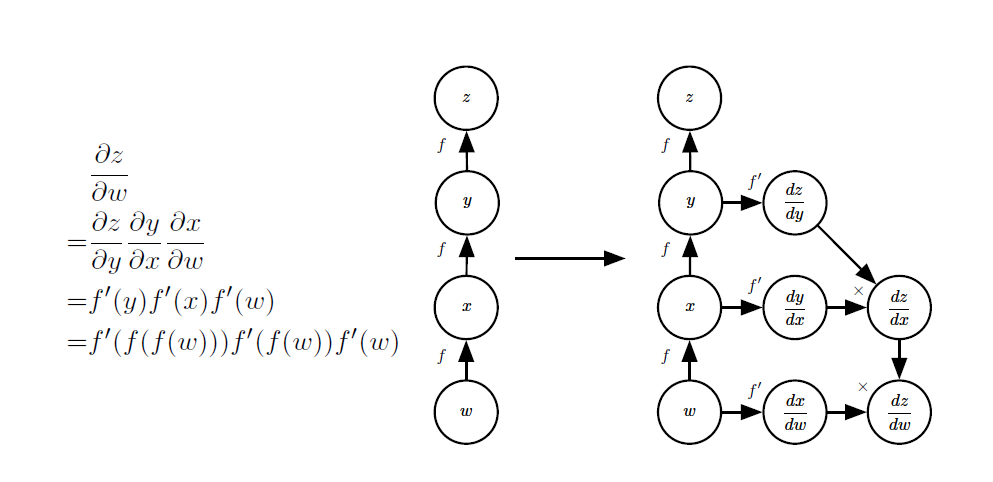
말 그대로 딥러닝의 네트워크 구조를 그래프로 도식화할 수 있는 것으로, PyTorch, Tensorflow, JAX 등에는 이러한 개념이 그대로 적용되어 있어 더 이상 일일히 미분을 계산할 필요가 없어졌다. 생각한 대로 네트워크를 구성하면 그 뒷편에 깔려있어야 하는 계산들을 기계적으로 할 수 있게 된 것이다.
Deep Neural Networks
Universal Approximate Theorem이란 것이 있다. 1989년 Hornik에 의해 발표된 이론으로, Hidden layer가 단 1개만 있는 FNN, 즉 Layer 2개짜리 FNN으로도 “충분한 개수의 unit이 주어진다면” 임의의 함수를 다 표현할 수 있다는 정리이다.
그런데 표현해야 할 함수가 복잡할수록 저 unit 개수의 조건을 만족하기가 상당히 어려워진다. Fully connected를 가정하면 unit 개수가 1개 늘어날 때마다 파라미터의 개수가 기하급수적으로 증가하게 되고, 파라미터가 기하급수적으로 증가하면 필요한 데이터의 양은 상상을 초월할 것이다.
그렇기 때문에 이론상 가능은 할지라도 실제로 Layer 2개짜리 FNN으로는 복잡한 모델을 만드는 것은 현실적으론 불가능에 가깝다.
그러면 굳이 Layer를 2개로 고정시킬 필요가 있을까? FNN에서 모델을 만들때 썼던 함수 중첩을 여러번 반복하면 되지 않을까? 실제로 2009년에 Bengio에 의해 Layer를 더 깊게 쌓는다면 더 적은 unit으로도 같은 정확도를 낼 수 있음이 증명되었다. Unit 개수가 줄어들었다는 것은 파라미터의 개수가 줄어들었다는 뜻이고, 이는 곧 더 적은 데이터만으로도 같은 효율을 낼 수 있다는 의미이다.
이미지를 분석하는 모델을 개발한다고 가정하자. Hidden layer가 1개뿐이라면 그 layer에서 픽셀 간의 복잡한 관계를 전부 표현해야만 한다. 그렇기 때문에 이를 감당할 수 있을 정도로 “충분히 많은” 수의 unit이 필요하게 된다. 하지만 Layer를 여러 개 쌓으면 각각의 Layer마다 서로 표현하고자 하는 단계를 나눠 계층적으로 문제를 풀 수 있게 되고, 이런 식으로 분할하면 필요한 전체 unit의 수가 결과적으로 더 적게 된다는 의미이다. 얼굴 인식을 예로 들면, 각각의 Layer별로 픽셀의 밝기, Edge 및 간단한 도형의 형태, 좀 더 복잡한 형태, 얼굴 인식 등으로 풀어야 하는 문제를 분할해서 주는 셈이 된다.
이로 인해 현재의 딥러닝 아키텍쳐는 여러 중첩의 MLP, 즉 Deep Neural Networks(DNN)을 기반으로 한다. 이를 수식으로 표현하면 아래와 같은 형태가 될 것이다.
\[y_k=f\left(\sum_{l}W_{kl}^{(L)}h\left(\sum_{m}W_{ml}^{(L-1)}h\left(\cdots h\left(\sum_{i}W_{ij}^{(1)}x_i\right)\right)\right)\right)\]사실 이러한 아이디어는 최근에 정립된 것은 아니다. FNN이란 개념이 고안되었을 때부터 같이 떠오른 생각이었는데, 크게 3가지 문제가 있어서 당시엔 아이디어로만 남았었다. 그 중 2개는 충분한 양의 데이터셋 부족, 그리고 하드웨어의 계산능력 부족이다.
이들은 시간이 지남에 따라 자연스럽게 해결되었는데, 마지막 문제는 알고리즘적인 이슈였다. Vanishing Gradient Problem이라고 부르는데, 각각의 Layer 사이에 끼어있는 Activation function들은 미분하면 값이 그리 크게 나오지 않는다. 구체적으로, Sigmoid의 경우 도함수의 최댓값이 0.25, 그리고 $\tanh$의 경우 도함수의 최댓값이 1이다. 그로 인해 Layer가 여러 겹 쌓여있는 상태라면 Back propagation을 통해 Gradient를 전파하기 위해 계속 곱할 경우 이 Gradient가 0에 수렴해버리는 문제가 발생한다.
이 문제는 2006년에 Hinton에 의해 새로운 방법이 제시되며 해결되었다. Pre-training이라고 하는데, 깊은 곳의 레이어는 학습이 잘 안되니까 랜덤한 값으로 시작하는 것이 아니라 미리 의미있는 값으로 시작하도록 하는 것이다. 그러면 어떤 식으로 사전 훈련을 시킬 수 있을까? 다양한 방법론이 있지만, 이 당시엔 auto-encoder라는 방법으로 수행했었다. 간단히 말해서, 특정 레이어들만 따로 떼서 입력값을 그대로 복원하도록 훈련시키는 것이다.
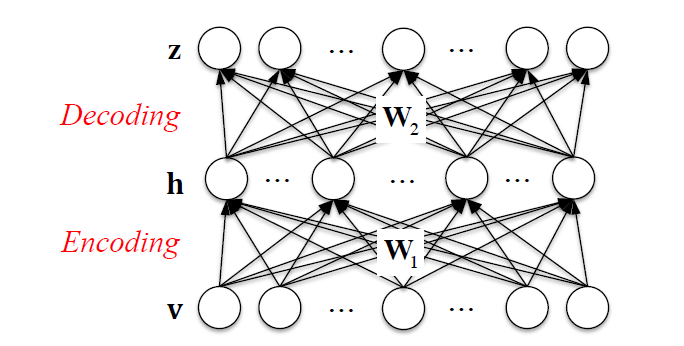
위의 그림에서 Input layer $v$와 Output layer $z$는 완전히 동일하다. Hidden layer $h$만을 훈련시키는 상황인데, $v$와 $h$는 서로 차원이 다르기 때문에 $W_1$이 Identity function이 되지 않고, 원래 데이터를 잘 보존한 상태로 학습을 시작할 수 있게 된다. 물론 차원이 같은 경우에도 Regularization을 잘 조절해서 Identity function이 나오지 않도록 조절하면 된다. 이 Auto-encoder는 현재는 사전훈련으로 잘 쓰이진 않지만 대신 이 구조를 그대로 사용한 아키텍쳐로 존재하여, 이상 탐지 등에서 사용하고 있다.
이렇게 어느 정도 유의미한 값을 갖게 하고 훈련을 시작하면 완전한 랜덤값으로 시작하는 것보다 Gradient가 안정적으로 흘러서 Layer가 많이 쌓여도 안정적으로 학습시킬 수 있게 된다.
Algorithmic Advances & Tricks
근본적인 딥러닝의 원리는 여태까지 논의한 내용에서 크게 변경되지 않았다. 그러나 어떻게 하면 더 잘 훈련시킬지에 대한 방법론들은 많이 발전했는데, 여기선 이들 방법들을 다룬다.
Weights Initialization
파라미터의 초기값의 경우, 여러 가지 선택지를 생각해볼 수 있다. 가우시안 분포 $\mathcal{N}(0, 1)$ 혹은 Uniform distribution $W^{(l)} \sim U\left[-\dfrac{1}{\sqrt{n_{l-1}}}, \dfrac{1}{\sqrt{n_{l-1}}}\right]$(여기서 $n_{l-1}$은 Layzer $l-1$의 크기를 의미한다.), 또는 2010년 Glorot and Bengio에 의해 밝혀진 Normalized Initialization인 $W^{(l)} \sim U\left[-\dfrac{\sqrt{6}}{\sqrt{n_{l-1}+n_l}}, \dfrac{\sqrt{6}}{\sqrt{n_{l-1}+n_l}}\right]$을 고려할 수 있다. 그런데 사실 큰 차이는 없긴 하다.
Early Stopping
훈련 중 Error Curve를 관찰하다가 더 이상 에러가 떨어지지 않을 때 일찍 중단시키는 것이다. 더 이상 개선되지 않는 상태로 학습을 시키면 과적합 위험이 있기 때문인데, 사실 대규모 LLM 등에서는 크게 고려하지 않고 그냥 집어넣기도 한다.
Weight Decay: $l_2$-norm Regularization
이 내용은 저번 글에서 설명한 내용과 동일하다. 과적합 발생 시 파라미터의 값이 매우 크게 튀어오른다는 점을 이용하여 손실 함수에 파라미터에 대한 항을 페널티로 추가하는 것이다.
Activation Functions
각 Layer 사이를 이어주는 Activation function으로 어떤 것을 사용할지에 대한 논의 또한 계속 진행되어 왔다. 초창기의 -1, 혹은 1로 떨어지는 Step function 이후로는 다음과 같은 시도들이 있었는데, 현재는 대부분 ReLU와 거기서 파생된 아종들을 쓰는 추세이다. Sigmoid 및 $\tanh$를 쓰지 않는 이유는 역시 모든 점에서의 미분값이 1보다 작거나 같아 Vanishing Gradient Problem에 엮이기 때문이다.
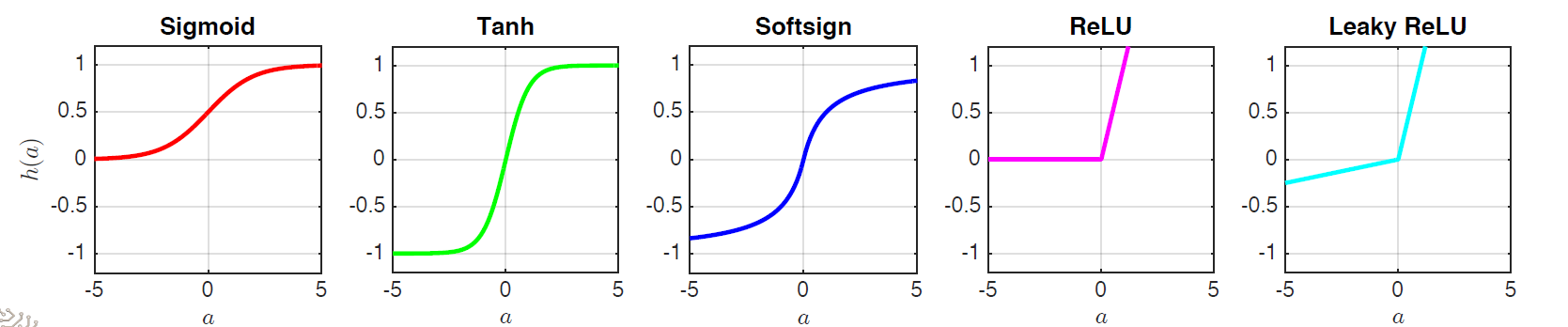
각각의 함수의 형태는 위 그래프와 같고, 수식은 아래와 같다.
- Logistic Sigmoid: $h(a)=\dfrac{1}{1+\exp(-a)}$
- Tanh: $h(a)=\dfrac{\exp(a)-\exp(-a)}{\exp(a)+\exp(-a)}$
- Softsign: $h(a)=\dfrac{1}{1+\vert a \vert}$
- ReLU: $h(a)=\max(0,a)$
- Leaky ReLU: $h(a)=\max(ka,a), 0 \lt k \lt 1$
- Parametric ReLU: $h(a)=\max(k^\ast a,a)$
Denoising Auto-Encoder
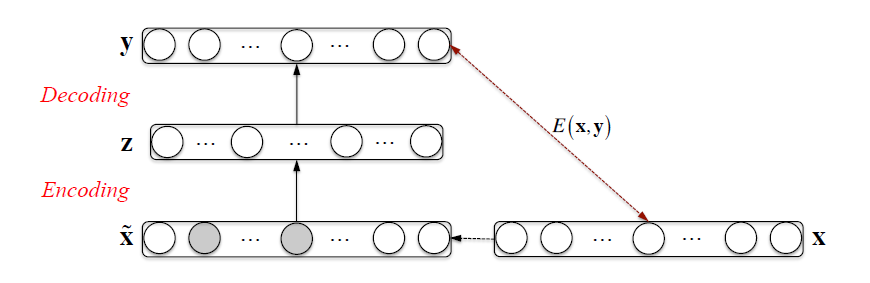
앞에서 Auto-encoder는 입력값을 완벽히 복원하는 아키텍쳐, 혹은 사전학습 방법이라고 했었다. 그런데 입력에는 어느 정도의 Noise를 주고 그 Noise를 제거한 입력을 복원하도록 시킬 수도 있다. 이를 Denoising Auto-Encoder라고 부르는데, 이를 통해 스스로 Noise를 걷어내는 역할을 할 것을 기대할 수 있다.
Dropout
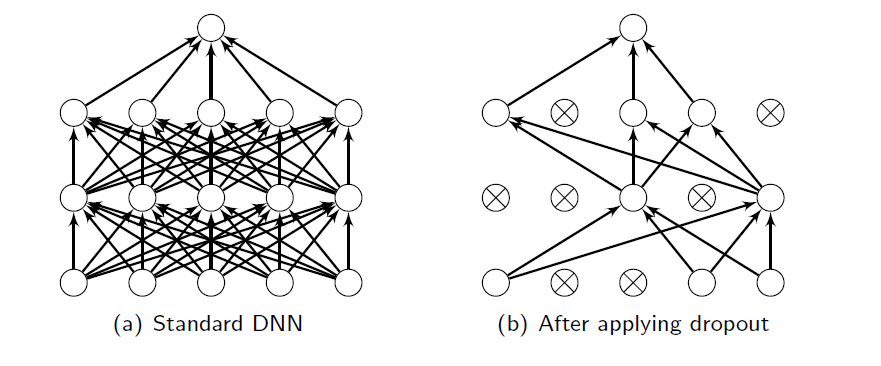
동일한 Layer 안에서, 각 unit들은 다른 unit이 어떤 식으로 학습하고 있는지를 모른다. 그런데 이로 인해 경우에 따라선 학습해보니 특정 unit 쌍이 동일한걸 학습하거나 혹은 다른 unit에게 의존적인 형태가 되버리는 경우가 발생할 수 있다. 이러한 현상이 발생하면 사실상 한 unit이 할 수 있는 것을 여러 unit이 모두 하고 있는 형태가 되어버리니 리소스 낭비는 물론, 과적합도 유발할 수 있다.
이를 Co-adaptation이라고 하는데, 이 현상을 막기 위해 고안된 기법이 Dropout이다. 학습 중 임의의 순간에 랜덤으로 unit들을 지워버려서 마치 존재하지 않는 것처럼 만들어놓고, 그 상태로도 학습을 시키는 것이다.
Dropconnect
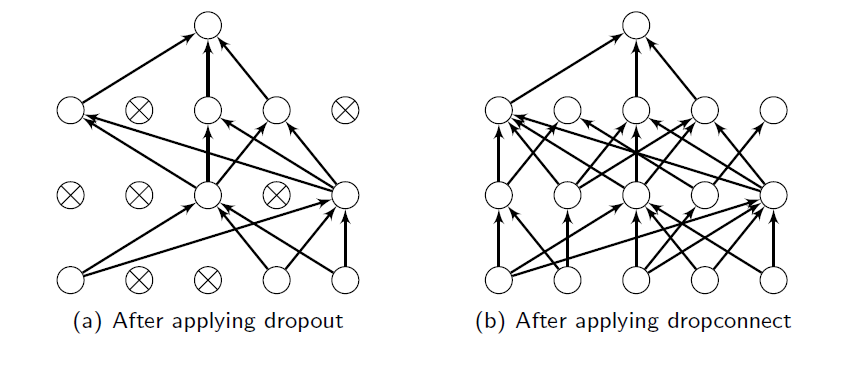
Dropout에서 한 발 더 나아가서, 여기서는 아예 랜덤하게 커넥션을 지워버린다. 다만 Dropconnect가 Dropout보다 더 좋다라는 내용의 논문은 존재하지만 현대에는 결국 Dropout이 살아남았다.
Batch Normalization
학습하는 중 이전 Layer의 파라미터가 업데이트가 될 때마다, 다음 Layer는 아예 다른 분포에서 온 값을 받게 된다. 그러면 머신러닝의 전제 조건인 “iid”, 즉 모든 데이터가 동일한 분포로부터 왔다는 가정이 이 상황에 한해서는 깨지게 되어, 학습이 불안정해지고 느려진다.
이를 해결하기 위해서 각 Layer의 unit 값을 매 Mini-batch마다 정규화를 시켜준다.
\[\hat{x}_k^{(l)}=\dfrac{x_k^{(l)} - \mathbb{E}[x_k^{(l)}]}{\sqrt{\text{Var }[x_k^{(l)}]}}, k=1, \ldots, F^{(l)}, F^{(l)}= \text{ number of units in the layer } l\]그런데 이렇게 강제로 정규화를 시켜주게 되면 Layer가 표현할 수 있는 범위가 제한된다. 이를 보정하기 위해, $\gamma_k^{(l)}$, $\beta_k^{(l)}$라는 Trainable parameter를 추가해서 정규화된 값을 다시 Scaling 및 Shifting해준다.
\[y_k^{(l)}=\gamma_k^{(l)}\hat{x}_k^{(l)}+\beta_k^{(l)}\]Momentum
기본적인 SGD(Stochastic Gradient Descent)는 Gradient Descent가 가리키는 방향이 골짜기 형태라면 좌우로 진동하면서 천천히 내려가게 된다. 이 불필요한 스텝을 줄이기 위해, 물리학에서 “Momentum”이라는 개념을 가져와 추가했다.
\[v_t=\gamma v_{t-1}+\eta\nabla_w f(w), w \leftarrow w-v_t\]즉, 업데이트 벡터 $v_t$를 계산할 때 이전 스텝의 값인 $v_{t-1}$을 반영하는 것이다. 여기서 $\gamma$는 일반적으로 0.9로 설정한다. 이를 통해 얻는 효과는 다음의 두가지인데, 둘 모두 수렴이 빨라지는 효과를 낸다.
- Gradient 방향이 일관되게 같다면 벡터가 누적이 되어 가속
- Gradient 방향이 달라진다면 서로 상쇄되어 진동 감소
Nesterov Accelerated Gradient (NAG)
Momentum의 문제점은, 관성이 반영되어서 달려가고 있는 중인데도 현재 위치에서 Gradient를 계산한다는 것이다. 그로 인해 지형이 변화되는 순간에도 그 변화가 한 스텝 늦게 반영된다.
이 문제를 해결하기 위해 NAG라는 기법이 고안되었는데, Gradient를 현재 위치가 아니라 이동 후의 위치에서 계산하는 것이다.
\[v_t=\gamma v_{t-1}+\eta\nabla_w f(w-\gamma v_{t-1}), w=w=-v_t\]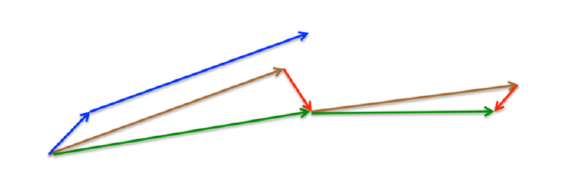
위의 그림에서 Momentum은 파란색 벡터이다. 먼저 현재 위치에서의 Gradient를 계산한 후, 관성에 의해 보정된 큰 점프를 하게 된다. NAG의 경우 반대로, 갈색 벡터처럼 먼저 이전 관성에 의해 보정된 큰 점프를 한 후, 현재 위치에서의 Gradient를 계산하여 최종적으론 녹색 벡터처럼 이동하게 된다.
Adagrad
지금까지의 방법들은 Learning rate를 모두 동일한 변수 $\eta$를 사용했다. 그러나 파라미터의 특징에 따라 학습률이 달라져야 한다는 고찰 아래, 파라미터마다 모두 다른 Learning rate를 적용하려는 시도가 있었다. 그리고 Adagrad가 그 첫 번째 시도이다.
\[w_{t+1,i} \leftarrow w_{t,i}-\dfrac{\eta}{\sqrt{G_{t,ii}+\epsilon}}\nabla_{w_t}f(w_{t,i})\]여기서 $G_{t,ii}$는 대각 행렬로, $(i,i)$ 원소는 각 파라미터 $w_i$에 대해 $t$ 시점까지 누적된 Gradient의 제곱합이다. 이를 Learning rate의 분모에 넣게 되면, 자주 업데이트 된 파라미터는 Learning rate가 줄어들고, 반대로 적게 업데이트 된 파라미터는 Learning rate가 유지되어 Sparse data를 처리하기 쉬워진다.
하지만 Adagrad에서 핵심으로 쓰는 $G_{t,ii}$ 행렬은 누적된 Gradient의 제곱합이라는 특성상 모든 원소가 단조증가하게 된다. 이로 인해 학습이 길어지게 되면 모든 파라미터의 Learning rate가 결국 0에 수렴하는 문제가 생겨, 이 시점이 도래하면 학습이 아무것도 되지 않는다.
RMSprop
Adagrad의 Learning rate 수렴 문제를 해결하기 위해 고안된 방법 중 하나다. $G_t$의 모든 원소가 단조증가하는 것이 문제의 원인이었기 때문에, 단순한 누적 제곱합 대신 Exponentially Decaying Average를 사용한다.
\[E[\nabla_w f(w)^2]_t = \gamma E[\nabla_w f(w)^2]_{t-1} + (1-\gamma)\nabla_{w_t} f(w_t)^2\] \[w_{t+1} \leftarrow w_t - \dfrac{\eta}{\sqrt{\mathbb{E}[\nabla_w f(w)^2]_t+\epsilon}}\nabla_{w_t}f(w_t)\]여기서 $\eta=0.001$, $\gamma=0.9$를 권장하고 있다. 이렇게 하면 오래된 Gradient의 영향이 지수적으로 감소하게 되어, 분모가 무한히 커지는 문제가 사라지게 된다.
Adadelta
역시 Adagrad를 개선하기 위해 나온 방법 중 하나로, RMSprop의 아이디어에서 한 발 더 나아간다.
Adadelta에서는 SGD, Momentum, Adagrad 등 위에서 언급된 방법들은 모두 업데이트의 단위(unit)이 파라미터의 단위와 맞지 않다는 점을 지적하고 있다. 그리고 이를 해결하기 위해 과거 파라미터 업데이트 크기의 Exponentially Decaying Average도 따로 추적하여 계산하고, 이 값을 $\eta$ 대신 사용한다.
\[w_{t+1} \leftarrow w_t - \dfrac{\text{RMS}[\Delta w]_{t-1}}{\text{RMS}[\nabla_{w_t}f(w_t)]_t}\nabla_{w_t}f(w_t)\]여기서 $\text{RMS}$는 Root Mean Squared로, $\text{RMS}[x]=\sqrt{\mathbb{E}[x]+\epsilon}$을 의미한다. 결국 Adadelta에는 그동안 잘 설정했던 Learning rate $\eta$가 아예 필요없는 구조가 되었다.
Adam (Adaptive moment estimation)
Momentum과 RMSprop을 결합한 방식이다. Gradient의 1차 moment인 평균과 2차 moment인 제곱평균을 아래와 같이 동시에 추적한다.
\[m_t = \beta_1 m_{t-1} + (1-\beta_1)\nabla_w f(w)\] \[v_t = \beta_2 v_{t-1} + (1-\beta_2)\nabla_w f(w)^2\]여기서 $m_t$가 Momentum에 해당하고, $v_t$가 RMSprop에 해당한다. 위의 두 값 모두 0으로 초기화되기 때문에, 특히 학습 초기에, 그리고 $\beta_1$과 $\beta_2$가 1에 가까울수록 0으로 편향하는 성질을 지닌다.
이 편향을 해결하기 위해 아래의 Bias correction으로 보정한다.
$\hat{m}_t=\dfrac{m_t}{1-\beta_1^t}, \hat{v}_t=\dfrac{v_t}{1-\beta_2^t}$
각 변수들의 기본값은 $\beta_1=0.9$, $\beta_2=0.999$, $\epsilon=10^{-8}$이다. 그리고 최종적으로 업데이트는 다음과 같이 된다.
\[w_{t+1}=w_t-\dfrac{\eta}{\sqrt{\hat{v}_t+\epsilon}}\hat{m}_t\]AdamW
사실 이 내용은 수업때 다루진 않았으나, 요새는 이 AdamW가 표준이라 따로 조사하여 여기에 같이 정리한다.
Adam에 L2 regularization을 적용하면 손실함수는 아래의 형태를 가지게 된다.
\[\widetilde{E}(w)=E(w)+\dfrac{\lambda}{2}w^T w\]이 상태로 Gradient를 계산하게 되면 $\nabla\widetilde{E}(w)=\nabla E(w)+\lambda w$가 되고, 이 식이 그대로 Adam의 계산식에 들어가게 된다.
\[m_t=\beta_1 m_{t-1} + (1-\beta_1)(\nabla E(w) + \lambda w)\]그런데 Adam은 $v_t$에 쌓인 Gradient 크기로 Learning rate를 스케일링 하기 때문에, 자주 업데이트 된 파라미터일수록 Learning rate가 작아지게 된다. 여기까진 좋은데, 문제는 Weight decay 용도로 넣어놨던 $\lambda w$또한 이 영향을 같이 받게 된다는 점이다. 이는 Weight decay의 의도와 어긋나게 된다.
이를 해결하기 위한 방법이 2019년에 Loshchilov & Hutter에 의해 고안된 AdamW이다. AdamW는 아래와 같이 Weight decay를 Gradient와 완전히 분리했다.
\[w_{t+1}=w_t-\dfrac{\eta}{\sqrt{\hat{v}_t}+\epsilon}\hat{m}_t-\eta\lambda w_t\]이제야 비로소 모든 파라미터가 동일한 비율로 Weight decay를 겪게 된다. 그리고 앞에서도 언급했듯, 현재는 이 AdamW가 사실상 표준의 위치가 되어 특별한 사유가 없는 한 AdamW를 주로 쓰게 될 것이다. 사실 위에서 언급된 최적화 방법들 중 Momentum부터 Adam까지의 내용을 총망라한게 AdamW이기도 하다.