Linear Algebra 7 - Normalizing Flow
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Linear Algebra 과목의 수업을 다룬다…만, 과목명은 페이크고 사실은 생성형 모델을 다루는 수업이다.
Prerequisites
Flow-based Generative Model을 이해하기 위해선 먼저 아래의 내용들을 알아야 한다.
Change of Variables는 $X=f(Z)$가 invertible하면 $p_X$를 $p_Z$로 표현할 수 있다는 법칙이다. $Z=f^{-1}(X)=h(X)$라고 하면 1차원에서는 다음과 같이 표현된다.
\[p_X(x)=p_Z(h(x))\vert h^{\prime}(x) \vert\]위의 식을 임의의 $n$차원에 대해 확장하면 다음과 같다. (역함수가 존재해야 하는 특성상 입력과 출력 차원은 동일해야 한다. 즉, $f:\mathbb{R}^n \rightarrow \mathbb{R}^n$이다.)
\[p_X(x)=p_Z(f^{-1}(x))\left\vert\det\left(\dfrac{\partial f^{-1}(x)}{\partial x}\right)\right\vert\]여기서 $\dfrac{\partial f(x)}{\partial x}$를 Jacobian Matrix $J$라고 부르며, $J_{ij}=\dfrac{\partial f_i}{\partial x_j}$이다. 즉, 각각의 차원에 대해 해당하는 편도함수를 각 성분에 따라 배치한 행렬이고, 그래서 $\det$가 정의될 수 있다.
그런데 Determinant는 Time Complexity가 $O(N^3)$일 정도로 굉장히 무거운 연산이다. 그래서 실제로는 Determinant 계산이 간단한 삼각행렬 형태가 되도록 Jacobian Matrix 및 함수 $f$를 유도하는데, 이렇게 해서 나온 Traingular Jacobian Matrix는 역행렬 연산의 Time Complexity가 $O(N)$이 된다.
Flow-based Generative Model
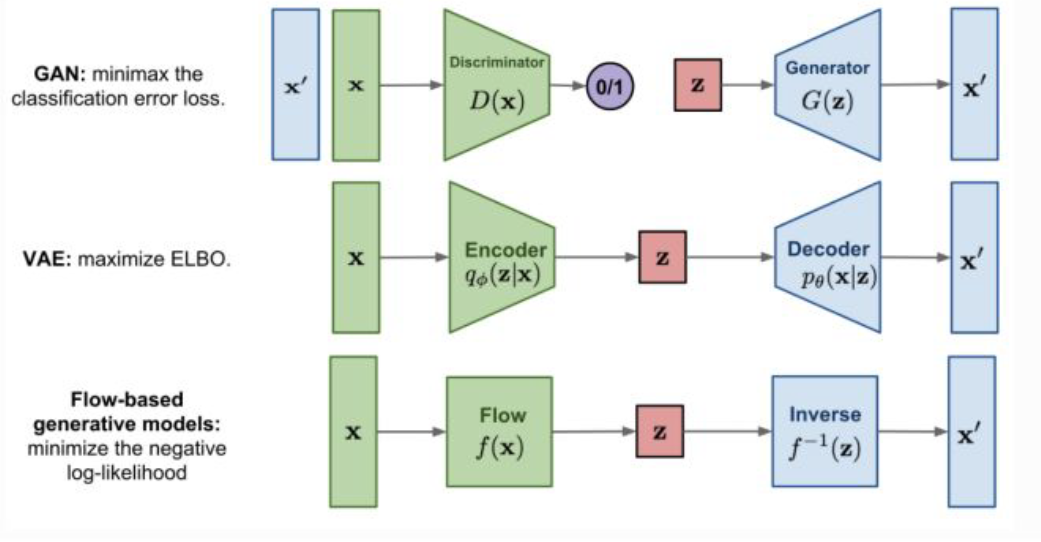
먼저 그동안 다뤘던 Generative Model에 대해 간단하게 알아보자.
VAE는 어찌 보면 “Generative Model”이 해야 하는 일을 가장 정석적으로 구현한 방식이다. Encoder와 Decoder가 존재하며, Encoder를 통해 입력 분포 $x$를 Latent 분포 $z$로 변환하고, 이를 다시 Decoder를 통해 $x^{\prime}$으로 변환하는 방식이다.
VAE를 학습시키기 위해 Reconstruction Loss와 Regularization Loss라는 두 가지 Loss를 다루게 되며 이를 합쳐서 ELBO라고 부른다.
GAN은 Generator와 Discriminator라는 별개의 Neural Network가 존재하며, Generator는 데이터를 만들기만 하고 Discriminator가 이를 구별하는 역할을 한다. 그래서 이 두 네트워크가 서로에게 적대적인 방향으로 동작하여 Generator가 실제 데이터를 직접 보진 못하지만 Discriminator를 통해 간접적으로 학습하게 되는 구조다.
실제로 GAN을 학습시킬 때도 하나의 목적 함수를 Generator는 최소화시키는 방향으로, Discriminator는 최대화시키는 방향으로 학습하게 된다.
이 2개의 Generative Model은 데이터를 생성하는 네트워크를 직접 학습시키기 때문에 Direct Approach라고 부른다.
이번에 다뤄볼 Normalizing Flow를 포함한 Flow-based Generative Model은 위와는 다르게 데이터를 생성하는 네트워크를 직접적으로는 학습시키지 않는 Indirect Approach에 속한다.
“Flow”라는 것은 원래 위상수학에서 온 용어로, 공간 위의 점들이 연속적으로 이동하는 것을 말한다. Generative Model은 분포를 다루는 모델이기 때문에, 여기서는 확률 질량이 한 분포에서 다른 분포로 흘러간다는 의미에서 “Flow”-based라고 부른다.
즉, $x$에서 $z$로 가는 Flow를 한 번 구성해두면 이를 기반으로 반대 방향의 Flow를 복원할 수 있지 않느냐는 논리이다. 그런데 잠깐 Flow를 떼놓고 생각하면 이는 곧 Inverse에 해당한다. 즉, Flow-based Generative Model이란 것은 즉 Network를 invertible하게 구성할 수 있는 모델을 의미한다.
그런데 원리는 간단한데 몇 가지 짚어볼 점이 있다. VAE의 Decoder를 역함수로 대체하는 발상을 실현하기 위해선, $x$와 $z$의 차원이 같아야만 한다. 그러면 $z$의 차원이 일반적으로 $x$의 차원보다 작도록 구성하게 만드는 VAE 및 Autoencoder와는 좀 다른 양상을 띄게 된다. 복원을 전제로 하여 축소시키는 과정에서 원래 데이터의 핵심적인 부분들을 보존하는 것이 Autoencoder 계열 모델의 핵심적인 아이디어인데, 그것이 통째로 결여되었기 때문이다.
VAE에서도 마찬가지로, 핵심적인 부분을 유지하면서 분포를 살리기 때문에 최종적으로 Decoder에 의해 생성되는 데이터가 Input과 아주 동일하지 않고 다양하게 나올 여지를 준다. 그런데 Flow-based Model에서는 이것이 불가능하기 때문에 semantic한 조작이 어렵다는 근본적인 문제가 있고, 이는 곧 생성된 데이터의 품질이 떨어진다는 단점으로 직결된다.
그 대신 역함수를 통해 원본을 그대로 복원할 수 있다는 이 특성으로 인해, 일부 특정 도메인에서는 각광받는 경우가 있다. 대표적인 것이 Scientific Domain으로, 이 경우엔 다양한 데이터보다는 주어진 수식 등에 의한 조건을 만족하는지가 훨씬 중요하기 때문에 범용성의 결여가 그렇게 큰 단점으로 다가오지 않는다.
또한 기본적으로 함수가 invertible하다는 것은 상당히 어려운 조건이다. 그걸 Neural Network같은 복잡한 함수에서 이뤄내야 하는 상황이다. 이 “Invertible Neural Network”를 어떻게 구성하느냐에 따라 같은 Flow-based Generative Model에서도 방법이 갈린다.
Normalizing Flow
Normalizing Flow는 이름에서 유추할 수 있듯이 Flow-based Generative Model의 한 종류이다. 어찌 보면 “Invertible Neural Network”를 구성하기 위해 정공법을 택한 모델이라고 볼 수 있는데, 각각의 함수가 invertible하면 이들을 합성해도 여전히 invertible하다는 점을 이용하여 Invertible한 것으로 알려진 Layer들을 쌓는 방법이기 때문이다.
구체적으로는 다음과 같이 동작한다. 먼저 Gaussian 분포 같이 간단한 분포를 택하고, 이를 출발점 $z_0$로 삼는다. 그 후 여기에 Invertible Transforms를 여러 번 합성해서 우리가 목표로 하는 분포 $x=z_m$을 만드는 것이다. 이 과정을 거꾸로 하면 위의 Flow가 반대로 이동하게 되고, 이는 곧 분포를 여러번 변환해서 Normal한 분포, 즉 Gaussian 분포를 얻는 것이 목적으로 비춰지기 때문에 이 모델을 “Normalizing” Flow라고 부른다.
그리고 이 분포 변환에 위에서 알아본 Change of Variables를 사용한다.
\[p_X(x;\theta)=p_Z(f_{\theta}^{-1}(x))\prod_{m=1}^{M}\left\vert\det\left(\dfrac{\partial (f_{\theta}^m)^{-1}(z_m)}{\partial z_m}\right)\right\vert\]이를 적용하면 $z_m=f_{\theta}^m \circ \cdots \circ f_{\theta}^1(z_0)$에 대한 분포가 위와 같이 정리된다.
그러면 위의 식을 이용해서 Maximum Likelihood Estimation을 구할 수 있다.
\[\max_{\theta}\log p_X(D;\theta)=\sum_{x\in D}\left[\log p_Z(f_{\theta}^{-1}(x))+\sum_{m=1}^{M}\log\left\vert\det\left(\dfrac{\partial f_{\theta}^{-1}(x)}{\partial x}\right)\right\vert\right]\]여태껏 해왔던 것처럼 $\log$를 씌워서 MLE추정을 하면 위와 같은 식을 얻는데, 위의 식은 여태까지의 MLE와는 다르게 정확하게 구할 수 있다. 그래서 이를 Exact Likelihood Evaluation이라고 부른다. 물론 위의 식을 그냥 계산하는 것은 Determinant 연산이 포함되어 있어 많이 어렵다. 그렇기 때문에 Determinant 연산을 간단하게 하기 위해 위에서 다룬 Triangular Jacobian Matrix를 구성하도록 해야 한다. 즉, 안 그래도 까다로운 Invertible 조건에 Jacobian Matrix가 삼각행렬 형태로 구성되어야 한다는 조건까지 추가되어야 Normalizing Flow 모델을 만들 수 있다.
이렇게 Layer를 쌓는 것에 온갖 제약조건이 달려 Layer를 쌓는 것 자체가 상당히 난해하다는 점이 Normalizing Flow의 단점이라고 볼 수 있다. 그러나 이를 극복하고 Layer를 구성할 수만 있다면 Exact Likelihood를 구할 수 있다는 특성 덕분에 Normalizing Flow는 Flow-based Generative Model 중에서도 가장 수학적으로 깔끔하고 안정적이라는 특징을 가진다.