Deep Learning 3 - CNN
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Deep Learning 과목의 수업을 다룬다.
Structured Data
저번 글에서 알아본 FNN 및 DNN은 기본적으로 입력을 벡터로 받고, 입력으로 들어온 학습 데이터 벡터의 모든 요소들 간의 상관관계를 학습한다. 그런데 때로는 이것이 비효율적인 경우가 존재한다. 이미지가 입력으로 들어오는 모델을 생각해보자.
이미지는 근본적으로 2D 데이터이기 때문에, 이를 모델에 넣으려면 1D 벡터로 바꿔야 한다. 그런데 그렇게 펼쳐진 벡터는 원래 이미지의 구조를 보존하지 않기 때문에, 원래 데이터의 각 픽셀 간의 correlation 역시 뭉개진다. 그리고 이렇게 뭉개진 정보를 MLP가 다시 찾아야 한다.
음성 신호로 바꿔서 생각해도 마찬가지이다. 음성은 시간을 기준으로 한 1D데이터인데, 이 시간축의 영향을 강하게 받는다. 즉, 상대적으로 시간 간격이 먼 요소끼리는 관련 있을 확률이 희박하다. 이 경우엔 기본적인 correlation이 뭉개지진 않지만, 이 시간축에 대한 정보를 MLP에게 줄 수 없어서 관계가 별로 없을 unit들 간의 관계도 찾으려고 시도하게 된다.
비디오의 경우는 한 술 더 떠서, 애초에 3D데이터이다. 각 픽셀은 이미지처럼 상하좌우의 픽셀과의 correlation이 존재하며, 음성처럼 근접한 시간의 같은 위치의 픽셀과도 correlation이 존재한다. 그러나 이를 모델에 학습시키기 위해 1D로 펴는 순간 미리 알고 있는 correlation에 대한 정보가 모두 소실되어, MLP에게 불필요한 학습을 강요하게 된다.
이렇게 데이터의 종류에 따라 이미 어느 정도의 구조나 속성을 내재하고 있을 수 있으며, 이러한 데이터를 Structured Data라고 한다. 그리고 이러한 데이터는 FNN이 아니라 다른 방식의 네트워크가 필요하다.
Convolutional Neural Networks
그러면 이러한 Structured Data를 학습시키기 위한 네트워크, 즉 Structured Network는 어떤 식으로 이루어져 있을까? 원래 입력의 크기를 알고 있으니 그에 맞게 그 주변 위치를 기준으로 생각해야 할 것이다.
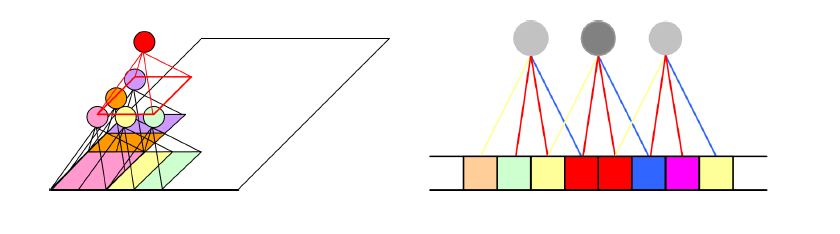
또한 그렇게 좁은 영역의 패턴을 탐지하는 Weights를 전체 입력 벡터에 걸쳐서 동일하게 적용해야 할 것이다. 그렇게 해야지 전체 입력 벡터에서 우리가 원하는 패턴이 얼마나 자주 등장하는지를 파악할 수 있기 때문이다. 이 개념을 Weights Sharing이라고 부른다.
위에서 논의한 개념이 잘 반영되어 있는 네트워크가 바로 Convolutional Neural Networks, 즉 CNN이다. 그럼 이 네트워크의 이름에 왜 “Convolutional”이라는 말이 붙었을까? 사실 Convolution 연산이라는 것은 굳이 AI에서만 사용되는 연산이 아니다. 원래 Convolution 연산은 신호처리나 확률론 등에서 원래 사용되던 것으로, 다음과 같이 정의된다.
\[(f\ast g)(t)=\int_{-\infty}^{\infty}f(\tau)\cdot g(t-\tau) d\tau\] \[(f\ast g)[n]=\sum_{k=-\infty}^{\infty}f[k]\cdot g[n-k]\]그러나 CNN에서의 Convolution 연산은 위의 정의를 그대로 쓰진 않고, 다음과 같이 변형해서 사용한다. 이를 엄밀하게는 Cross-correlation이라고 부른다.
\[(f\ast g)[n]=\sum_{k}f[k]\cdot g[n+k]\]즉, $g$를 flip하지 않고 그냥 슬라이딩하는 식으로 계산한다. 원래 Convolution 연산은 “현재 시점 $t$에 과거 신호가 얼마나 영향을 주는가”를 표현하기 위한 연산이라 뒤집힌 것인데, CNN에서는 그러한 개념은 필요가 없고, 어차피 패턴을 학습으로 찾아야 하기 때문이다. 즉, Flip해서 계산하나 그냥 계산하나 어차피 같은 결과가 나올 것이기 때문에 계산의 편의성을 위해 Cross-correlation 연산을 사용하면서 Convolutional Neural Networks라고 부른다.
각설하고, CNN에는 다음과 같은 3가지 특징이 있다.
Local receptive fields
데이터가 Local한 속성을 가지고 있으며 이것이 반복적으로 쓰일 때 CNN을 적용할 수 있다. 이미지가 대표적인 예시일 뿐이지 이미지에서만 사용되는 것은 아니다. 후술하겠지만 자연어에서도 적용할 수 있다.
Weights Sharing
앞에서 간단하게 알아봤듯이, 하나의 Convolutional filter를 입력 벡터 전체에서 사용한다. 그리고 우리의 학습 대상이 바로 이 filter이다. 이를 Kernel이라고 부른다.
Subsampling / Pooling
워낙에 입력 벡터가 거대하기 때문에 Convolution layer를 통과한 데이터를 다시 한번 압축할 필요가 있다. 이를 Subsampling, 혹은 Pooling이라고 부른다. 일반적으로 Convolution layer를 통과한 데이터에서, 이웃 영역 간의 최댓값, 최솟값, 혹은 평균 중 하나를 택하며, 그 중에서도 최댓값이 많이 쓰이는 편이다.
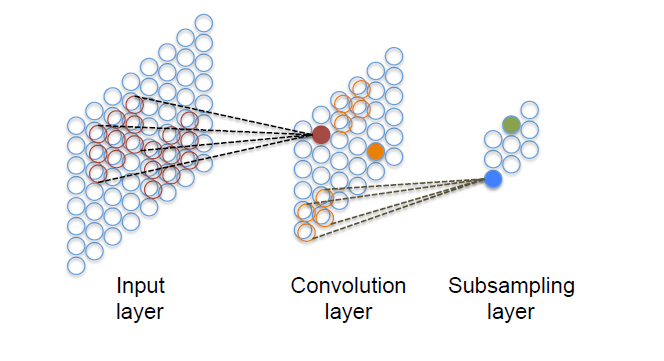
이것이 CNN의 전부이며, 그 과정을 그림 한 장으로 요약하면 바로 위의 그림과 같다.
A Concrete Example
그럼 간단한 예시를 통해 직접 CNN의 작동 과정을 확인해보자.
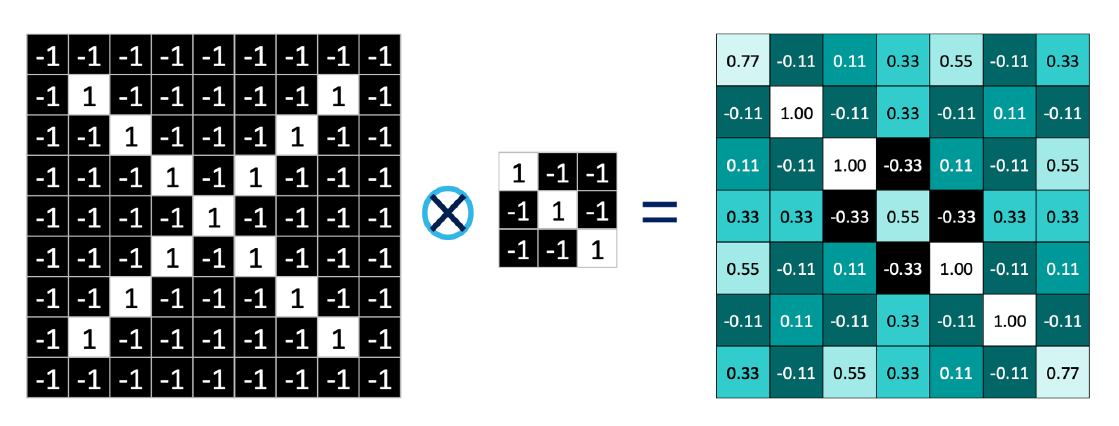
위의 그림은 이미 학습이 완료된 3x3 Kernel에 대해 Convolution 연산 및 평균을 적용한 결과이다. 원래는 9로 나누지 않으나, 얼마나 유사한지 확인하기 위해 편의상 Kernel 크기인 9로 나눠서 직접적으로 비교해보자. 또한 원본 크기는 9x9니까 연산 결과는 7x7이 나오게 된다. 만일 이런 식으로 사이즈가 약간 줄어드는 것이 싫다면 입력값 바깥에 0을 추가하는 Zero Padding을 통해 사이즈를 유지시킬 수 있다.
출력 벡터는 입력 벡터의 각 부분부분이 우리가 학습한 Kernel과 얼마나 일치하는지를 파악하는 지표이다. 즉 이미지의 특징을 파악하는 과정이라고 할 수 있다.
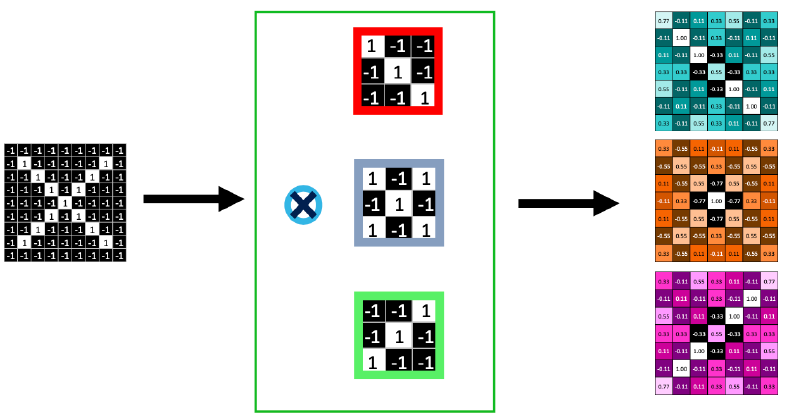
그런데 Kernel 하나를 찾는다고 끝나는 것은 아니다. 위 그림처럼 일반적으로 Kernel을 여러 개 준비해서, 동일한 입력에 대해 서로 다른 Kernel을 적용하게 된다. 이러한 결과물을 Feature Map이라고 부른다. 즉, 이미지의 여러 특징을 파악하기 위해 CNN을 사용하는 것이고, 그 “특징”을 어떤 것으로 잡을 것인지를 다양한 Kernel로 정하는 것이며 이미지의 특징을 잘 파악할 수 있도록 이 Kernel들을 학습시켜야 하는 것이다.
\[C_j=h(X\ast W_j +b_j)\]이를 수식으로 표현하면 위와 같다. 여기서 $\ast$는 앞에서 봤던 Convolution 연산이고, $b_j$는 Bias term으로 필요에 따라 넣을 수도 뺄 수도 있는 Desgin choice이다.

Convolution Layer를 통과한 이후엔 위와 같이 Pooling Layer를 통과시켜야 한다. 이 경우엔 인접한 2x2 영역 내의 Max Pooling을 적용한 것이다. 즉, Convolution Layer의 출력 벡터를 겹치지 않게 2x2영역으로 나눈 후 각 영역 중 가장 큰 값만 취해서 Pooling Layer의 출력 벡터로 삼은 것이다. 이러한 과정을 각각의 Feature Map에 대해서 수행한다.
Pooling의 목적은 계산해야 할 Feature Map의 크기를 줄이기 위한 것 말고도 한 가지가 더 있다. 이미지를 생각해보면 일차적으론 당연히 이웃 픽셀의 영향을 강하게 받지만, 그렇다고 다른 픽셀과의 관계가 아예 없는 것은 아니다. 이러한 고차원적인 관계를 파악하기 위한 빌드업 (즉, “Gradually build up further spatial and configural invaraince”)의 일환으로 Pooling을 수행한다.
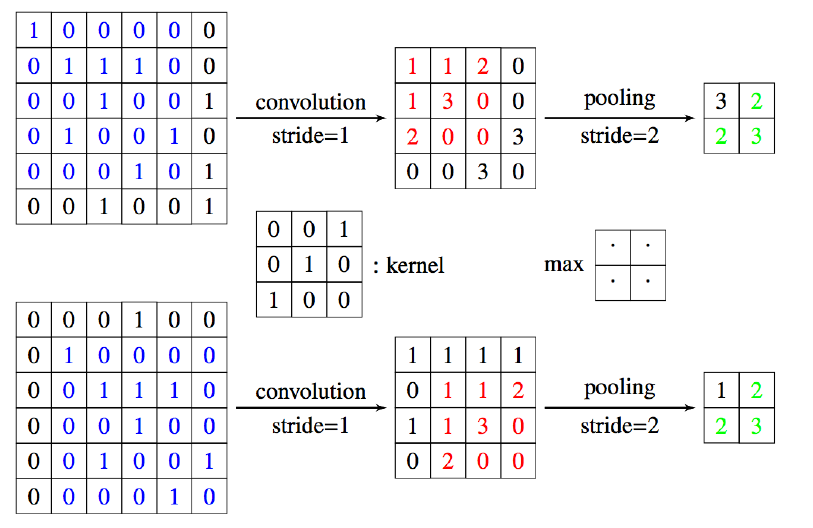
이것이 성립할 수 있는 이유는 “Translation Invariance”라는 특성 때문이다. 위의 그림에서는 2가지 케이스에 대해 동일한 Kernel과 Pooling을 적용한 결과를 나타낸 것이다. 여기서 “Stride”는 각 Layer를 계산할 때 한번에 얼마나 슬라이딩 하면서 계산했는지를 정하는 값이다.
파란색 영역은 완전히 동일한 값을 가지고 있는데, 그 영역이 Convolution Layer을 통과시켜도 위치만 다를 뿐 값은 동일하고, Pooling Layer를 통과시키면 결과로 나온 4개의 값 중 3개의 배열과 값이 동일하게 된다.
이게 무슨 의미일까? 위의 일련의 과정들이 주어진 벡터의 Minor한 이동의 영향을 받지 않는다는 의미이다. 사진을 생각해보면, 배열 자체가 동일하면 같은 것으로 취급하는 것이 맞을 것이다. 이러한 특성이 Pooling을 거쳐도 유지된다는 것이다.

물론 선형성을 제거하기 위해 FNN과 동일하게 Activation Function을 사용해서 비선형으로 만들어버린다. 일반적으로 CNN에서는 ReLU를 사용한다. 당연히 모든 Feature Map에 대해서 각각 다 적용해야 한다.
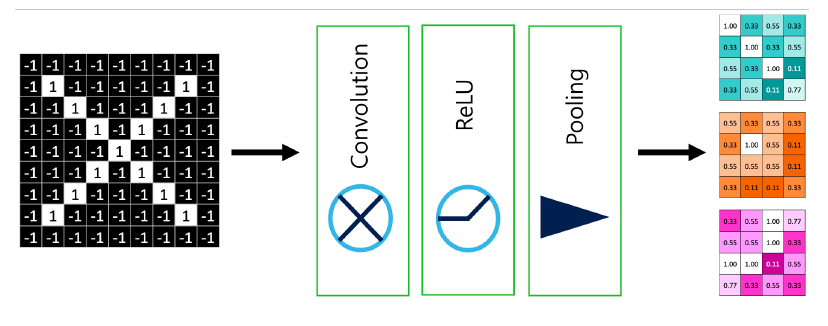
이를 이렇게 묶어서 표현하게 되며, 이 Convolution - ReLU - Pooling으로 이어지는 Layer들을 묶어서 “Convolution Block”이라고 부른다.
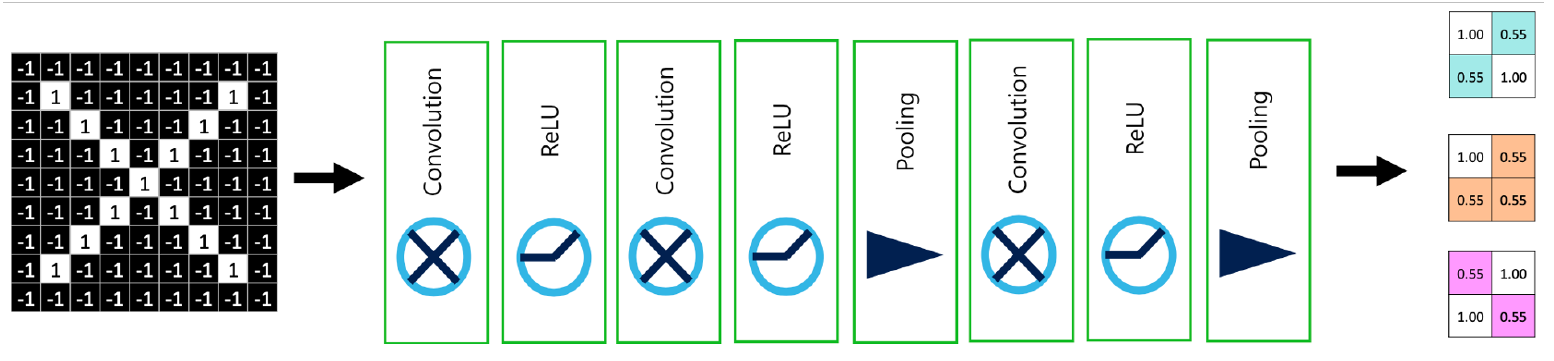
그리고 이를 여러 번 반복하면 위와 같은 형태로 이어질 것이다. 물론 각 Layer의 순서는 고정된 것이 아니다. Convolution - ReLU - Pooling의 순서를 반드시 지켜야 하는 것은 아니며, 심지어 필요에 따라서 일부 Layer를 생략할 수도 있다. 이것 또한 데이터의 특성에 의해 결정될 Desgin Choice라고 할 수 있다.
여하튼 위의 과정을 통해 이미지를 비롯한 거대한 입력 벡터를 특성을 최대한 보존하면서 차원을 줄이는 것이 CNN의 목적이라고 할 수 있다. 그렇게 얻어진 벡터들을 가지고 이제 문제의 상황에 맞는 다른 모델에 집어넣으면 된다. 위의 예시처럼 “O”, “X”를 구분하는 문제라면 마지막으로 나온 출력 벡터들을 입력 벡터로 간주하여 2-Class Classification 문제를 풀면 된다.
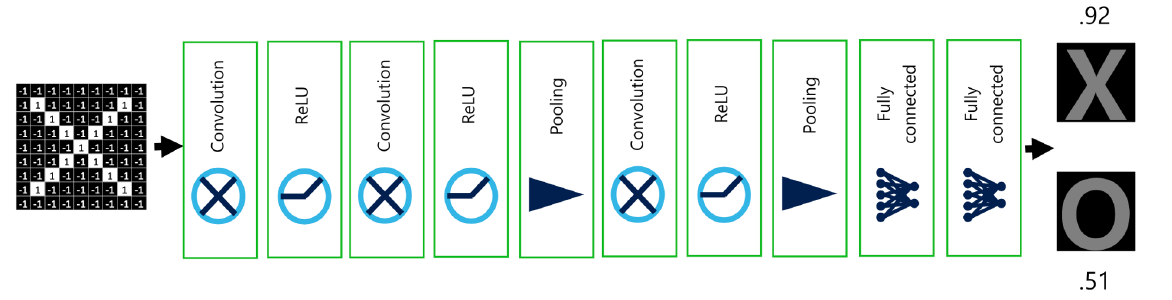
위의 전 과정을 그림으로 나타내면 위와 같다. 여기서는 Layer 2개짜리 FNN을 사용했다.
Use-case
그럼 몇 가지 실제로 사용했던 구조를 보면서 CNN을 어떻게 쓸 수 있는지를 파악해보자.
LeNet-5
LeNet-5는 1998년에 LeCun에 의해 제안된 구조로, 이미지 분류를 위한 CNN 아키텍쳐 중의 조상 정도의 위치에 해당한다. “5”라는 이름에서 알 수 있듯이 이것도 한번에 제안된 구조는 아니고, 버전이 계속 올라가면서 개선되었다. 아래 구조는 그 당시에 실제로 사용했던 구조이다.
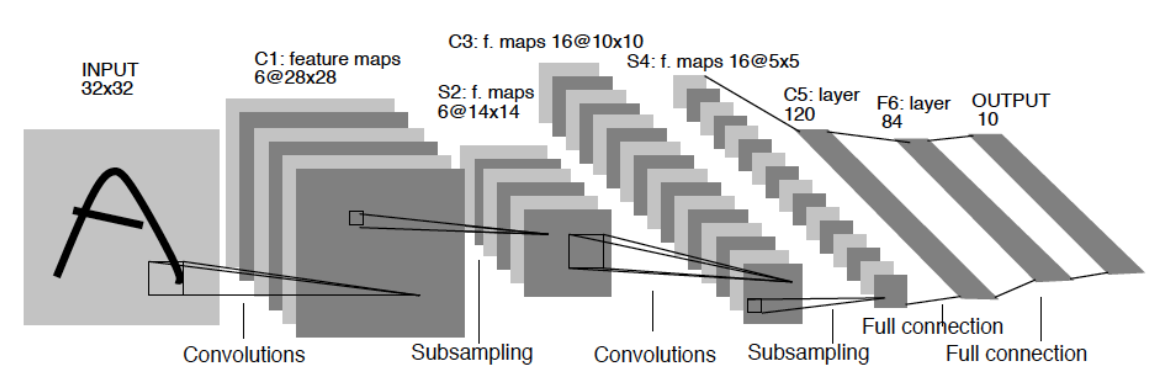
LeNet-5에서의 입력 벡터는 32x32 크기이고, 글자 인식을 위한 흑백 이미지라 RGB와 같은 별도의 채널은 없었다. 이를 첫 번째 Convolution Layer에서 5x5 Kernel을 6개 사용하여 28x28 크기의 Feature Map 6개를 얻는다. 그 후 2x2 Pooling Layer를 적용하여 각 Feature Map의 크기를 14x14 크기로 만든다.
두 번째 Convolution Layer에서는 이 14x14x6 크기의 벡터를 그대로 입력으로 삼아 5x5x6 Kernel을 16개 사용하여 10x10 크기의 Feature Map 16개를 얻는다. 역시 2x2 Pooling Layer를 적용하여 최종적으로 5x5 크기의 Feature Map 16개를 얻는다. 이렇게 얻어낸 400개의 숫자를 가지고 레이어가 3개인 FNN을 구성한다.
다만, 당시에는 첫 번째 Layer 또한 120개의 5x5x16 Kernel을 사용한 Convolution Layer로 구현되었다. 물론 구현 방식이 차이가 나는 것이지 사실상 Fully Connected Layer와 동일하다.
위의 구조에서 특이한 점은, 첫 번째 Convolution Layer에 비해 두 번째 Convolution Layer에서 Featrue Map의 개수가 훨씬 많다는 점이다. 커널의 개수를 채널이라고 부르는데, 일반적으로 크기가 줄어들수록 좀 더 복잡한 패턴을 찾기 위해 채널 수를 늘리는 경향을 보이게 된다. 물론 6이나 16이라는 숫자 자체에 특별한 수학적 의미가 있는 것은 아니다.
여담으로, 이러한 구조가 왜 제대로 동작하는가에 대한 이유는 LeNet-5가 제안된 당시에는 밝혀지지 않았다. 이에 대한 정확한 답은 2016년에 Yamins & DiCarlo에 의해 원숭이 뇌의 신호 처리 기전이 밝혀지면서 풀렸다. 즉, 위의 LeNet-5의 구조가 원숭이 뇌에서 일어나는 이미지 인식 기전과 상당히 유사하다는 것이 밝혀지면서 자연스럽게 CNN 또한 합리적인 구조라고 인정받게 되었다.
CNN in NLP
지금은 자연어를 처리하는 데에 CNN을 사용하진 않는다. 하지만 자연어 데이터 역시 CNN에서 필요로 하는 데이터의 특성에 잘 부합하기 때문에 이론상 CNN을 사용할 수 있으며, 실제로 과거엔 CNN 기반의 자연어 처리 또한 연구되었었다.
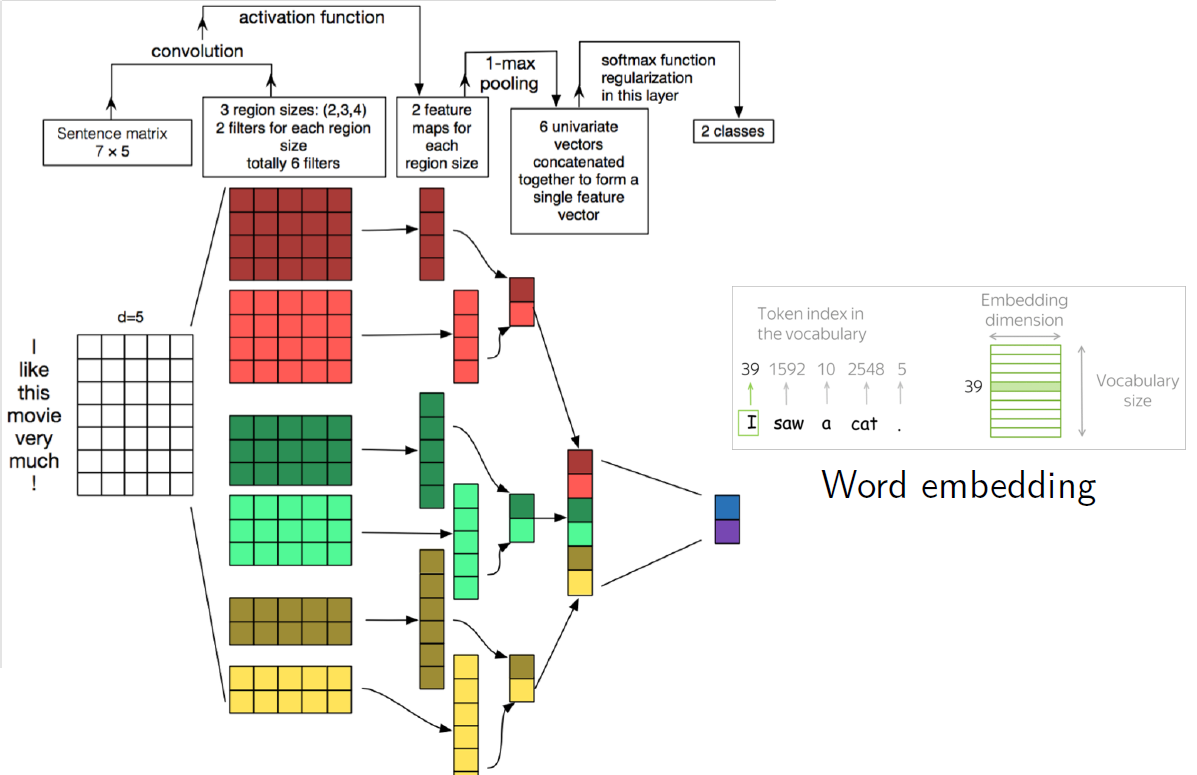
위의 예시는 Sentiment Analysis라고 해서, 각 문장이 긍정적인지 부정적인지를 판별하는 모델이다. 우선 입력값이 자연어이므로 이를 벡터로 바꿔야 한다. 이 기법을 “Word Embedding”이라고 하며, 위의 그림의 우측에 나와 있듯이 각 단어별로 이미 벡터가 정해져 있다. 위의 예시에서는 5차원 벡터로 사전 훈련되어 있는 상태이다.
이 경우 Kernel 크기를 정할 때, 반드시 $H \times 5$의 형태로 구성되어야 한다. 이 경우엔 저 5차원 벡터를 쪼개는 것이 데이터에 내재된 구조를 훼손하는 행위이기 때문이다. 또한 각 단어별로 Kernel 크기도 다르게 한 모습을 보이는데, 실제로 이래도 된다! 물론 크기가 일치하는 Feature Map끼리 묶어서 후속 연산을 해야 한다. 위의 두 특징을 제외하면 앞에서 봤던 LeNet-5와 구조 자체는 동일하다.
Case studies
그럼 이제 CNN 기반의 네트워크의 발전사를 매우 간략하게 톺아보면서 실제 CNN을 설계할 때 배워야 할 점을 얻어가보자. 이하의 각 네트워크를 전부 알아야 할 필요는 없고, 각각의 아키텍쳐 구조에서 배울 점만 얻어가도 충분하다.
AlexNet (Krizhevsky et al., 2012)
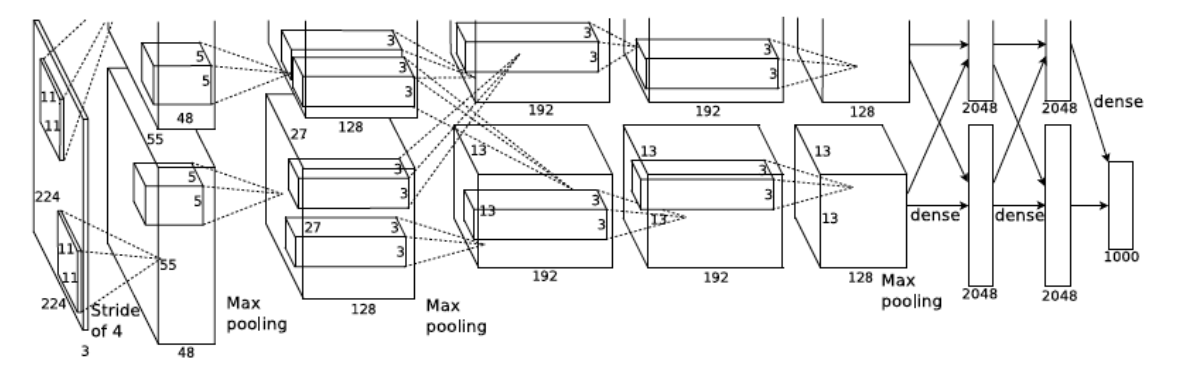
위의 그림은 2012년에 발표된 AlexNet의 구조이다. 앞에서 봤던 아키텍쳐랑 구조가 좀 다른데, 이는 당시 GPU 및 CUDA의 한계로 인해 완벽한 병렬처리가 불가능해서 그런 것이다. 그러한 제약 내에서의 해결책과 함께, AlexNet은 다음의 3가지 중요한 아이디어를 제시했다.
Activation function으로 $\tanh$ 대신 ReLU를 사용.
모든 Convolution Layer 및 Dense Layer(FNN) 뒤에 사용하면 효과가 더 좋다는 것을 밝혀냈었다.
Dropout의 활용
첫번째, 그리고 두번째 Dense Layer 뒤에 사용했었으며, 당시엔 Dropout rate를 0.5로 설정했었다.
Local Response Normalization (LRN)
LRN 자체는 몰라도 되지만, Normalization 개념에 대해서는 알아야 한다. 간단히 말해서, Layer의 출력 벡터를 다음 Layer의 입력 벡터로 그대로 사용하기 보다는, 이를 정규화시키고 넘기는 것이다. LRN은 현재는 사용되지 않지만, 이 Normalization의 중요성은 인정받아 Batch Normalization 등 다양한 정규화 테크닉이 등장했다.
VGGNet (Simonyan and Zisserman, 2015)
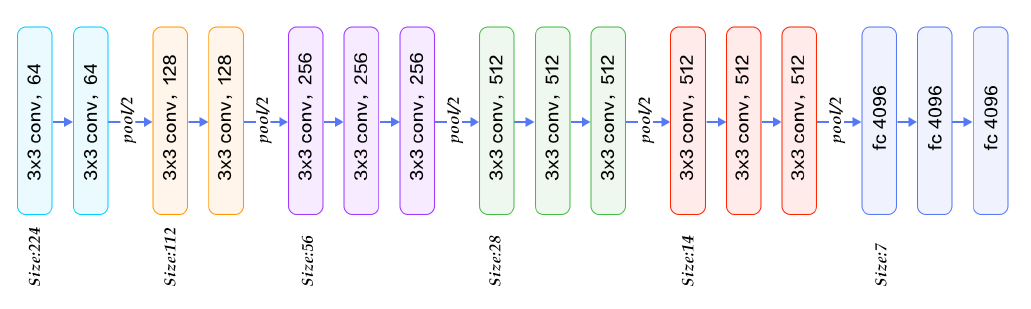
위의 그림은 VGGNet의 구조인데, 한 가지 특이한 점이 눈에 띈다. 바로 Kernel 크기를 3x3으로 확 줄이고 그만큼 Layer를 여러 겹 쌓았다는 점이다.
사실 CNN에서의 학습 대상이 Kernel이기 때문에 Kernel 크기가 클수록 우리가 학습해야 할 파라미터의 개수는 늘어나게 된다. 그래서 동일한 파라미터 수를 유지하려면 Kernel의 크기와 CNN의 깊이 간의 trade-off가 필요한데, VGGNet은 Kernel의 크기를 줄이고 CNN을 깊게 만드는 것이 더 학습에 유리하다는 것을 증명했다.
간단히 생각해보면, 3x3 Kernel 2개를 사용하면 Receptive Field, 즉 각 유닛 하나가 영향받는 영역의 크기는 5x5일 때와 동일하다. 그러나 파라미터는 전자는 18개, 후자는 25개를 사용하여 더 적어지고, 심지어 ReLU가 한 번 더 들어가서 비선형성도 추가된다. 이러한 차이로 인해 Kernel 크기를 줄이고 깊이를 늘리는 것이 학습에 더 유리한 것이다.
심지어 VGGNet 내에서도 Convolution Layer 및 Dense Layer의 개수에 따라 VGG-11, VGG-13, VGG-16, VGG-19 등으로 나눠서 실험했는데, 결국 Layer의 수가 가장 많은 VGG-19가 가장 Generalization이 잘 된다는 것 또한 증명되었다.
GoogLeNet / Inception-v1 (Szegedy et al., 2015)
GoogLeNet에서는 Inception이라는 특이한 개념이 나온다. 이 Inception은 1x1 Convolution을 뜻하는데, 얼핏 생각해보면 이게 무슨 의미가 있는지 의문이 간다. 그러나 위에서 살펴본 몇 개의 CNN 기반 아키텍쳐들은 전부 채널이 복수 개로 지정되었다는 점을 생각해보자. 각각의 Convolution Layer를 통과할 때마다, 채널 개수는 우리가 임의로 지정할 수 있다.
즉, 1x1 Convolution은 서로 다른 채널 간의 같은 위치의 값을 섞어버리는 연산이 되며, 이는 곧 차원 수를 줄이면서 복잡도를 높이는 테크닉이 된다. 즉, Layer를 넘어가기 전에 위와 같이 1x1 Convolution Layer를 추가로 덧붙이는 식으로 쓸 수 있다.
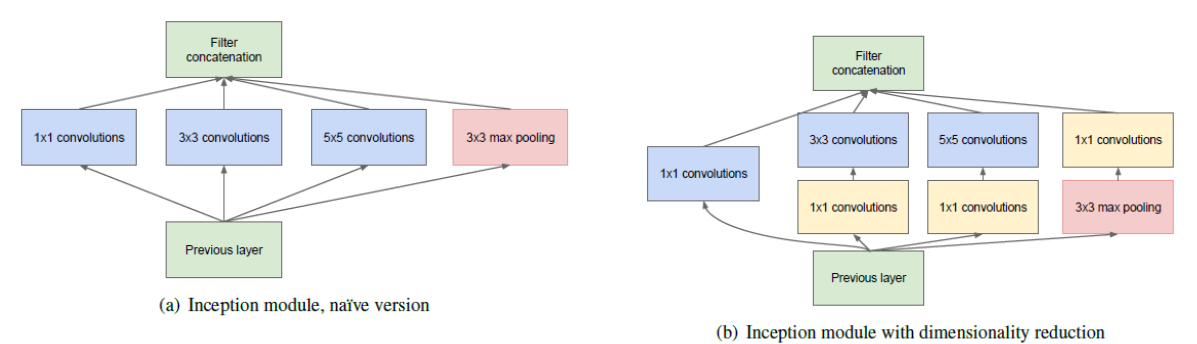
또한 이 개념을 발전시켜서, 위 그림과 같이 1x1, 3x3, 5x5 Convolution Layer를 병렬로 수행하고 이를 합치는 모듈이 제시되었는데, 이를 Inception Module이라고 부른다. 물론 이 경우에도 3x3, 5x5 Convolution Layer 앞에 1x1 Convolution Layer를 덧붙일 수 있다.
BN-Inception / Inception-v2
Inception-v2는 앞에서 언급한 Batch Normalization에 Inception Module을 적용한 아키텍쳐이다. Batch Normalization을 추가함으로써 학습 속도를 비약적으로 단축시킬 수 있었다. 앞 Layer의 파라미터가 바뀔 때마다 분포가 계속 바뀌어 학습하기 난해한데, 정규화를 시키면 우리가 정한 분포로 고정시킬 수 있기 때문이다.
Inception-v3 (Szegedy et al., 2016)
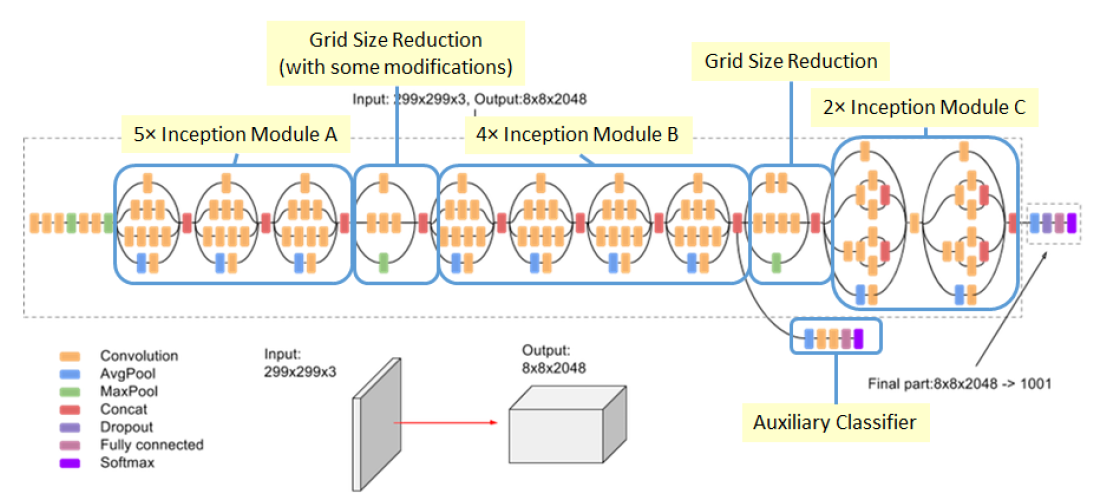
Inception-v3에서는 다음의 3가지 주요한 테크닉들이 제안되었다.
Auxiliary Classifier
위의 다양한 기법들을 도입하면서, 심지어 VGGNet에서 Layer를 깊게 쌓는 것이 좋다는게 증명되면서 갈수록 Layer를 깊게 쌓게 되었는데, 그러다보니 학습 속도가 너무 느리다는 문제가 있었다.
이를 해결하기 위한 방법을 모색하던 중, 어차피 CNN의 목적이 입력의 Discriminative Feature를 찾는 것이므로, 기본적인 CNN 아키텍쳐의 사이사이에 간헐적으로 Classifier를 끼워넣자는 발상을 떠올리게 되었다. 이것을 Auxiliary Classifier라고 부른다.
Factorization
앞서 VGGNet에서는 Convolution Layer의 Kernel 크기를 작게 만드는 것이 유리하다고 했는데, 구체적으로 3x3 크기를 사용했었다. 3x3이면 9개의 파라미터가 필요하다는 뜻이 된다. Factorization은 이 3x3 Kernel을 3x3 그대로 쓰지 말고, 1x3과 3x1로 나눠서 사용하면 파라미터는 총 6개만 사용해도 동일한 효과를 얻을 수 있다는 내용이다.
Label Smoothing
Label Smoothing은 아키텍쳐 설계에 관련된 기법이 아니고 Regularizaiton과 관계된 내용이다. 데이터셋을 준비하면서 Label을 정할 때, 0.00, 1.00과 같이 너무 극값을 주기보다는 0.01, 0.99와 같이 지정해서 주는 것이 학습이 더 잘 된다는 내용이다.
Inception-v4 (Szegedy et al., 2017)
Inception-v3의 구조를 더욱 복잡하고 깊게 적용시킨 아키텍쳐이다.
ResNet (He et al., 2015)
위에서 언급한 모든 테크닉들은 전부 네트워크를 깊게 하는 방향을 제시했다. 그런데 네트워크의 깊이가 깊어질수록 Vanishing / Exploding Gradient Problem을 고려하지 않을 수가 없는데, 실제로 Layer가 너무 깊으면 오히려 학습이 잘 되지 않는 현상이 발생했었다.
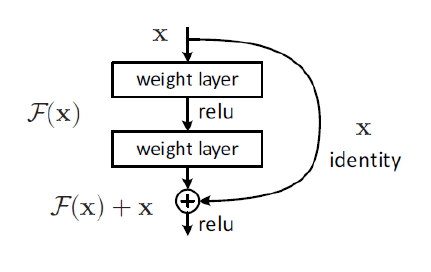
ResNet은 이러한 Gradinet Problem을 해결하기 위해 고안된 네트워크로, 기본적인 아키텍쳐 구조에 더해 일종의 Shortcut을 만드는 것이다. 이를 Residual Connection이라고 부르는데, 이 Shortcut을 통해 Gradient가 끝까지 잘 흘러들어가서 결국 깊은 Layer 구조에서도 학습이 잘 되게 되었다.
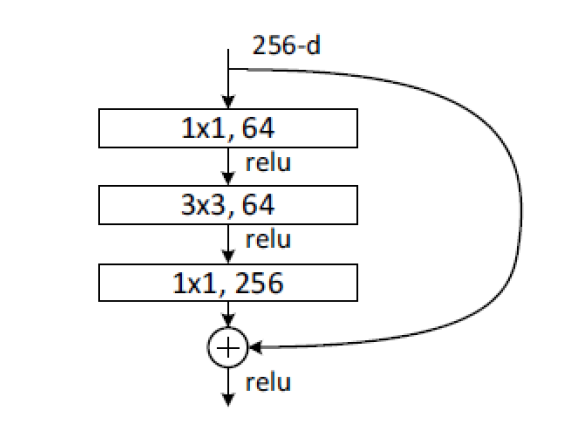
그리고 위의 구조는 Residual Connection에서 조금 더 발전하여, 왼쪽의 Convolution Layer도 앞뒤에 1x1짜리 Network-in-Network를 사용하여 차원을 줄인 후 늘리는 구조이다. 이를 Bottleneck Design이라고 한다.
여담으로, ResNet이 최초로 발표되었을 땐 1저자조차도 학습이 더 잘 되는 이유를 몰랐다고 한다. 그는 이를 창피하게 여겨 약 1년간 이 이유에 대해 연구해, 그 다음 해에 이에 대한 논문을 다시 발표했었다. 이 때 제시한 이유는 모델에 입력값 $x_l$이 추가적으로 더해지게 되니 역전파 과정에서 해당 부분이 상수 1로 바뀌게 되고, 이로 인해 “활성화 함수들의 도함수의 최댓값이 1을 초과하지 못해 항상 레이어를 지날수록 0에 수렴하는 문제”를 항상 1을 더함으로써 해결할 수 있다는 것이다.
Wide Residual Net (Zagoruyko et al., 2016)
ResNet의 구조를 발전시켜, 각 Residual Block의 채널 수를 늘리고 깊이를 줄인 아키텍쳐이다.
ResNeXt (Xie et al., 2017)
위에서 살펴본 GoogLeNet에서 제시된 다양한 개념들을 ResNet 구조에 적용시킨 아키텍쳐로, 여기서는 “Cardinality”라는 개념이 도입되었다.
DenseNet (Huang et al., 2017)
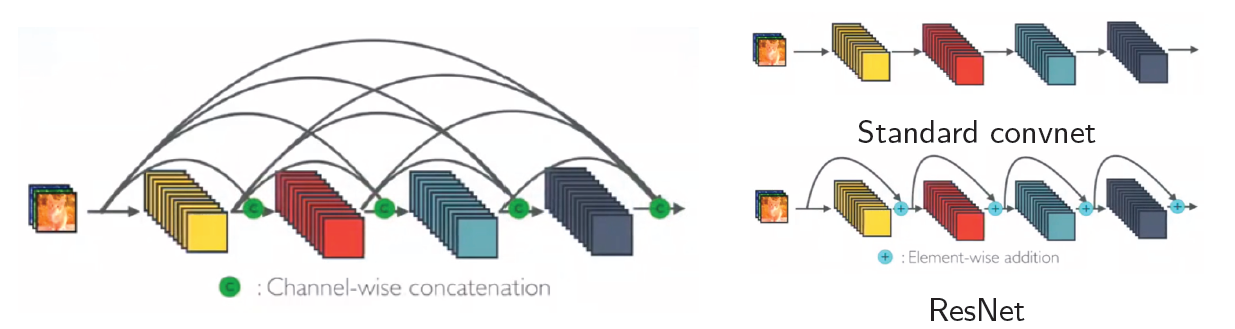
위의 그림에서 알 수 있듯이, ResNet의 구조를 발전시켜서 모든 Layer간에 전부 Skip Connection을 추가한 것이다. 그런데 이런 식으로 네트워크가 구성되려면 Convolution Layer를 통과시킨 후의 크기가 원본과 동일해야 하며, Pooling 또한 적용할 수 없다.
그렇기 때문에 이러한 DenseNet 구조를 전체 아키텍쳐에 적용하는 것이 아니라, 크기가 동일하게 유지되는 구간에서만 적용하는 식으로 디자인된다.
그래서 위의 구조를 “Dense Block”이라고 부르며, 이 Dense Block 내에서는 모든 Layer의 입력과 출력 크기가 동일해야 한다.
Multi-Scale DenseNet / MSDNet (Huang et al., 2018)
DenseNet의 변형으로, 여러 Scale의 Feature Map을 동시에 유지하면서 학습한다.
Squeeze-and-Excitation Network / SENet (Hu et al., 2018)
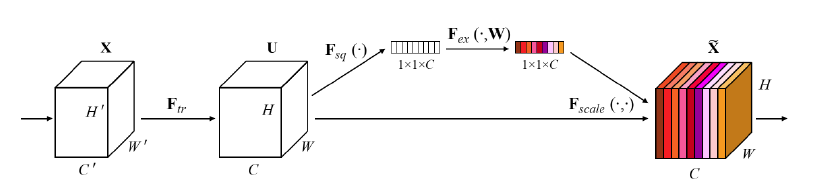
Squeeze-and-Excitation Networks, 줄여서 SENet은 Attention이란 개념이 등장한 이후 CNN에 적용된 아키텍쳐이다. CNN의 기본 구조를 생각해보면, 하나의 Convolution Layer에서 Feature Map을 여러개 학습하지만 이 각각의 Feature Map들은 각각 독립적이다. SENet은 이것을 문제삼은 것으로, 각각의 Featrue Map들의 중요도를 체크하자는 것이다.
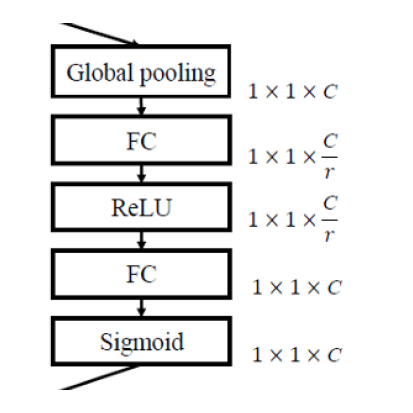
이를 위해 다음의 3단계로 나눠서 수행한다.
Squeeze
\[z_c=F_{sq}(u_c)=\dfrac{1}{H\times W}\sum_{i=1}^{H}\sum_{j=1}^{W}u_c(i,j)\]Feature Map의 중요도를 계산하기 위해서, 각각의 Feature Map별로 계산된 모든 원소값의 평균을 취한다. 이것이 채널 개수 C개만큼 나올 것이니 이 중요도 벡터의 크기는 1xC가 된다. 이 과정이 Global Pooling이다.
Excitation
\[s=F_{ex}(z,W)=\sigma(g(z,W))=\sigma(W_2ReLU(W_1z))\]Global Pooling으로 얻은 정보를 통해 각 Feature Map의 중요도를 계산하기 위해서, 마지막에 Sigmoid를 통과시키는 간단한 네트워크를 구성한다. FNN - ReLU - FNN - Sigmoid의 Bottleneck 구조로 되어 있다.
Rescaling
\[\tilde{x}_c=F_{scale}(u_c,s_c)=s_c\cdot u_c\]Excitation 단계에서 구한 각 Feature Map별 가중치를 각각의 Feature Map에 곱한다.
결과적으로 매우 적은 파라미터를 추가해서 각 Feature Map 별 상대적 중요도를 확인할 수 있게 하는 테크닉이다. 그리고 당연히 여기에 Inception Module 및 ResNet을 추가시켜보는 실험도 진행됐었으며, 각각 SE-Inception, SE-ResNet이라고 부른다.
ShuffleNet (Zhang et al., 2018)
경량 환경을 위한 아키텍쳐로, Group Convolution이란 개념으로 계산량을 줄이고, 서로 다른 그룹 간의 정보 교환이 이루어지지 않는 문제를 Channel Shuffle 연산으로 해결했다.
Network-in-Network
Inception Module이 등장하기 전에 도입된 개념으로, 다음 Layer로 넘어갈 때 작은 Network를 하나 붙여서 복잡도를 높이자는 취지로 사용되었다.
Xception (Chollet et al., 2017)
Xception은 Extreme Inception의 줄임말로, Inception Module의 아이디어를 극한까지 활용하여, 모든 Convolution을 Depthwise Separable Convolution으로 대체한 아키텍쳐이다.
Residual Attention Network (Wang et al., 2017)
Squeeze-and-Excitation Network는 채널 단위로 Attention을 적용한 것인데, Residual Attnetion Network는 여기에 더해 공간적 Attnetion을 같이 적용한 아키텍쳐이다.
U-Net (Ronneberger et al., 2015)
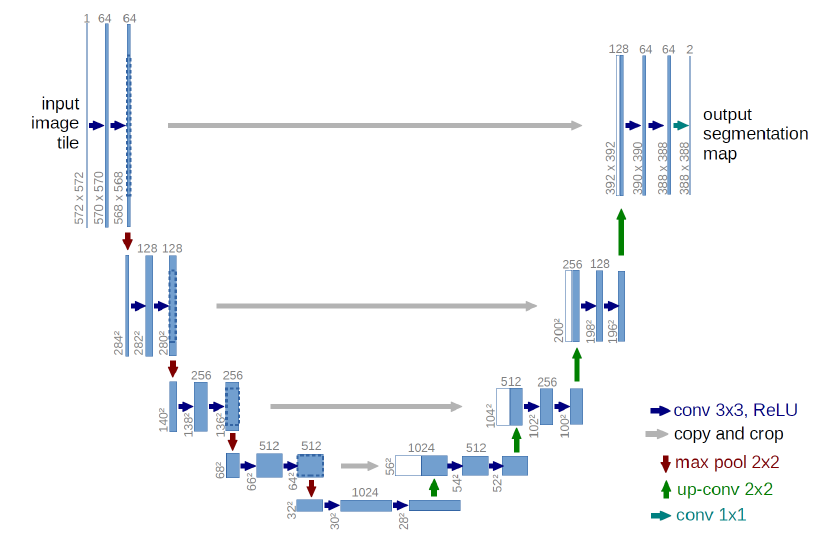
U-Net은 컴퓨터 비전 쪽이 아니라 의료 영상 이미징에서 제시된 아키텍쳐로, 현재 생성형 AI 중 Diffusion 계열의 모델들의 기본적인 구조로 아직까지도 사용되고 있다.
U-Net의 목적은 이미지를 만드는 것, 즉 생성형 AI이다. 그렇게 하기 위해서 CNN을 활용하여 입력 이미지를 1x1 크기의 1024 채널로 줄인 후, 이를 바탕으로 다시 원래 크기까지 복원시키는 구조를 취한다. 이러한 복원 구조를 “Deconvolution”이라고 부른다.
그런데 이런 식으로 복원하는 과정에서 그냥 복원해버리면 Convolution 과정에서의 정보 손실이 너무 크기 때문에 제대로 복원되지 않는 문제가 생긴다. 그래서 동일 단계에서의 정보, 즉 같은 크기의 정보를 그대로 가져와서 이를 참조하겠다는 것이 U-Net의 핵심 아이디어이다.
CUMedVision (Chen et al., 2016)
의료 영상 Segmentation을 위한 아키텍쳐로, U-Net과 유사하게 Encoder-Decoder 구조를 취하면서 Multi Scaling Context 정보를 활용한다.