Linear Algebra 10 - Diffusion
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Linear Algebra 과목의 수업을 다룬다…만, 과목명은 페이크고 사실은 생성형 모델을 다루는 수업이다.
Diffusion Model
Diffusion은 원래 물리/화학 용어로, 고밀도/고농도에서 저밀도/저농도로 물질이 퍼져나가는 확산 현상을 일컫는 용어이다. 이 확산은 불규칙적으로 일어나며, 이러한 운동 중 대표적인 것이 Brownian Motion이다. 이러한 Diffusion 현상 및 Brownian Motion 등을 수학적으로 설명하기 위한 방정식이 물론 존재하는데, 그러한 것들을 Diffusion Process라고 부른다.
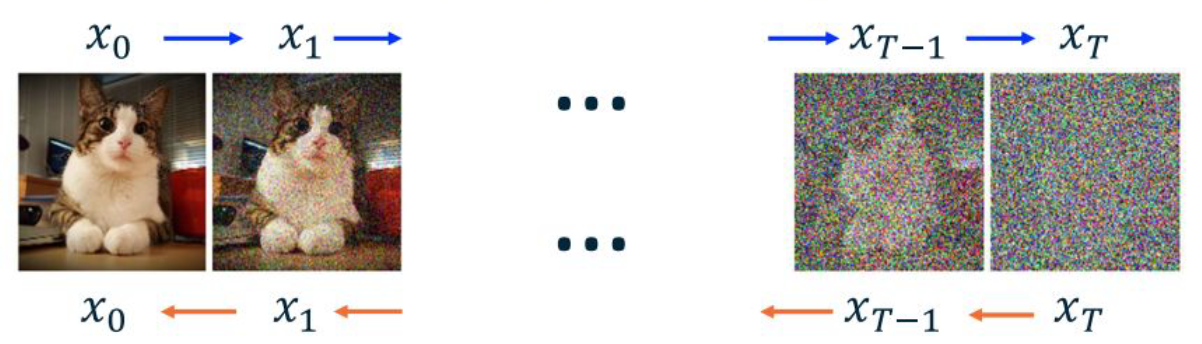
물리학에서 비롯된 이 용어들이 Generative Model에 그대로 적용된 것이 바로 Diffusion Model이다. Diffusion Model은 이러한 Diffusion 현상을 모티브로 해서 위 사진과 같이 2가지의 Diffusion Process를 정의했다. $x_{t-1}\rightarrow x_t$ 방향은 Forward Diffusion Process라고 하며, 사진에 Gaussian Noise를 추가하는 Noising Process이다. 이와는 반대로 $x_{t+1}\rightarrow x_t$ 방향은 Reverse Diffusion Process라고 하며, 사진에서 Gaussian Noise를 제거하는 Denoising Process이다.
즉, 이미지를 $\mathcal{N}(0,I)$로 변경하거나 이를 되돌리는 과정을 한번에 하지 않고 총 $T$번의 Step을 둔다. 그리고 각 단계는 Iterative하게 정의할 수 있으므로, 이 한 단계를 잘 수행하면 전체적인 Step 역시 잘 수행할 수 있게 된다.
그런데 여기서 Forward Diffusion Process는 Neural Network가 필요한 작업이 아니다. Input Data에 Gaussian Noise를 추가하는 작업일 뿐이라 수학적으로 계산이 가능하다. 그러나 Reverse Diffusion Process의 경우는 수학적으로 복원하는 것이 불가능한데, 이는 Reverse Diffusion Process의 최종적인 결과인 $p_{data}$를 정확히 알지 못하기 때문이다. 그렇기 때문에 이 과정에서 Neural Network 및 학습이 필요하며, Generative Model답게 분포를 모방하는 형태로 학습이 이루어지기 때문에 Denoising 과정에서 Stochastic한 결과가 나온다.
그런데 잘 생각해보면 이렇게 여러 Step으로 쪼갠 이 과정을 한번에 수행하면, 즉 $T=1$이라면 이게 곧 VAE가 된다. 따라서 VAE는 여러 Step으로 쪼개야만 하는 이 어려운 과정을 한번에 하기 때문에 전반적인 퀄리티가 떨어지는 것이고, 반대로 Diffusion은 VAE가 한 번에 할 수 있는 일을 여러 Step으로 쪼개고, 또한 명확한 가이드라인까지 제시하기 때문에 퀄리티가 높은 것이라고 이해할 수 있다.
또한 이러한 방식의 초기 Diffusion Model을 DDPM(Denosing Diffusion Probabilistic Model)이라고 부르는데, 이 DDPM은 주어진 이미지의 모든 부분을 다 동등한 중요도로 여기기 때문에 이미지에서 중요한 부분을 잘 캐치하지 못해 연산력 낭비와 함께 디테일이 좀 떨어진다는 단점이 있다.
이러한 문제를 해결하기 위해 현대의 Diffusion 모델들은 대부분 별도의 VAE Encoder와 Decoder를 학습시켜서 이미지를 Latent Space으로 보낸 후, 이 Latent Space 위에서 Diffusion Process를 수행하고 이를 복원한다. 이러한 방식을 Latent Diffusion이라고 한다. VAE Encoder로 보내진 Latent Space는 원본 데이터에 비해 차원이 굉장히 작아 데이터셋의 중요한 부분이 잘 압축되어 있는 상태이고, 따라서 이미지의 “중요한 부분”을 잘 포착하여 Diffusion Process를 수행할 것이라는 기대를 할 수 있다. 물론 차원이 줄어들어 연산력 낭비를 줄이는 것도 무시하지 못할 장점이다.
Denoising Diffusion Probabilistic Model
이제부턴 DDPM에 대해서만 다뤄보자. DDPM의 전체적인 구조는 아래와 같다.
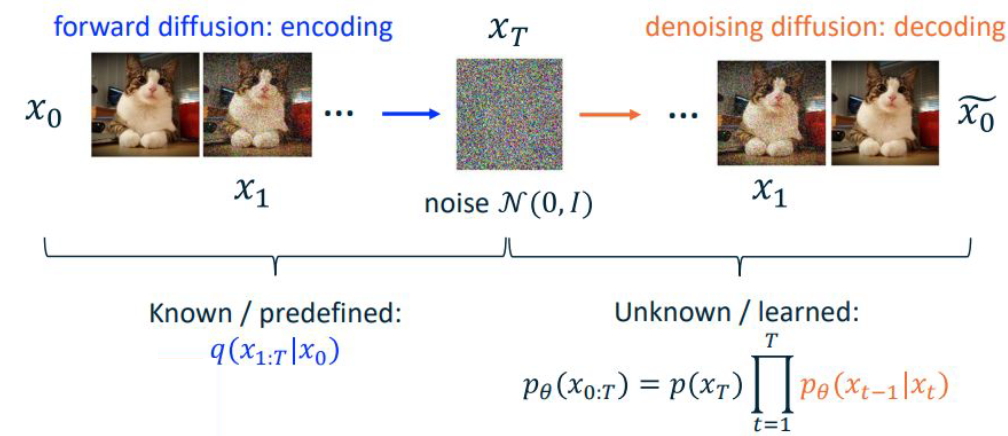
먼저 Forward Process에 대해 알아보자. $q(x_0)$는 Input Data의 분포이다. 이제 1개 Step을 진행하는 Forward Process를 $q_{\phi}$라고 정의하자. 여기서 Forward Process는 $\phi$라는 파라미터가 붙지만 Neural Network는 아님에 주의하자. $q_{\phi}(x_t\vert x_{t-1})$은 Gaussian Noise를 추가하는 작업이므로 다음과 같은 분포를 따른다.
\[q_{\phi}(x_t\vert x_{t-1})\sim\mathcal{N}(\sqrt{\alpha_t}x_{t-1},(1-\alpha_t)I)\]전체적인 Forward Process는 위의 분포를 반복적으로 곱하면 되므로 다음과 같다.
\[q_{\phi}(x_{0:T})=q(x_0)\prod_{t=1}^{T}q_{\phi}(x_t\vert x_{t-1})\]또한 바로 위에서 $q_{\phi}$는 $\phi$라는 파라미터가 있지만 Neural Network는 아니라고 했었다. 이 말 그대로, 사람에 의해 결정될 파라미터가 하나 존재한다. 이는 바로 위에 존재하는 $\alpha_t$인데, $q_{\phi}(x_T)\sim\mathcal{N}(0,I)$가 성립하기만 하면 어떠한 $\alpha_t$도 고를 수 있다. 이를 만족하면서 주로 쓰이는 방법 중 하나는 다음과 같은 Linear Schedule이다.
\[\begin{aligned} \beta_t&=\beta_{min}+\dfrac{t-1}{T-1}(\beta_{max}-\beta_{min}) \\ \alpha_t&=1-\beta_t \\ \bar{\alpha}_t&=\prod_{s=1}^{t}\alpha_s \end{aligned}\]또 다른 방식으로는 다음과 같은 Cosine Schedule이 있다.
\[\begin{aligned} f(u)&=\cos^2\left(\dfrac{\pi}{2}\cdot\dfrac{u+s}{1+s}\right),s\gt 0 \\ \bar{\alpha}_t&=\dfrac{f(\dfrac{t}{T})}{f(0)} \\ \alpha_t&=\dfrac{\bar{\alpha}_t}{\bar{\alpha}_{t-1}} \end{aligned}\]대부분의 경우는 Linear Schedule을 쓰며, 이러한 디자인적 결정 요소가 있어서 Neural Network가 아님에도 파라미터 $\phi$를 붙여서 $q_{\phi}$로 표현한다.
이제 Reverse Process에 대해 알아보자. Reverse Process는 Exact Reverse Process와 Learned Reverse Process로 구분할 수 있다. 우선 Exact Reverse Process의 경우 “이론상”의 Reverse Process를 뜻하며 정확히 위의 Forward Process를 반대 방향으로 수행하는 것을 의미한다.
\[q_{\phi}(x_{0:T})=q_{\phi}(x_T)\prod_{t=1}^{T}q_{\phi}(x_{t-1}\vert x_t)\]즉, 정확히 위와 같은 식이 나온다. 물론 우리는 이 값을 정확히 계산할 수 없다. 이는 $q_{\phi}(x_{t-1}\vert x_t)$를 다음과 같이 펼쳐보면 알 수 있다.
\[q_{\phi}(x_{t-1}\vert x_t)=\dfrac{\int_{x_{0:t-2,t+1:T}}q_{\phi}(x_{0:T})dx_{0:t-2,t+1:T}}{\int_{x_{0:t-2,t:T}}q_{\phi}(x_{0:T})dx_{0:t-2,t:T}}\]즉, 이 값을 정확히 계산하기 위해선 $q(x_0)$를 알아야 하는데, 이 값은 Input Data의 분포라서 정확한 값을 알 수 없다.
따라서 Exact Reverse Process를 Neural Network를 통해 학습으로 배우려고 하는 것이고, 이것을 Learned Reverse Process라고 부른다. 이제 1개 Step을 진행하는 Learned Reverse Process를 $p_{\theta}$라고 하자. 이러면 다음의 두 성질을 만족한다.
\[p_{\theta}(x_T)\sim\mathcal{N}(0,I)\] \[p_{\theta}(x_{t-1}\vert x_t)\sim\mathcal{N}(\mu_{\theta}(x_t,t),\Sigma_{\theta}(x_t,t))\]그리고 전체적인 Learned Reverse Process는 위의 분포를 반복적으로 곱하면 되므로 다음과 같다.
\[p_{\theta}(x_{0:T})=p_{\theta}(x_T)\prod_{t=1}^{T}p_{\theta}(x_{t-1}\vert x_t)\]그리고 우리의 목표는 파라미터로 남겨놓았던 $\mu_{\theta}$와 $\Sigma_{\theta}$를 잘 학습하는 것, 더 나아가 $p_{\theta}(x_{t-1}\vert x_t)$를 학습하는 것이다.
Forward & Exact Reverse Processes
그럼 Forward Process와 Exact Reverse Process를 좀 더 간단하게 바꿔보자.
우선 Forward Process의 경우, $q_{\phi}(x_t\vert x_{t-1})=\mathcal{N}(\sqrt{\alpha_t}x_{t-1},(1-\alpha_t)I)$이므로
\[x_t=\sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_t}\epsilon_t,\epsilon_t\sim\mathcal{N}(0,I)\]가 된다. $x_t$는 Iterative하게 계산이 가능하므로 위의 식을 반복적으로 적용하면 다음과 같이 $x_0$에 대해서 표현할 수 있다.
\[x_t=\sqrt{\alpha_t \alpha_{t-1}\cdots\alpha_1}x_0+\sum_{s=1}^{t}\sqrt{(1-\alpha_s)\prod_{i=s+1}^{t}\alpha_i}\epsilon_s\]이제 $\bar{\alpha}t=\prod\limits{s=1}^{t}\alpha_s, c_{s,t}=\sqrt{(1-\alpha_s)\prod\limits_{i=s+1}^{t}\alpha_i}$라고 하자. 그러면 다음과 같이 $x_t$를 간단히 쓸 수 있다.
\[x_t=\sqrt{\bar{\alpha}_t}x_0+\sum_{s=1}^{t}c_{s,t}\epsilon_s\]그런데 $c_{s,t}$에 대해 다음의 성질을 얻을 수 있다.
\[\sum_{s=1}^{t}c_{s,t}^2=\sum_{s=1}^{t}(1-\alpha_s)\prod_{i=s+1}^{t}\alpha_i=1-\prod_{i=1}^{t}\alpha_i=1-\bar{\alpha}_t\]따라서 이상의 정보를 종합하면 다음을 얻는다.
\[q(x_t\vert x_0)=\mathcal{N}(\sqrt{\bar{\alpha}_t}x_0,(1-\bar{\alpha}_t)I),\bar{\alpha}_t=\prod_{s=1}^{t}\alpha_s\] \[\therefore x_t=\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}\epsilon,\epsilon\sim\mathcal{N}(0,I)\]이제 다음으로 Exact Reverse Process의 경우, 위에서도 봤듯이 정확한 값을 직접 계산하진 못한다. 그러나 $x_0$에 대한 Conditional distribution을 계산하면 보다 간단히 만들 수는 있다.
\[\begin{aligned} q(x_t\vert x_{t-1})&=\mathcal{N}(\sqrt{\alpha_t}x_{t-1},(1-\alpha_t)I) \\ q(x_t\vert x_0)&=\mathcal{N}(\sqrt{\bar{\alpha}_t}x_0,(1-\bar{\alpha}_t)I) \end{aligned}\]즉 위의 두 식으로부터 $q(x_{t-1}\vert x_t,x_0)$를 유도해보자.
우선 $x_{t-1}\vert x_0$와 $x_t\vert x_0$를 각각 알고 있으므로 이 둘의 Joint Gaussian은 다음과 같다.
\[\begin{pmatrix}x_{t-1} \\ x_t\end{pmatrix}\vert x_0\sim\mathcal{N}\left(\begin{pmatrix}\sqrt{\bar{\alpha}_{t-1}}x_0 \\ \sqrt{\bar{\alpha}_t}x_0\end{pmatrix},\begin{pmatrix}(1-\bar{\alpha}_{t-1})I & \sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})I \\ \sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})I & (1-\bar{\alpha}_t)I\end{pmatrix}\right)\]따라서 다음과 같이 표현할 수 있다.
\[q(x_{t-1}\vert x_t,x_0)=\mathcal{N}(\mu+\Sigma_{12}\Sigma_{22}^{-1}(x_t-\nu),\Sigma_{11}-\Sigma_{12}\Sigma_{22}^{-1}\Sigma_{21})\] \[\mu=\sqrt{\bar{\alpha}_{t-1}}x_0,\nu=\sqrt{\bar{\alpha}_t}x_0,\Sigma_{11}=(1-\bar{\alpha}_{t-1})I,\] \[\Sigma_{22}=(1-\bar{\alpha}_t)I,\Sigma_{12}=\Sigma_{21}^T=\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})I\]이제 이 Gaussian distribution을 간단히 해보자. 우선 이 분포의 평균 $\tilde{\mu}_q(x_t,x_0)$는 다음과 같다.
\[\begin{aligned} \tilde{\mu}_q(x_t,x_0)&=\sqrt{\bar{\alpha}_{t-1}}x_0+\dfrac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}(x_t-\sqrt{\bar{\alpha}_t}x_0) \\ &=\dfrac{\sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)}{1-\bar{\alpha}_t}x_0+\dfrac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_t \end{aligned}\]다음으로 이 분포의 분산 $\tilde{\sigma}_t^2I$는 다음과 같다.
\[\begin{aligned} \tilde{\sigma}_t^2I&=\Sigma_{11}-\Sigma_{12}\Sigma_{22}^{-1}\Sigma_{21} \\ &=(1-\bar{\alpha}_{t-1})I-\dfrac{\alpha_t(1-\bar{\alpha}_{t-1})^2}{1-\bar{\alpha}_t}I \\ &=\dfrac{(1-\bar{\alpha}_{t-1})(1-\alpha_t)}{1-\bar{\alpha}_t}I \end{aligned}\]따라서 이상의 정보를 종합하면 다음과 같은 분포로 표현할 수 있다.
\[q(x_{t-1}\vert x_t,x_0)=\mathcal{N}(\tilde{\mu}_q(x_t,x_0),\tilde{\sigma}_t^2I)\] \[\tilde{\mu}_q(x_t,x_0)=\dfrac{\sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)}{1-\bar{\alpha}_t}x_0+\dfrac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_t,\tilde{\sigma}_t^2=\dfrac{(1-\bar{\alpha}_{t-1})(1-\alpha_t)}{1-\bar{\alpha}_t}\]그리고 이상의 두 성질을 조합해보자. 우선 다음과 같이 $x_0$을 $x_t$에 대해 표현할 수 있다.
\[x_0=\dfrac{x_t-\sqrt{1-\bar{\alpha}_t}\epsilon}{\sqrt{\bar{\alpha}_t}}\]이 값을 $\tilde{\mu}_q(x_t,x_0)$에 대입하면 다음을 얻는다.
\[\begin{aligned} \tilde{\mu}_q(x_t,x_0)&=\dfrac{\sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)}{1-\bar{\alpha}_t}x_0+\dfrac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_t \\ &=\dfrac{\sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)}{1-\bar{\alpha}_t}\cdot\dfrac{x_t-\sqrt{1-\bar{\alpha}_t}\epsilon}{\sqrt{\bar{\alpha}_t}}+\dfrac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_t \\ &=\dfrac{1}{\sqrt{\alpha_t}}\left(x_t-\dfrac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon\right) \end{aligned}\]Parameterizing, Learning, Sampling Reverse Process
이제 이상의 정보들을 가지고 어떻게 학습을 시킬 수 있을지 알아보자. 우선 우리의 목표는 $p_{\theta}(x_{t-1}\vert x_t)$가 가능한 한 $q(x_{t-1}\vert x_t,x_0)$에 근접하게 만드는 것이다. 또한
\[q(x_{t-1}\vert x_t,x_0)=\mathcal{N}(\tilde{\mu}_q(x_t,x_0),\tilde{\sigma}_t^2I)\] \[p_{\theta}(x_{t-1}\vert x_t)\sim\mathcal{N}(\mu_{\theta}(x_t,t),\Sigma_{\theta}(x_t,t))\]이다.
두 개의 Gaussian distribution을 서로 유사하게 만드려면 평균과 분산을 유사하게 만들면 된다. 다행히도 분산의 경우, $q(x_{t-1}\vert x_t,x_0)$의 분산은 $\tilde{\sigma}_t^2I$로 이미 알고 있는 값이라 학습에서 제외할 수 있다.
\[\therefore \Sigma_{\theta}(x_t,t)=\tilde{\sigma}_t^2I\]평균의 경우는 $\tilde{\mu}_q(x_t,x_0)$의 정확한 값을 모르기 때문에 별 수 없이 학습을 거쳐야 한다. 이를 Parameterizing할 수 있는 방법으로 다음의 3가지 방법이 가능하다.
$\mu_{\theta}$를 직접 학습한다.
\[\mu_{\theta}(x_t,t)=UNet_{\theta}(x_t,t)\]가장 직관적으로 생각해볼 수 있는 방법이지만, $\tilde{\mu}_q(x_t,x_0)$가 매우 복잡한 함수라서 UNet에 가해지는 부담이 너무 크다.
$x_0$를 학습한다.
\[\begin{aligned} x_{\theta}^{(0)}(x_t,t)&=UNet_{\theta}(x_t,t) \\ \mu_{\theta}(x_t,t)&=\dfrac{\sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)}{1-\bar{\alpha}_t}x_{\theta}^{(0)}(x_t,t)+\dfrac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_t \end{aligned}\]$x_t$와 $t$를 가지고 $x_0$, 즉 원본 이미지를 예측하는 방식이다. 직관적이긴 하나 이는 결국 각 Step을 건너뛰고 한번에 이미지를 복원하는 시도와 다를 바가 없어서 VAE와 개념적으로 유사하게 된다. 즉, 생성된 이미지의 퀄리티가 떨어진다.
$\epsilon$을 학습한다.
\[\begin{aligned} \epsilon_{\theta}(x_t,t)&=UNet_{\theta}(x_t,t) \\ x_{\theta}^{(0)}(x_t,t)&=\dfrac{x_t-\sqrt{1-\bar{\alpha}_t}\epsilon_{\theta}(x_t,t)}{\sqrt{\bar{\alpha}_t}} \\ \mu_{\theta}(x_t,t)&=\dfrac{\sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)}{1-\bar{\alpha}_t}x_{\theta}^{(0)}(x_t,t)+\dfrac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_t \end{aligned}\]위에서 알아본 고찰로 $x_0$을 $x_t$에 대한 식으로 표현할 수 있고, 이 식에 $\epsilon$이 포함되어 있으니 이를 학습하겠다는 것이다. 또한 이 Noise $\epsilon$은 $\mathcal{N}(0,I)$로 분포가 고정되어 있으므로 학습하기도 쉽다.
이상의 3개의 아이디어 중 DDPM에서는 3번을 택해 $\epsilon$을 학습시키는 것으로 방향을 잡았으며, 실제로 이 쪽이 가장 성능이 높게 나왔다고 한다.
이 방법을 채택한 DDPM에서의 학습 알고리즘은 다음과 같다.
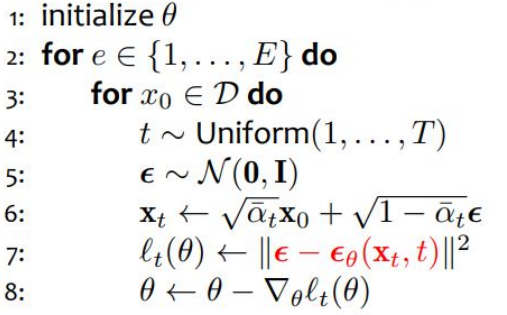
또한 이렇게 학습된 DDPM에서의 샘플링 알고리즘은 다음과 같다.
