Linear Algebra 2 - Statistical Model
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Linear Algebra 과목의 수업을 다룬다…만, 과목명은 페이크고 사실은 생성형 모델을 다루는 수업이다.
Conditioning
Conditional PDF는 특정 사건이 주어졌을 때의 확률밀도함수로, 아래와 같이 표현할 수 있다.
\[P(X \in B|A) = \int_B f_{X|A}(x)dx\] \[f_{X|A}(x|A) = \begin{cases} \dfrac{f_X(x)}{P(X \in A)} & \text{ if } x \in A, \\ 0 & \text{ otherwise} \end{cases}\]그리고 특정 사건 하에서의 전체 확률의 합은 1이 되어야 하므로, 해당 구간은 원래의 PDF보다 값이 더 높게 나온다. 이는 위의 정의에서만 봐도 알 수 있다. 분모 $P(X \in A)$는 확률이라 항상 1보다 작기 때문이다.
Conditional PDF에서도 경우에도 기댓값의 정의와 성질은 원래의 PDF와 동일하게 성립한다.
\[E[X|A] = \int_{-\infty}^{\infty} xf_{X|A}(x)dx\] \[E[g(x)|A] = \int_{-\infty}^{\infty} g(x)f_{X|A}(x)dx\]Multivariate Random Variables
여태까지 확인한 Random Variable 및 관련된 모든 개념, 정의, 성질들은 전부 단일 변수에 대해서만 고려되었었다. 그런데 실제로 머신러닝에서는 입력될 Random Variable의 개수가 상당히 많다. 이미지만 해도 각각의 픽셀별로 하나의 차원을 이루게 되는데, 이러한 것들이 전부 단일 분포의 Random variable로 들어가게 된다. 즉, 우리는 Multivariate random variables를 다뤄야 한다.
간단하게 2개의 변수에 대한 PDF는 다음과 같이 정의할 수 있다.
\[P((X,Y) \in B) = \underset{(x,y)\in B}{\int\int}f_{X,Y}(x,y)dxdy\]당연히 각 변수마다 별도의 값의 범위를 가질 수 있어서, 해당하는 영역의 확률을 알고 싶다면 그 구간을 잡고 적분하면 되며, 역시 전체 범위에 대해서 적분하면 1이 된다.
\[P(a \leq X \leq b, c \leq Y \leq d) = \int_{c}^{d} \int_{a}^{b} f_{X,Y}(x,y)dxdy\] \[\int_{-\infty}^{\infty} \int_{-\infty}^{\infty} f_{X,Y}(x,y)dxdy = 1\]다만 Random variable이 여러 개가 되면서 Univariate에서는 볼 수 없는 개념이 하나 있는데, Marginalization이다. 이는 여러 개의 random variable 중 일부에 대해서만 보겠다는 것이고, 보지 않을 random variable에 대해서는 전체 구간 적분을 취하면 된다.
\[P(X \in A) = P(X \in A \text{ and } Y \in (-\infty,\infty)) = \int_{A} \int_{-\infty}^{\infty} f_{X,Y}(x,y)dydx\]이렇게 해서 Multivariate random variable에서도 우리가 원하는 변수에 대해서만 확인할 수 있다.
\[f_X(x) = \int_{-\infty}^{\infty}f_{X,Y}(x,y)dy, f_Y(y) = \int_{-\infty}^{\infty}f_{X,Y}(x,y)dx\]또한 Random Variable 중 일부를 기준으로 한 Conditional PDF를 생각해볼 수 있다. 위에서의 Conditional PDF와는 다르게, 그 특정 사건조차 우리의 통제 하에 놓여있는 것이니 확실히 쓰기 편해진다. 정의 및 성질 등은 Conditional PDF와 동일하다.
\[f_{X|Y}(x|y) = \dfrac{f_{X,Y}(x,y)}{f_Y(y)}\] \[\int_{-\infty}^{\infty}f_{X|Y}(x|y)dx = 1\] \[P(X \in A | Y = y) = \int_{A} f_{X|Y}(x|y)dx\]그리고, Independent라는 개념이 있다. 모든 Random variables에 대한 PDF(즉 Joint PDF)가 각각의 marginal PDF의 곱으로 표현되면 이 random variables를 서로 독립이라고 부른다.
\[f_{X,Y}(x,y)=f_X(x) f_Y(y), \text{ for all } x,y\]이 경우에는 아래의 성질들이 성립한다. 사실 각각의 정의를 기반으로 위의 식을 집어넣으면 그대로 나오긴 한다.
\[f_{X|Y}(x|y) = f_X(x), E[g(X)h(Y)] = E[g(x)]E[h(y)]\]Multivariate Gaussian Random Variable
그러면 가우시안 분포를 다변량으로 확장해서 생각해보자. 가우시안 분포답게 평균과 분산을 알면 형태가 그대로 정해진다. 그러나 확률 변수가 여러개이므로 평균은 벡터로, 분산은 공분산의 행렬로 표현된다.
\[\mu = E[X] = (E[X_1], E[X_2], \ldots, E[X_d])^T, \Sigma_{i,j}=E[(X_i-\mu_{i})(X_j-\mu_{j})]=\text{Cov}[X_i,X_j]\]이런 평균과 공분산을 만족하는 $X=(X_1,\ldots,X_d)^T$에 대한 가우시안 분포를 $X \sim \mathcal{N}(\mu,\Sigma)$로 표현한다.
실제로 다변량 가우시안 분포의 PDF는 다음과 같이 표현된다.
\[f_X(x) = \dfrac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}}\exp(-\dfrac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu))\]구체적으로 2차원이라면 다음과 같이 표현되고, $\mu$, $\Sigma$는 다음과 같은 벡터 및 행렬로 나타내진다.
\[\small f(x,y) = \dfrac{1}{2\pi \sigma_X \sigma_Y \sqrt{1-\rho^2}}\exp\left(-\dfrac{1}{2(1-\rho^2)}\left[\left(\dfrac{x-\mu_X}{\sigma_X}\right)^2 - 2\rho\left(\dfrac{x-\mu_X}{\sigma_X}\right)\left(\dfrac{y-\mu_Y}{\sigma_Y}\right) + \left(\dfrac{y-\mu_Y}{\sigma_Y}\right)^2\right]\right)\] \[\mu = \begin{pmatrix} \mu_X \\ \mu_Y \end{pmatrix}, \Sigma = \begin{pmatrix} \sigma_X^2 & \rho \sigma_X \sigma_Y \\ \rho \sigma_X \sigma_Y & \sigma_Y^2 \end{pmatrix}\]위의 식들을 외우거나 할 필요는 없지만 2차원 가우시안 분포가 어떻게 생겼는지는 확인해보고 넘어가자.
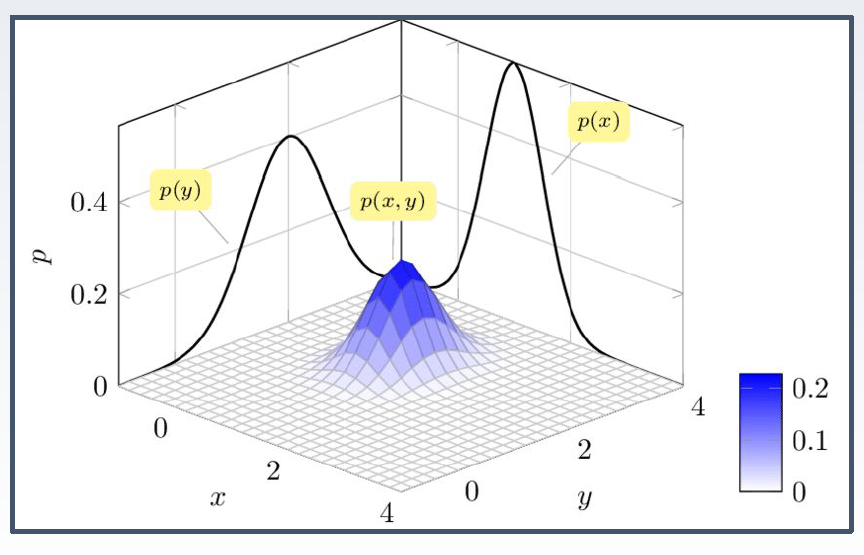
그리고 이걸 위에서 내려다본 모양은 아래와 같이 나온다.
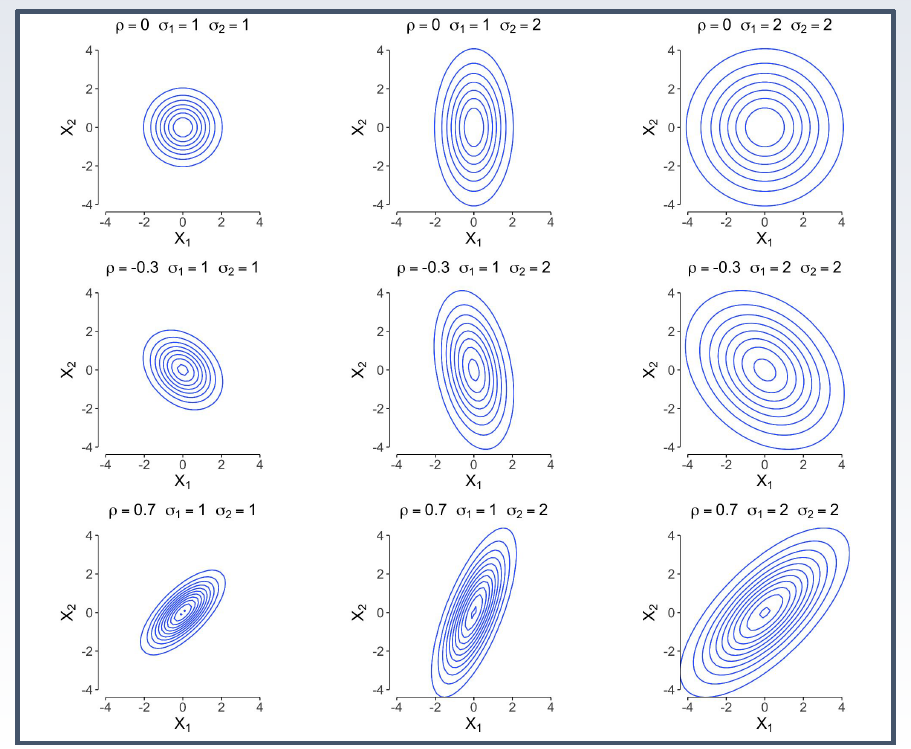
추가적인 변수 $\rho$는 상관 관계를 의미하며, 이 값에 의해 회전의 방향이 변한다. 구체적으로 $\rho \lt 0$이라면 좌측으로 회전하며, $\rho \gt 0$이라면 그 반대가 된다. 정확히 $\rho=0$이라면 회전하지 않는다. 또한 각 $\sigma$의 값의 크기에 따라 해당 축으로 얼마나 커지는지를 나타낸다.
Type of Convergence
모든 논의를 시작하기에 앞서, Random Variable에서의 수렴부터 짚고 넘어가자. 크게 아래의 4가지 수렴 방식이 있다.
Almost Sure Convergence
\[X_n \overset{a.s.}{\longrightarrow} X \Leftrightarrow P(\lim_{n \to \infty}X_n = X) = 1\]말 그대로 “거의 모든 경우에서” 함수가 수렴하는 경우다. Sample path 관점으로 보며, 가능한 모든 시행 결과 $w$ 중에서 $X_n(w) \to X(w)$가 성립하지 않는 $w$의 집합의 확률이 0이다.
Convergence in Probability
\[X_n \overset{P}{\longrightarrow} X \Leftrightarrow \lim_{n \to \infty}P(|X_n - X| \gt \epsilon) = 0, \forall \epsilon \gt 0\]$n$이 커질수록, $X_n$과 $X$의 차이가 $\epsilon$보다 클 확률이 0에 수렴한다. 즉, 각 시점에서의 확률만 보고, Sample path 전체를 추적하지 않는다.
Convergence in Mean Square
\[X_n \overset{m.s.}{\longrightarrow} X \Leftrightarrow \lim_{n \to \infty}E[(X_n - X)^2] = 0\]기댓값을 비교한다. $X_n$과 $X$의 차이를 제곱한 평균이 0으로 수렴한다. 즉 손실함수로 주로 쓰이는 MSE와 동일한 개념이다. 위의 수렴 방법은 아래와 같은 일반화된 수렴이 존재하며, 이를 $L^p$ 수렴이라고 한다.
\[X_n \overset{L^p}{\longrightarrow} X \Leftrightarrow \lim_{n \to \infty}E[|X_n - X|^p] = 0, p \geq 1\]Convergence in Distribution
\[X_n \overset{d}{\longrightarrow} X \Leftrightarrow \lim_{n \to \infty}F_{X_n}(x) = F_X(x), \forall x \text{ where } F_X \text{ is continuous}\]여기서의 $F_X$는 CDF이다. 즉, Random variable 자체가 수렴하는 것이 아니라, 각 Random variable의 CDF가 가까워지는 수렴이다.
그리고 재밌게도, 위의 수렴들은 강도 관계가 존재한다. 우선 Convergence in Distribution이 가장 약하다. 이쪽은 $X_n$과 $X$의 CDF만 수렴하면 되므로 둘이 같은 확률공간에 있을 필요조차 없다.
그 다음으로는 Convergence in Probability가 약한데, 각 시점에서의 확률이 수렴하면 되기 때문이다. 즉, 확률변수의 모든 경로가 수렴할 필요가 없다.
Almost Surely는 모든 경로가 수렴할 것을 요구하기 때문에 위 둘보다 강하다.
Convergence in Mean Square, 혹은 $L^p$ 수렴은 Convergence in Probability보다는 강하지만 기댓값이 수렴한다는 특성상 Almost Surely와는 서로 다른 방향에서 수렴하기 때문에 둘 사이의 강도는 일방적으로 정의할 순 없다.
LLN & CLT
또 다음의 중요한 정리 2개를 보자. 모든 확률변수 $X, X_1, X_2, \ldots, X_n$은 “iid”인(즉 서로 독립적인) 확률변수들이며, $\mu=E[X]$, $\sigma^2=V[X]$라고 하면 다음이 성립한다.
Law of large numbers
\[\bar{X}_n := \dfrac{1}{n}\sum_{i=1}^{n}X_i \overset{P, a.s.}{\underset{n \to \infty}{\longrightarrow}} \mu\]데이터의 개수가 많아질수록 평균이 기댓값에 수렴한다. Probability 수렴으로 가는 Weak LLN과 Almost Surely 수렴으로 가는 Strong LLN이 따로 존재한다.
Central limit theorem
\[\sqrt{n}\dfrac{\bar{X}_n-\mu}{\sigma} \overset{d}{\underset{n \to \infty}{\longrightarrow}} \mathcal{N}(0, 1)\]무작위로 추출된 표본의 크기가 커질수록 그 표본평균의 분포가 정규분포에 가까워진다는 내용이다.
Statistical Model
이제 머신러닝의 핵심 개념을 통계적으로 이해해보자. $n$개의 iid 랜덤변수 $X_1, \ldots, X_n$이 어떤 공간 $E$(보통 $E \subseteq R$)에서 동일한 분포 $P$에서 관측되었다고 가정해보자. 이럴 때 Statistical Model은 $(E, (P_\theta)_{\theta \in \Theta})$의 쌍으로 구성된다.
여기서 $E$는 sample space, $\Theta$는 Parameter space, 그리고 $\theta$는 $\Theta$ 내의 특정한 파라미터를 의미한다. 그리고 $P_\theta$는 이러한 $\theta$로 인해 정해진 특정한 확률 분포를 의미한다. 물론 $P$가 어떠한 분포냐에 따라 $\theta$의 의미, 개수등은 전부 다를 것이다.
우리의 목표는 특정한 샘플 $X_1, \ldots, X_n$과 statistical model $(E, (P_\theta)_{\theta \in \Theta})$가 있을 때 $\theta$의 값을 밝혀내는 것, 즉 Estimation이다.
이를 위해 몇 가지 정의가 필요한데, 우선 Statistic이란 이 샘플에 관여하는 임의의 measurable function을 의미한다. 그리고 Estimator of $\theta$는 이러한 Statistic 중 $\theta$와 무관한 함수들을 의미한다. 그리고 이러한 $\theta$의 estimator $\hat{\theta}_n$은 아래의 성질을 만족하게 된다.
\[\hat{\theta}_n \overset{P, a.s.}{\underset{n \to \infty}{\longrightarrow}} \theta (\text{w.r.t. } P_\theta)\]즉, $n$의 크기를 키울수록 우리가 고른 estimator는 원하는 정답 파라미터 $\theta$에 수렴한다는 것을 만족해야 한다. 그 수렴이 almost surely인지 그냥 Probability인지에 따라 강한지 약한지가 결정된다.
생각해보면 이 개념을 실전에서 적용하긴 꽤 어렵다. 정답을 모르니까 머신러닝을 하는 것이 아니겠는가? 그런데 정답에 근접하는지 어쩐지를 어떻게 알 수 있을까? 여기서 이론과 실제의 차이가 발생하는데, 위의 모델은 어디까지나 수학적인 이론에 근거한 정의이다. 실제로 정답이 존재하는지 어떤지는 아무도 알 수 없다. 그렇지만 수학적으로 정답이 확실히 존재한다라는 가정을 잡을 수 있어야 어딘가에 있을 그 정답을 찾을 이론적 가능성이 생기고, 실질적인 머신러닝은 그 존재할 거라고 생각하는 정답을 찾는 여정이라고 볼 수 있다.
각설하고, $\theta$에 대한 estimator의 Bias는 $E[\hat{\theta}_n] - \theta$로 정의된다. 또한 이 estimator의 Risk(혹은 Quadratic risk)는 $E[|\hat{\theta}_n - \theta|^2]$으로 정의된다. 그리고 만일 $\Theta \in \mathbb{R}$이라면, Quadratic risk = Bias$^2$ + Variance가 된다.
여기서 Risk를 Quadratic Risk라고 부르는 이유는, 계산을 둘의 차이의 절댓값의 제곱, 즉 거리를 재기 때문이다.
Total Variation Distance
이제, iid인 확률변수 $X_1, \ldots, X_n$의 statistical model $(E, (P_\theta)_{\theta \in \Theta})$이 있을 때, $X_1 \sim P_{\theta^\ast}$를 만족하는 $\theta^\ast$가 있다고 하자. 여기서 이 $\theta^\ast$는 곧 우리가 원하는 바로 그 정답이라서, True parameter라고 부른다.
여하튼 이 정답 파라미터가 존재한다고 가정하면, 위의 Quadratic risk를 최소화시키는 것이 우리의 목적이므로 $\vert P_{\hat{\theta}}(A)-P_{\theta^\ast}(A) \vert, \forall A \subset E$를 최소화시키는 estimator $\hat{\theta}$를 찾아야 한다.
여기서 나온 이 거리 개념, 즉 $\vert P_{\theta}(A)-P_{\theta^\prime}(A) \vert$를 Total Variation Distance라고 부른다. 엄밀하게는 다음과 같이 가능한 거리들 중 최댓값으로 정의한다.
\[TV(P_\theta, P_{\theta^\prime}) = \underset{A \subset E}{\max}|P_{\theta}(A)-P_{\theta^\prime}(A)|\]일반적으로 $E$가 연속적이라는 가정 하에 PDF $P_\theta(X \in A) = \int_A f_\theta(x)dx$로 표현되므로, Total Variation Distance TV는 다음과 같은 적분으로 나타낼 수 있다.
\[TV(P_\theta, P_{\theta^\prime}) = \dfrac{1}{2}\int_E |f_\theta(x) - f_{\theta^\prime}(x)|dx\]이것을 “거리”라고 부르는 이유는 거리가 가져야 할 아래의 성질들을 모두 만족하기 때문이다.
- $TV(P_\theta, P_{\theta^\prime}) = TV(P_{\theta^\prime}, P_\theta)$ (Symmetric)
- $TV(P_\theta, P_{\theta^\prime}) \geq 0$
- If $TV(P_\theta, P_{\theta^\prime}) = 0$ then $P_\theta = P_{\theta^\prime}$ (Definite)
- $TV(P_\theta, P_{\theta^\prime}) \leq TV(P_\theta, P_{\theta^{\prime\prime}}) + TV(P_{\theta^{\prime\prime}}, P_{\theta^\prime})$ (Triangle inequality)
그러면 결국 우리의 목표는 estimator $\hat{TV}(P_\theta, P_{\theta^\ast}), \forall \theta \in \Theta$를 설정한 뒤, 이 값을 최소화하는 $\hat{\theta}$를 찾는 것이다.
그런데 TV에는 한 가지 큰 문제점이 있다. 대부분의 확률은 PDF의 적분으로 표현되기 때문에, TV를 계산하는 것이 매우 어렵다는 것이다. 그나마 계산이 되는 가우시안 분포도 복잡한 적분식이 나오고, 일반적인 경우에는 계산이 사실상 불가능에 가깝다.
Kullback-Leibler Divergence
그렇기 때문에 TV를 대체할만한 다른 거리 개념을 도입하게 되었는데, 그것이 바로 Kullbeck-Leibler Divergence, 즉 KL Divergence이다. KL Divergence는 다음과 같이 정의된다.
\[KL(P_\theta, P_{\theta^\prime}) = \begin{cases} \sum\limits_{x \in E}p_\theta(x)\log\left(\dfrac{p_\theta(x)}{p_{\theta^\prime}(x)}\right) & \text{if } E \text{ is discrete} \\ \int_{E}f_\theta(x)\log\left(\dfrac{f_\theta(x)}{f_{\theta^\prime}(x)}\right) & \text{if } E \text{ is continuous} \end{cases}\]복잡해 보이지만 로그 안에 분수가 들어가있으므로 그냥 뺄셈으로 치환이 가능하다.
그런데 KL Divergence는 사실 “거리”는 아니다. 그렇기 때문에 TV와는 달리 이름에 Distance가 붙지 않고 Divergence가 붙었다. 아까 거리가 가져야 할 성질들이 KL에서 어떤가를 확인해보면 다음과 같다.
- $KL(P_\theta, P_{\theta^\prime}) \ne KL(P_{\theta^\prime}, P_\theta)$ in general
- $KL(P_\theta, P_{\theta^\prime}) \geq 0$
- If $KL(P_\theta, P_{\theta^\prime}) = 0$ then $P_\theta = P_{\theta^\prime}$ (Definite)
- $KL(P_\theta, P_{\theta^\prime}) \nleq KL(P_\theta, P_{\theta^{\prime\prime}}) + KL(P_{\theta^{\prime\prime}}, P_{\theta^\prime})$ in general
그렇기 때문에 KL에서 잃어버린 성질들이 중요한 환경이라면 TV를 써야 한다. 그러나 머신러닝에서는 대부분의 경우 그 성질들이 그리 중요하지 않아서 계산의 간편함 때문에 KL을 주로 쓰게 된다.
Maximum Likelihood Estimation
우선 위의 KL Divergence의 정의는 다음과 같이 바꿔서 쓸 수 있다.
\[\begin{aligned} KL(P_{\theta^\ast},P_\theta) &= E_{\theta^\ast}\left[\log\left(\dfrac{p_{\theta^\ast}(X)}{p_\theta(X)}\right)\right] \\ &= E_{\theta^\ast}[\log p_{\theta^\ast}(X)] - E_{\theta^\ast}[\log p_\theta(X)] \end{aligned}\]여기서 첫 번째 항은 우리의 학습 결과와는 아무 상관없는 값이므로 “Constant”로 취급할 수 있다. 또한 LLN에 의해,
\[\dfrac{1}{n}\sum_{i=1}^{n}h(X_i) \to E_{\theta^\ast}[h(X)]\]따라서, $P_{\theta^\ast}$와 $P_\theta$ 간의 KL Divergence는 “Constant” $- \dfrac{1}{n}\sum\limits_{i=1}^{n}\log p_{\theta}(X_i)$로 표현할 수 있다. 이 값을 최소화하는 것이 목적이므로, $\sum\limits_{i=1}^{n}\log p_{\theta}(X_i)$가 최대화되어야 한다. 이를 Maximum Likelihood Principle이라고 부른다.