Advanced Machine Learning 3 - kNN & Bias-Variance Trade-off
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Advanced Machine Learning 과목의 수업을 다룬다.
Data Augmentation
Data Augmentation은 그 말 그대로 데이터 증강을 의미한다. 즉, 우리가 준비한 데이터셋을 뻥튀기시키는 기법이다. 이미지를 예로 들면 뒤집거나 자르거나 색을 변형하거나 노이즈를 추가하거나 하는 식의 변형을 생각해볼 수 있다. 이렇게 하는 목적은 당연히 훨씬 더 많은 샘플을 확보하기 위해서이다.
그런데 아무렇게나 변형시킨다고 그게 다 유효한 데이터가 되진 않는다. 당연히 그 데이터의 본질, 즉 label은 유지해야 한다. 개와 고양이를 분류하는 문제를 위해 고양이 사진을 변형하더라도 그 사진은 어쨌거나 “고양이”임은 알아볼 수 있을 정도여야 한다는 이야기다. 만일 눈동자만 확대하는 등 이 본질을 넘어서는 변형을 가한다면 그건 더 이상 유효한 augmentation이 아니다. 이를 “semantically invariant”라고 말한다.
그럼 이 데이터 증강의 수학적 의미는 무엇일까? True risk $R(h) = \int\limits p(x,y)l(y,h(x))dxdy$는 모든 $x,y$에 대해서 커버한다. 그런데 이를 실질적으로 계산하는 것이 불가능하기에 Empirical risk $L(h;\mathbb{D})=\dfrac{1}{n}\sum\limits_{i=1}^{n} l(y_i,h(x_i))$를 계산하는데, 이는 우리가 가지고 있는 데이터셋만 커버한다.
위의 데이터 증강을 거치면 $R_v(h)=\dfrac{1}{m}\sum\limits_{i=1}^{m} l(\tilde{y_i},h(\tilde{x_i}))$로 표기하고, 이를 Vicinal risk라고 부른다. 그리고 각각의 데이터셋마다 더 넓은 범위를 커버한다.
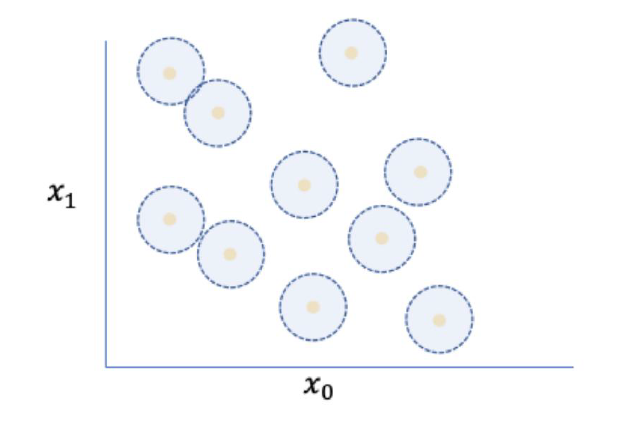
결국 증강된 데이터셋마다 label이 변하진 않기 때문에, 각각의 원본 데이터마다 더 넓은 범위를 커버하는 형태가 된다. 물론 이 또한 단순 Empirical risk의 범위보다 확실히 커버하는 범위가 넓어진 것이기에, 유효한 방법이라고 할 수 있겠다. 물론, 위에서도 언급했지만 증강을 유지하려면 label이 변해서는 안된다. 그게 유지된다는 가정 하에 큰 변형을 가할수록 학습 결과가 더 좋게 나올 것이다.
k-Nearest Neighbors
k-Nearest Neighbors, 즉 kNN은 가장 간단한 ML 모델 중 하나이다. 저번 글에서 모든 모델은 다 나름의 가정이 존재한다고 했는데, kNN에서는 “비슷한 위치의 데이터는 비슷한 label을 가질 것이다.” 라는 가정이 필요하다. 이러한 가정 하에, 새로운 데이터를 주면 그 근처 $k$개의 데이터를 찾아 그 중 가장 많이 보이는 label을 리턴하는 식으로 동작한다.
이를 수식으로 나타내면 다음과 같다.
\[S_x \subseteq \mathbb{D} \text{ s.t. } |S_x| = k \text{ and } \forall(x^\prime,y^\prime) \in D\backslash S_x \text{ where } dist(x,x^\prime) \geq \underset{(x'',y'') \in S_x}{\max} \text{dist}(x,x'')\]여기서의 $S_x$가 즉 위에서 말한 “주어진 데이터 $x$에서 가장 가까운 $k$개의 데이터의 집합”을 뜻한다. 그 이후 모델 $h$는 다음과 같이 정의할 수 있다.
\[h(x) = \text{mode}(\lbrace y''|(x'',y'') \in S_x \rbrace)\]여기서의 $\text{mode}$는 파이썬에 존재하는 최빈값 함수다. 즉, $S_x$에 존재하는 라벨들의 최빈값을 그대로 리턴한다는 의미이다.
그러면, 이 모델에서 중요한 값들은 어떤게 있을까? (참고로, 이들 값 모두 학습하면서 배우는 것이 아니라 사전에 설정해줘야 하는 값이라 hyper parameter로 불린다.)
우선 첫째로는 $k$가 있다. 이 데이터셋에선 이웃 몇개를 봐야 잘 예측할 것인가는 데이터셋마다 다르기에 학습으로 정해야 한다.
만일 $k=1$이면 어떻게 될까? 가장 가까운 이웃 1개만 보고, 그 label을 그대로 리턴하게 된다. 그러면 데이터의 상태에 너무 민감하게 반응하게 되어, 조금의 차이만 생겨도 예측값이 극단적으로 바뀌게 된다.
그럼 반대로 $k=n$이라면 어떻게 될까? 이러면 어느 데이터를 고르던 결과가 바뀌지 않는다. 위와는 정 반대로, 데이터의 상태에 너무나도 둔감해져서 모든 입력값에 대해 동일한 예측만 할 것이다.
또 다른 파라미터는 거리를 재는 방법, 즉 $\text{dist}$이다. 거리를 어떻게 재느냐에 따라 kNN의 예측값은 많이 달라질 것이다. 일반적으로는 기하학에서 제일 많이 쓰이는 Minkowski distance를 사용하는데, 이는 다음과 같다.
\[\text{dist}(x,z)=\left(\sum_{r=1}^{d}|x_r-z_r|^p\right)^{\frac{1}{p}}\]여기서 $p=1$이라면 Manhattan distance, $p=2$라면 Euclidean distance, 극단적으로 $p\rightarrow\infty$라면 Maximum distance라고 부르며 각각 아래 그래프와 같이 생겼다.
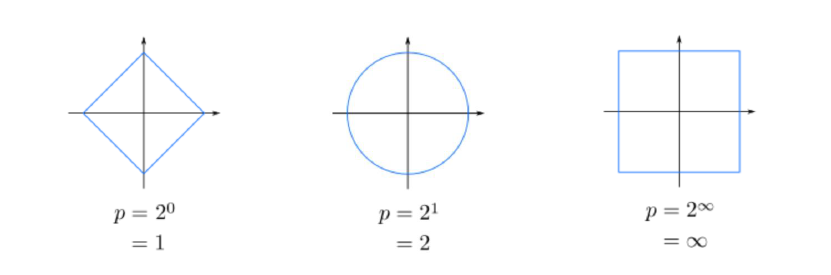
그런데, 일반적으로 머신러닝에서 사용되는 데이터는 차원이 굉장히 크다. 그리고 위에서 열심히 정의한 “거리” 개념이 고차원으로 갈수록 사라지게 된다. 이를 Curse of Dimensionality라고 부르는데, 고차원으로 갈수록 기하학적인 개념들이 많이 무너지게 되는 현상을 보인다. 그로 인해 거리 개념에 크게 의존하게 되는 kNN 알고리즘은 입력 데이터의 차원이 높아질수록 모든 데이터 간의 거리가 0에 수렴하게 되버려 변별력이 사라지는 치명적인 문제가 있다.
물론 그럼에도 불구하고 위 문제점을 개선하기 위한 시도들이 많이 있었는데, 대표적으로는 작은 영역만 보면 낮은 차원으로 취급할 수 있다는 원리를 이용한 방법이 있다. 이러한 작은 영역(manifold) 단위로 봐서 차원 축소를 시키면 어느 정도 변별력을 가지게 할 수 있다.
그런데 kNN은 위의 문제점 말고도 치명적인 문제가 하나 더 있는데, 계산 비용이 너무 크다는 점이다. 요즘의 모델에 필요한 학습 데이터는 만단위는 우습게 넘어가는데, kNN을 사용하기 위해선 모든 데이터 쌍들의 거리를 전부 계산해야 한다. 한번쯤이야 오랜 시간을 들여 계산한다고 쳐도, 이 상태에서 새 데이터를 넣을 때마다 기존 모든 데이터들과의 거리를 계산해야 하므로 시간복잡도가 무려 $O(nd)$가 된다. 사실 이러한 문제가 커서 kNN을 실전에선 쓰지 않는 것이라고 볼 수 있다.
다만 kNN의 핵심 컨셉은 다른 모델/아키텍쳐 등에서 사용되고 있다. 그래서 kNN을 그 자체로 사용하진 않지만 그 개념 자체가 사장된 것은 아니라고 할 수 있겠다.
Bias-Variance Trade-off
kNN에서 보여준 $k=1$과 $k=n$일 때의 모습은 저번에 봤던 Generalization Error와는 다른 형태의 에러를 보여준다.
Bias, 즉 편향은 잘못된 assumption으로 인한 에러로, Bias가 높은 모델은 학습 데이터로부터 제대로 배우지 못한다는 의미이다. 그로 인해 모델이 데이터에 너무 둔감해져서 학습 데이터와는 전혀 무관한 형태로 동작하는 모델이 만들어지게 된다. kNN에서 $k=n$이 바로 Bias가 높은 상태인 것이다.
Variance, 즉 분산은 데이터의 아주 작은 특징, 즉 small fluctuation에도 너무 민감하게 반응하는 에러이다. 그렇기 때문에 Variance가 높은 모델은 일반화가 제대로 되지 않아 새로운 샘플을 던져주면 동작을 잘 하지 못하게 된다. kNN에서 $k=1$이 바로 Variance가 높은 상태인 것이다.
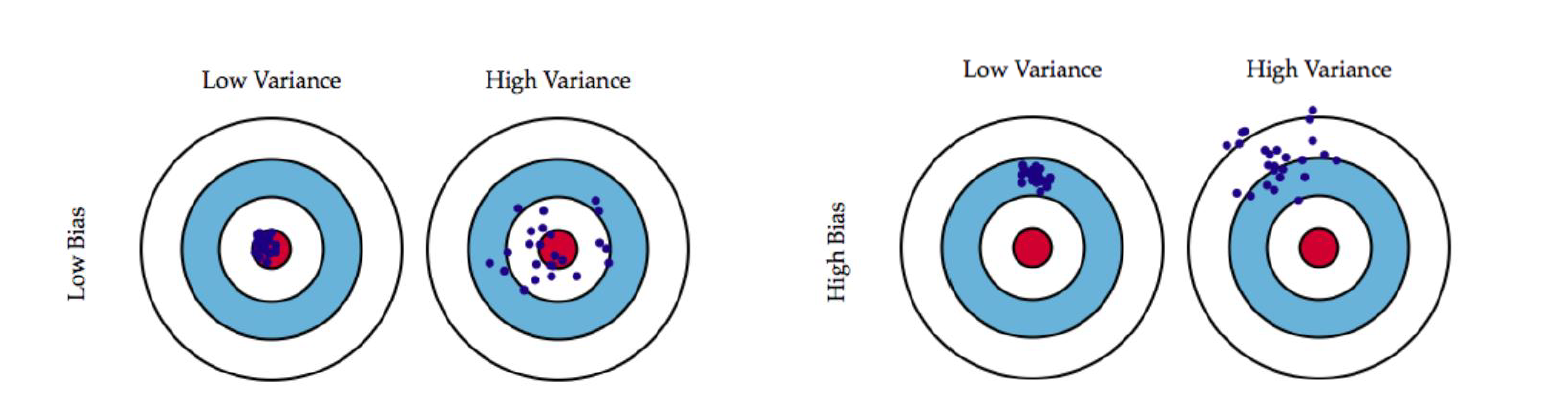
위의 그림은 이를 잘 나타내준다. 위 그림에서 각각의 점들은 임의의 데이터셋 $D_i$로 학습한 모델의 예측값을 나타낸다. 즉, 문제 상황, 가정, 모델의 모든 것들은 동일한데 학습에 사용한 실제 데이터셋만 달라진 형태이다. 물론 모든 데이터셋 $D_i$는 전부 동일한 문제에서의 데이터이므로 모두 동일한 분포에서부터 왔다.
Bias가 높으면 예측은 잘 모여있으나 그 모여있는 점이 정답과는 거리가 먼 곳이 된다. 반대로 Variance가 높으면 목표 지점에서 넓게 퍼뜨려져서 이 모델을 신뢰하기 어렵게 된다. 둘 다 낮아야 첫번째 그림과 같이 정답 근처에 예쁘게 모여있는 형태의 모델을 얻을 수 있다.
그러나 실제로 둘을 동시에 낮추긴 어렵다. 정확히는 Bias와 Variance는 trade-off 관계라서 하나를 낮추면 다른 하나가 높아지는 구조이다. 직관적으로 생각해보면 둘은 모두 모델의 복잡도와 관련된 에러이다. Bias는 모델이 단순할수록 높아지고, Variance는 모델이 복잡할수록 높아진다. 그렇기 때문에 하나만 일방적으로 낮추는 것은 불가능하고, 둘 사이의 적절한 균형을 찾아야 한다.
그리고 모델의 Error는 Bias의 제곱과 Variance의 합으로 나타낼 수 있다. 이를 증명하기 위해, 우선 Bias와 Variance를 수학적으로 어떻게 정의할 수 있을지부터 정하자.
우선 True label $y=h(x)+e$로 표현된다고 가정하자. 이럴 때 Bias는 $\text{Bias}\left[ \hat{h}(x) \right] = h(x)-E[\hat{h}(x)]$가 된다. 즉, 예측값과 정답의 차이의 평균이 된다. Variance는 $\text{Var}\left[ \hat{h}(x) \right] = E[(\hat{h}(x) - E[\hat{h}(x)])^2]$가 된다.
이럴때 $err(x) = \mathbb{E}_{x,y,\mathbb{D}}\left[ (y-\hat{h}(x))^2\right]$가 된다. 이러면 다음과 같이 유도할 수 있다.
\[\begin{aligned} E_{x,y,D}\left[(h_D(x)-y)^2\right] &= E_{x,y,D}\left[((h_D(x)-\bar{h}(x))+(\bar{h}(x)-y))^2\right] \\ &= E_{x,D}\left[(h_D(x)-\bar{h}(x))^2\right] \\ &\quad + 2E_{x,y,D}\left[(h_D(x)-\bar{h}(x))(\bar{h}(x)-y)\right] \\ &\quad + E_{x,y}\left[(\bar{h}(x)-y)^2\right] \end{aligned}\]여기서 위의 식의 가운데 항은 다음의 과정을 통해 0이 됨을 알 수 있다.
\[\begin{aligned} E_{x,y,D}\left[(h_D(x)-\bar{h}(x))(\bar{h}(x)-y)\right] &= E_{x,y}\left[E_D[h_D(x)-\bar{h}(x)](\bar{h}(x)-y)\right] \\ &= E_{x,y}\left[(E_D[h_D(x)]-\bar{h}(x))(\bar{h}(x)-y)\right] \\ &= E_{x,y}\left[(\bar{h}(x)-\bar{h}(x))(\bar{h}(x)-y)\right] \\ &= E_{x,y}\left[0\right] \\ &= 0 \end{aligned}\]그리고 첫번째 항은 Variance이다. 이제 마지막 항을 전개하면 다음과 같다.
\[\begin{aligned} E_{x,y}\left[(\bar{h}(x)-y)^2\right] &= E_{x,y}\left[((\bar{h}(x)-\bar{y}(x))+(\bar{y}(x)-y))^2 \right] \\ &= E_{x,y}\left[(\bar{y}(x)-y)^2\right] \\ &\quad + E_{x}\left[(\bar{h}(x)-\bar{y}(x))^2\right] \\ &\quad + 2E_{x,y}\left[(\bar{h}(x)-\bar{y}(x))(\bar{y}(x)-y)\right] \end{aligned}\]이 식에서도, 두번째 항은 Bias의 제곱이 된다. 그리고 마지막 항은 다음의 과정을 통해 0이 됨을 알 수 있다.
\[\begin{aligned} E_{x,y}\left[(\bar{h}(x)-\bar{y}(x))(\bar{y}(x)-y)\right] &= E_{x}\left[E_{y|x}[\bar{y}(x)-y](\bar{h}(x)-\bar{y}(x))\right] \\ &= E_{x}\left[(\bar{y}(x)-E_{y|x}[y])(\bar{h}(x)-\bar{y}(x))\right] \\ &= E_{x}\left[(\bar{y}(x)-\bar{y}(x))(\bar{h}(x)-\bar{y}(x))\right] \\ &= E_{x}[0] \\ &= 0 \end{aligned}\]이상의 내용을 종합하면, $err(x)$는 다음과 같이 정의할 수 있다.
\[E_{x,y,D}\left[(h_D(x)-y)^2\right] = E_{x,D}\left[(h_D(x)-\bar{h}(x))^2\right]+E_{x}\left[(\bar{h}(x)-\bar{y}(x))^2\right]+E_{x,y}\left[(\bar{y}(x)-y)^2\right]\]여기서 첫번째 항은 Variance, 두번째 항은 Bias의 제곱, 그리고 마지막 항은 Noise $\sigma_E$가 된다.