Deep Learning 1 - ML Overview
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Deep Learning 과목의 수업을 다룬다.
Machine Learning in a Nutshell
딥러닝은 머신러닝의 한 갈래이므로 머신러닝을 먼저 알아야 한다. 머신러닝 하면 떠오르는 대표적인 예시인 MNIST(Modified National Institute of Standards and Techonology)를 가져와보자. 여기의 데이터는 각각 28x28 크기의 이미지로 되어있다. 즉, 이미지 하나당 픽셀이 28 * 28 = 784개 존재하므로 784차원의 데이터이다.
이 이미지셋을 이용해서 손글씨를 인식하는 프로그램을 만드려고 한다. 그런데 전통적인 알고리즘으로는 손글씨를 숫자로 변환시키는 일반적인 Rule을 만들기가 매우 어렵다. 그 이유는 당연히 같은 숫자를 가리키더라도 모양이 다 조금씩 다르기 때문이다. 각각의 모든 경우에 대해 일일이 찾아내려고 해도 가능한 Variation이 너무 많아서 일반화가 어려운 상황이고, 이럴 때 머신 러닝을 쓰면 된다.
구체적으론, 다음과 같은 상황에서 머신러닝을 사용하면 효과를 볼 수 있다.
- 사람이 설명할 수 없는 경우: 음성 인식, 손글씨 등등 사람은 자연스럽게 하지만 “왜” 그게 되는지에 대해 명확한 이유를 설명할 수 없을 때
- 전문가가 존재하지 않을 경우: 사전 지식이나 이론적 배경이 없어서 모르지만 데이터는 존재할 때
- 솔루션을 알고는 있으나 시간에 따라 계속 변하는 경우
- 솔루션이 특정한 상황에 따라 달라져야 할 때: 성장함에 따라, 혹은 안경 등의 여부로 인한 변화를 캐치해야 하는 얼굴인식 같은 경우
전통적인 프로그램은 데이터(Input)과 알고리즘이 주어지면 그에 맞는 적절한 출력(Output)을 리턴하는 구조인 반면, 머신러닝은 Data와 이를 기반으로 한 Desired Output이 주어져 있고, 이들을 기반으로 패턴을 찾아 이 문제를 풀 수 있는 일반화된 Rule을 알아낸 후 이를 새로운 Input에 적용해서 답을 도출하는 방식이다.
아까의 그 손글씨 인식 문제로 다시 돌아가면, 데이터셋 $N$개를 준비한다. 여기서는 데이터 1개당 28x28 크기의 이미지, 즉 784차원의 벡터가 된다. 그리고 정답이 될 수 있는 집합 $\Large y$를 생각해본다. 여기서는 당연히 인식된 숫자, 즉 $\lbrace 0, 1, \ldots, 9 \rbrace$가 된다. 그리고 학습을 하기 위해 적절한 알고리즘, 즉 함수 $f(x)$를 정한다.
그런데 이 함수는 $x \Rightarrow f(x;\theta) \Rightarrow y$를 만족해야 한다는 것만 알고 어떻게 생겨야 하는지는 모른다. 다만 $\mathbb{R}^784 \rightarrow \lbrace 0, 1, \ldots, 9 \rbrace$가 되어야 한다는 것만 알 뿐이다. 여기서는 별 수 없이 가설을 세워서 하나하나 최적화를 해본 후 검증을 해야 한다. 그리고 Bayes classifier, CNN, SVM, Gaussian mixture model, Hidden Markov model 등이 전부 이 $f$의 형태를 의미한다.
그런데 위의 단계 사이에 하나를 더 끼워넣어야 한다. MNIST 데이터셋만 봐도 손글씨가 그려지지 않은 빈 공간 등이 존재하기 때문에 784차원의 모든 정보가 전부 유의미하진 않다. 이런 데이터들을 걷어내고 유의미한 부분만 추출해서 모델에게 줘야 모델의 부담이 줄어들 것이다. 이 과정을 Feature Extraction, 혹은 Feature Representation이라고 한다. 당연하지만 굳이 이런 명확한 부분이 아니더라도 각종 최적화 방법을 통해 데이터의 차원을 가능한 한 줄이려고 하는 노력들이 모두 포함된다.
즉, 전통적인 머신러닝의 Training 세션은 다음의 파이프라인을 따르게 된다.
- Collecting training samples - 데이터 수집
- Preprocessing - 노이즈 제거 등의 기본 전처리
- Feature extraction/representation - 차원 압축
- Feature selection - 유의미한 데이터 추출
- Classifier/regressor learning - 모델 선택 및 최적화
위의 과정을 거쳐 학습이 완료되었으면 다음의 순서로 Testing 세션을 수행하게 될 것이다.
- Given testing samples
- Preprocessing
- Featrue extraction/representation
- Feature selection
- Outputs from classifier/regressor
즉, 1~4 과정이 모두 동일하며, 5번도 사실상 같은 일을 하는 셈이다. 위의 전처리 과정들을 한번 정의해서 그대로 훈련시켰으면 실제로 추론을 할 때도 동일한 과정을 거쳐야만 한다는 의미이다.
Machine Learning Basics
그럼 이제 간단한 예시를 가지고 위의 과정들을 따라가보자.
목표는 $sin(2\pi x)$를 추정하는 것이다. 이를 위해 $0 ~ 1$ 사이의 랜덤한 수 10개를 뽑은 후, 그 각각의 값들에 대한 $sin$값을 계산하고, 거기에 Gaussian noise를 추가한다. 여기서 노이즈를 추가하는 것은 이론과 달리 실제 데이터는 노이즈가 끼어있는 경우가 많기 때문이다.
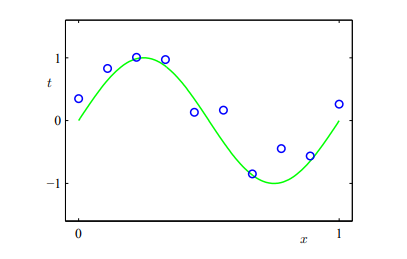
그러면 위와 같은 형태의 점 10개를 얻을 수 있다. 당연하지만 임의로 뽑힌 10개의 값, 그리고 노이즈의 상태에 따라 이 데이터셋은 달라질 것이다. 그리고 이 데이터들만 가지고, 즉 $sin(2\pi x)$에서 왔다는 사실을 잠시 잊고 원래의 함수를 찾는 것이다.
그럼 우선 해야할 것은 데이터의 특성을 파악해서 적절한 함수를 선정하는 것이다. 위의 데이터셋의 형태를 보면 적어도 선형 그래프는 아니라는 것은 확실하다. 그러면 가장 쉽게 생각할 수 있는 것은 아래와 같은 형태의 Polynomial function이 될 것이다.
\[y(x, w) = w_0 + w_1x + w_2x^2 + \cdots + w_Mx^M = \sum_{j=0}^{M}w_jx^j\]물론 이것은 가설이니 이게 정답인지 아닌지는 잘 모른다. 그렇기 때문에 여러 모델을 놓고 비교를 해야하며, 이를 Model Selection이라고 한다. 그리고 사실 위의 식에서 다항식의 차수 $M$ 또한 우리가 미리 결정해야 하는 사항이다. 당연히 $M$에 따라 함수의 형태가 달라지기 때문이며, 이 때문에 다양한 $M$에 따라 테스트를 하는 것으로 일단은 위의 과정을 갈음했다고 할 수 있을 것이다.
그런데 위의 함수의 형태를 다시 생각해보자. 분명 위 함수는 $x$에 대해선 Polynomial function이다. 그런데 우리가 구해야 하는건 $x$가 아니라 $w = \left[w_0, w_1, \ldots, w_M \right]^T$이다. 위 식을 $w$의 공간에서 생각해보면 이건 선형이다. 그렇기 때문에 이 모델은 Linear Model이라고 부르며, 사실 굉장히 간단한 형태가 된다.
다음으로 해야 하는 것은 얼마나 정확한지를 판단할 기준, 즉 Loss Function이다. 손실 함수의 디자인도 중요한 문제지만 여기서는 실제 값과 예측 값의 차이를 제곱한 값, 즉 MSE(Mean Square Error)로 계산할 것이다.
제곱을 취한 이유는 두 가지가 있는데, 하나는 이 상황에선 손실함수가 양수냐 음수냐가 그리 중요하지 않기 때문이고, 두번째는 손실함수가 미분이 가능해야 추후 계산하기 편하기 때문이다. 물론 음수로 떨어지는게 중요한 상황이라면 음수가 나오는 그대로 써는 것이 맞다. 음수를 없애는 방법 중 대표적인 다른 방법인 절댓값은 위의 미분가능성 문제 때문에 여기서는 쓰지 않을 것이다.
그러면 이제 전체 데이터셋에 대한 오차, 즉 Empirical Risk를 정의하면 다음과 같다.
\[E(w) = \dfrac{1}{2}\sum_{n=1}^{N} \left\lbrace y(x_n, w) - t_n \right\rbrace^2\]그리고 우리의 목표는 이 $E(w)$가 최소가 되게 하는 $w$를 찾는 것이고, 이제 이 문제는 최적화 단계로 넘어가게 된다.
여담으로, 딥러닝에 이르러서는 위의 과정을 1번만 하는 것이 아니라 여러 번 반복해서 수행한다고 한다.
그러면 이 문제를 어떻게 최적화시킬까? 우리가 정의한 함수의 형태는 $w$의 공간에서 Linear Function이고, 손실함수는 이 값을 제곱하는 형태다. 즉, 우리가 최적화해야 할 Empirical Risk는 결국 $w$에 대한 2차식의 형태가 된다. 그렇기 때문에 이 함수를 미분하면 0이 되는 지점을 쉽게 찾을 수 있고, 심지어 Unique하다. 그 값을 그대로 쓰면 된다. 이 과정을 수식으로 쓰면 아래와 같다.
\[\begin{aligned} E(w) &= \dfrac{1}{2}\sum_{n=1}^{N} \left\lbrace y(x_n, w) - t_n \right\rbrace^2 \\ y(x, w) &= \sum_{j=0}{M}w_j x^j \\ \dfrac{\partial E(w)}{\partial w_i} &= \sum_{n=1}^{N} \left\lbrace \sum_{j=0}{M} w_j x_n^j - t_n \right\rbrace x_n^i = 0 \\ \sum_{n=1}{N} \sum_{j=0}{M} w_j x_n^{i+j} &= \sum_{n=1}{N} t_n x_n^i \end{aligned}\]