Linear Algebra 8 - Continuous Normalizing Flow
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Linear Algebra 과목의 수업을 다룬다…만, 과목명은 페이크고 사실은 생성형 모델을 다루는 수업이다.
Ordinary Differential Equation
아래와 같은 미분방정식을 생각해보자.
\[\dfrac{dx(t)}{dt}=f(x(t),t,\theta)\]이러한 형태의 미분 방정식을 1st order Ordinary Differential Equation이라고 부른다. 여기서 $x$는 우리가 관심있는 변수, $t$는 시간, $f$는 파라미터 $\theta$에 의해 정해지는 $x$와 $t$에 대한 함수라고 생각해보자.
이 상황에서 Initial Value Problem, 즉 $x(t_0)$가 주어져 있을 때 $x(t_1)$을 구하는 문제를 풀려면 어떻게 해야 할까?
\[x(t_1)=x(t_0)+\int_{t_0}^{t_1}f(x(t),t,\theta)dt\]일반적으론 위와 같이 적분해서 풀면 된다.
아래의 예시 문제를 풀어보자.
\[\dfrac{dx}{dt}=2xt, x(0)=2, x(1)=?\]이 상황에서 $x(1)$을 구하면 된다. 이 문제를 풀려면 다음과 같이 전개하면 된다.
\[\begin{aligned} \int\dfrac{1}{2x}dx&=\int tdt \\ \dfrac{1}{2}\log x&=\dfrac{1}{2}t^2+c_0 \\ x(t)&=ce^{t^2} \end{aligned}\]여기서 $x(0)=c$이므로 $c=2$가 된다.
$\therefore x(t)=2e^{t^2}$이므로 $x(1)=2e\fallingdotseq5.436$
1st-order Runge-Kutta / Euler’s method
그러면 $f$의 $t$에 대한 적분이 복잡하거나 혹은 적분식을 구할 수 없는 경우라면 어떻게 계산해야 할까? 이러한 경우에 사용할 수 있는 방법 중 하나로 1st-order Runge-Kutta, 혹은 Euler’s method가 있다.
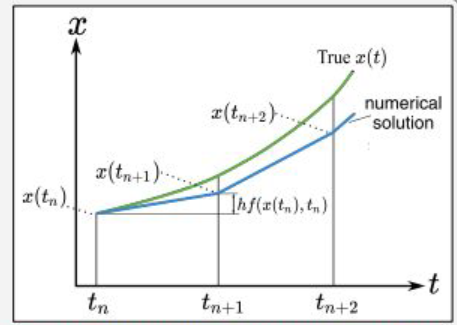
이는 수치해석적인 방법으로, 위의 그림과 같이 Step Size $h$를 정한 후 매 Step마다 Taylor’s Expansion을 활용해 근사시키는 방법이다.
\[\begin{aligned} t_{n+1}&=t_n+h \\ x(t_{n+1})&=x(t_n)+hf(x(t_n),t_n) \end{aligned}\]물론 Taylor’s Expansion과 마찬가지로 Step Size가 작을수록 보다 더 정확하게 근사가 가능할 것이다. 어찌되었든 여기서는 적분을 구할 수 없는 경우에 대해서도 이런 식으로 근사해서 풀 수 있다는 사실을 알아두자.
이 방법으로 위에서 풀었던 예시 문제를 다시 풀어보면 다음과 같다.
\[\dfrac{dx}{dt}=2xt, x(0)=2, x(1)=?\]여기서 $h=0.25$로 잡으면 다음과 같이 각 Step별 함숫값을 구할 수 있다.
\[\begin{aligned} x(0.25)&=x(0)+0.25*f(x(0),0) \\ &= 2+0.25*(2*2*0) \\ &= 2 \\ \\ x(0.5)&=x(0.25)+0.25*f(x(0.25),0.25) \\ &= 2+0.25*(2*2*0.25) \\ &= 2.25 \\ \\ x(0.75)&=x(0.5)+0.25*f(x(0.5),0.5) \\ &= 2.25+0.25*(2*2.25*0.5) \\ &= 2.8125 \\ \\ x(1)&=x(0.75)+0.25*f(x(0.75),0.75) \\ &= 2.8125+0.25*(2*2.8125*0.75) \\ &= 3.8671875 \end{aligned}\]정확한 $x(1)=2e$에 비해 오차가 좀 크게 난 것을 알 수 있는데, 이는 $x(t)=2e^{t^2}$의 그래프를 그려보면 기울기가 가파르게 증가하는 형태라 그런 것이다.
Abstraction
위의 두 방법을 통해서 어떤 식으로든 $x(t_1)$을 구할 수는 있음을 알았다. 그런데 이 모든 과정을 고려하면 식 하나로 쓰기엔 너무 복잡하기 때문에, 아래와 같이 ODESolve라는 함수로 추상화를 하자.
\[\dfrac{dx(t)}{dt}=f(x(t),t,\theta); x(t_0) \text{ is given}\] \[x(t_1)=ODESolve(f(x(t),t,\theta),x(t_0),t_0,t_1)\]이 ODESolve 함수는 총 4개의 인자를 갖고 있으며, 각각 미분식, 초기값, 초기 시간, 최종 시간을 의미한다.
그런데 이 ODESolve 함수를 잘 생각해보면, ODESolve는 임의의 최종 시간에 대해서도 값이 나오기 때문에 시간에 대해 연속적이며, 서로 다른 초기 조건에서 출발한 ODESolve의 그래프가 서로 교차하지 않는다. 즉, ODESolve는 시간 $t$에 대한 Flow가 된다.
Neural Ordinary Differential Equation
만일 ODESolve를 1st-order Runge-Kutta로 풀었다고 가정하면 다음과 같은 형태가 될 것이다.
\[\begin{aligned} \dfrac{dx}{dt}&=f(x(t),t,\theta) \\ x_{n+1}&=x_n+hf(x_n,t_n,\theta) \end{aligned}\]그리고 ResNet에서 등장한 Residual Connection을 다시 확인해보자.
\[x_{l+1}=x_l+f(x_l,\theta)\]놀랍게도 동일한 형태임을 알 수 있다. 다만 ODESolve는 시간에 대한 Flow라서 연속적이고, ResNet은 레이어마다 이루어지는 연산이라 이산적이라는 차이만 있을 뿐이다. 그런데 이 말은 곧 ResNet에서 Layer 개수를 $\infty$로 보내면 정확히 $\dfrac{dx}{dt}=f(x(t),t,\theta)$가 나온다는 이야기이다.
즉, 미분방정식 $\dfrac{dx}{dt}=f(x(t),t,\theta)$에서의 함수 $f$는 ResNet, 더 나아가서 임의의 ML 모델의 연속적인 형태가 된다. 즉, 여기서의 $f$를 하나의 Neural Network로 취급할 수 있다. 그럼 이 연속 모델은 어떤 식으로 추론과 학습을 할 수 있을까?
우선 추론, 즉 Forward Propagation의 경우 ResNet과 비교해보면 의의로 쉽게 답이 나온다. $f$가 ResNet의 Residual Connection 하나에 대응되기 때문에, 이들을 모아놓으면 그대로 Forward Propagation이 된다. 즉, $ODESolve(f(x(t),t,\theta),x(t_0),t_0,t_1)$이 바로 추론 결과값이 된다.
Adjoint Method
그렇다면 학습, 즉 Backpropagation은 어떨까? 이를 알기 위해서는 $L(x(t_1))$, 즉 $\dfrac{\partial L}{\partial \theta}$를 구해야 하는데, 이를 풀기 위해 사용되는 방법이 Adjoint Method이다.
Adjoint Method에선 우선 Adjoint $a(t)$를 $a(t)=\dfrac{\partial L}{\partial x}$로 정의한다. 즉 “시각 $t$에서의 상태 x(t)가 최종 Loss에 얼마나 영향을 주는가”를 의미한다. 또한 Loss $L$은 최종 상태에만 의존한다고 가정한다. 즉, $L=L(x(t_1))$이다.
이 상황에서 Adjoint $a(t)$를 $t$에 대해 미분하면 어떻게 될까? 우선 Chain Rule에 의해 다음과 같이 항을 나눌 수 있다.
\[\dfrac{da}{dt}=\dfrac{d}{dt}\dfrac{dL}{dx}\]시간 $t$에서 $t+\epsilon$으로 변화했을 때를 보면
\[x(t+\epsilon)=x(t)+\epsilon f(x(t),t,\theta)\]1st-order Runge-Kutta를 적용한 상황을 가정했으므로 위와 같이 간단하게 표시할 수 있다. 이제 $a(t)$에 정의에 의해서
\[\begin{aligned} a(t)&=\dfrac{dL}{dx(t)} \\ &=\dfrac{dL}{dx(t+\epsilon)}\cdot\dfrac{dx(t+\epsilon)}{dx(t)} \\ &=a(t+\epsilon)\cdot\dfrac{dx(t+\epsilon)}{dx(t)} \end{aligned}\]여기서 $\dfrac{dx(t+\epsilon)}{dx(t)}=I+\epsilon\dfrac{\partial f}{\partial x}$이므로,
\[\begin{aligned} a(t)&=a(t+\epsilon)\left(I+\epsilon\dfrac{\partial f}{\partial x}\right) \\ &=a(t+\epsilon)+\epsilon\cdot a(t+\epsilon)\dfrac{\partial f}{\partial x} \end{aligned}\] \[\dfrac{a(t)-a(t+\epsilon)}{\epsilon}=a(t+\epsilon)\dfrac{\partial f}{\partial x}\] \[\dfrac{a(t+\epsilon)-a(t)}{\epsilon}=-a(t+\epsilon)\dfrac{\partial f}{\partial x}\]따라서 $\epsilon\rightarrow 0$으로 보내면 다음과 같은 결과를 얻을 수 있다.
\[\dfrac{da}{dt}=-a(t)^T\dfrac{\partial f(x(t),t,\theta)}{\partial x}\]이 식을 Adjoint Equation이라고 한다. 또한 $a(t_1)=\dfrac{\partial L}{\partial x(t_1)}$은 일반적인 Loss의 Gradient이므로 이미 알고 있는 값이다.
이상의 결과로부터 $a(t_1)$을 초기값으로 하여 시간을 거꾸로 흘려보내는 ODE를 풀면 모든 시각에 대한 $a(t)$를 구할 수 있다.
그럼 이제 $\theta$에 대한 Gradient를 알아보자. $\theta$는 Neural Network $f$의 파라미터이기 때문에, $\theta$를 살짝만 바꿔도 전체 궤적이 변경된다. 따라서 $\dfrac{dL}{d\theta}$는 모든 시각에서의 영향을 적분해야 한다.
\[\begin{aligned} \dfrac{dL}{d\theta} &= \int_{t_0}^{t_1}\dfrac{\partial L}{\partial x(t)}\cdot\dfrac{\partial f}{\partial\theta}dt = \int_{t_0}^{t_1}a(t)^T\dfrac{\partial f}{\partial\theta}dt\\ &=-\int_{t_1}^{t_0}a(t)^T\dfrac{\partial f(x(t),t,\theta)}{\partial\theta}dt \end{aligned}\]Summary
이상의 정보들을 종합해보자. 1st order Ordinary Differential Equation을 수치해석적으로 근사시킨 방법이 ResNet의 Residual Connection과 매우 유사한 형태로 이루어져 있음에 착안하여, Layer를 “이산적으로” 쌓는 기존의 모델 대신 연속적으로 구성하는 형태를 만든 것이 Neural ODE이다.
Neural ODE에서 Forward Propagation은 다음과 같이 이루어진다.
- $x(t_1)=ODESolve(f(x(t),t,\theta),x(t_0),t_0,t_1)$
- $L(x(t_1))$ 계산
- $a(t_1)=\dfrac{\partial L}{\partial x(t_1)}$
다음으로 Backpropagation은 다음과 같이 이루어진다.
- $x(t_0)=ODESolve(f(x(t),t,\theta),x(t_1),t_1,t_0)$
- $a(t_0)=\dfrac{\partial L}{\partial x(t_0)}=ODESolve(-a(t)^T\dfrac{\partial f(x(t),t,\theta)}{\partial x},\dfrac{\partial L}{\partial x(t_1)},t_1,t_0)$
- $\dfrac{\partial L}{\partial\theta}=-\int\limits_{t_1}^{t_0}a(t)^T\dfrac{\partial f(x(t),t,\theta)}{\partial\theta}dt=ODESolve(-a(t)^T\dfrac{\partial f(x(t),t,\theta)}{\partial\theta},0,t_1,t_0)$
그리고 위의 3개의 ODESolve는 전부 $t_1$에서 $t_0$로 가기 때문에, 각각 따로따로 계산하지 않고 벡터로 묶어서 한번에 계산할 수 있다.
Continuous Normalizing Flow
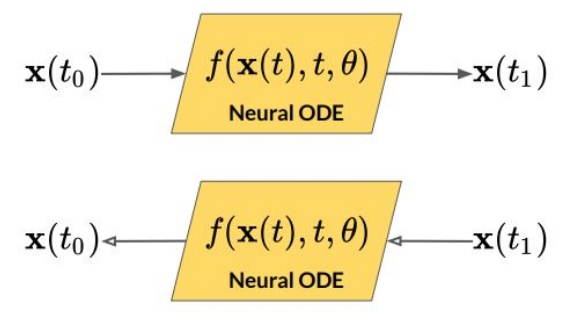
그런데 이렇게 정의된 Neural ODE, 즉 연속적인 Neural Network를 잘 생각해보면, 위 사진과 같이 시간 값만 반대로 바꿔주면 그대로 반대 방향의 Flow가 나온다. 즉, Neural ODE는 딱히 Invertible을 신경쓴 적이 없음에도 자동적으로 Invertible한 Neural Network가 형성된다.
그래서 Neural ODE는 그 자체로 저번 글에서 알아본 Normalizing Flow의 연속적인 버전이 된다. 이러한 관점에서 본 Neural ODE를 Continuous Normalizing Flow, 즉 CNF라고 부른다.
이 말은 곧 Discrete Normalizing Flow 대신 Continuous Normalizing Flow를 사용하면 그 까다로운 Invertible 조건을 바로 해결할 수 있다는 얘기가 되므로, 현대의 Normalizing Flow 관련 연구나 설계는 보통 CNF 형태로 이루어진다.
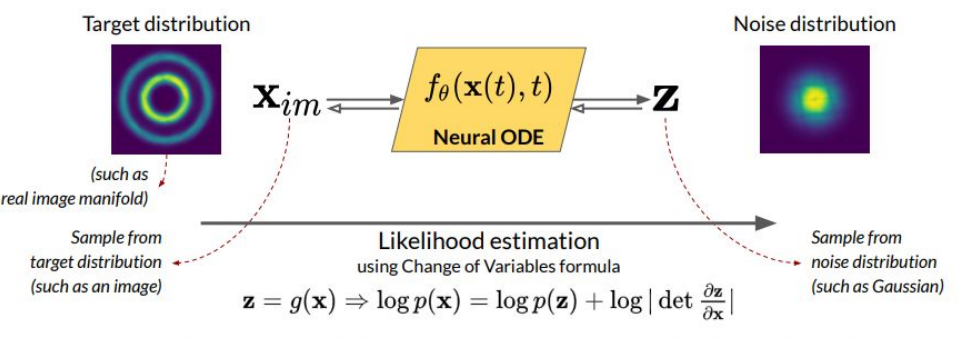
이산적인 Normalizing Flow를 CNF로 바꿨으니 Maximum Likelihood Estimation 또한 아래와 같은 연속적인 적분식으로 표현된다.
\[\log p(x(t_1))=\log p(x(t_0))-\int_{t_0}^{t_1}tr\left(\dfrac{\partial f_{\theta}}{\partial x}\right)dt\]여기서 맨 마지막 항이 $\Sigma$ 대신 적분을 사용한 것 외에도 $\det$ 대신 trace가 들어간 것을 알 수 있는데, 정방행렬 $A$의 Trace $tr(A)=\sum\limits_{i}A_{ii}$로 정의된다. 이것은 아래와 같은 Instantaneous Change of Variables에 의해 유도된다.
\[\dfrac{\partial\log p(x(t))}{\partial t}=-tr\left(\dfrac{\partial f_{\theta}}{\partial x(t)}\right)\]이것이 “Instantaneous” Change of Variables인 이유는 저번 글에서 살펴본 Change of Variables에 $\log$를 씌운 아래 수식과 비교하면 알 수 있다.
\[\log p(x)-\log p(z)=\log\det\left\vert\dfrac{df_{\theta}}{dx(t)}\right\vert\]Free-Form Jacobian Of Reversible Dynamics
그런데 trace 연산은 $O(D^2)$로 비싸서 차원이 높아지면 위의 적분식을 그대로 쓰기 힘들다. 그렇기에 저 부분의 연산 비용을 낮추려는 시도가 있었는데, 그 중 하나가 Free-Form Jacobian Of Reversible Dynamics, 즉 FFJORD이다.
FFJORD에서는 아래의 Hutchinson’s trace estimator를 이용하여 trace 연산을 간략화했다.
\[tr\left(\dfrac{\partial f}{\partial z}\right)=\mathbb{E}_{p(\epsilon)}\left[\epsilon^T\dfrac{\partial f}{\partial z}\epsilon\right]\]즉 trace 전체를 계산하는 것이 아니라, 분포 $p(\epsilon)$ 상의 기댓값으로 바꿔서 그 중 랜덤한 벡터 $\epsilon$ 몇개만 샘플링해서 추정한다.
이 때 Maximum Likelihood Estimation은 다음과 같이 정리된다.
\[\begin{aligned} \log p(z(t_1))&=\log p(z(t_0))-\int_{t_0}^{t_1}tr\left(\dfrac{\partial f}{\partial z(t)}\right)dt \\ &=\log p(z(t_0))-\int_{t_0}^{t_1}\mathbb{E}_{p(\epsilon)}\left[\epsilon^T\dfrac{\partial f}{\partial z(t)}\epsilon\right]dt \\ &=\log p(z(t_0))-\mathbb{E}_{p(\epsilon)}\left[\int_{t_0}^{t_1}\epsilon^T\dfrac{\partial f}{\partial z(t)}\epsilon dt\right] \end{aligned}\]이렇게 함으로써, trace 적분 부분의 복잡도를 $O(D)$로 낮춤과 동시에 적분 계산을 기댓값보다 먼저 해서 저 부분 또한 ODESolve를 사용할 수 있게 했다.