Advanced Machine Learning 10 - CNNs & RNNs (1)
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Advanced Machine Learning 과목의 수업을 다룬다.
Convolutional Neural Networks
저번 글에서 학습 가능과 표현 가능은 다른 개념이라고 했었다. 이 둘의 의미를 좀 더 자세히 살펴보면, 모든 함수를 표현할 수 있다는 것은 곧 “충분한 자원이 주어지면” 학습할 수 있다는 의미가 된다. 그러나 일반적으로 표현력이 높은 모델일수록 학습시키기도 어렵다. 그래서 이 둘의 간극을 좁히기 위해 최대한 학습 난이도를 낮추는 방법을 많이 연구했었는데, 그러한 노력 중 하나에는 데이터의 특징을 잘 파악해서 이를 반영하는 모델을 설계하는 것이 포함되어 있다.
이미 데이터에 대한 특징이 반영되어 있는 모델이라면 해당 종류의 데이터를 학습시킬 때 비교적 적은 노력을 들이지 않겠냐는 논리인데, 실제로 이게 꽤 효과적인 방법이라서 점점 특정 데이터를 다루는 모델의 구조를 설계하는 방향으로 연구가 이루어졌다.
이번 글에서 다룰 CNNs는 그 중 “이미지”를 타겟으로 삼는 모델이다.
Motivations
모델에 이미지를 학습시키는 상황을 가정해보자. 이미지는 일반적으로 각각의 픽셀마다 RGB라는 3개의 0~255 사이의 정수값을 갖지만, 여기서는 단순화하기 위해 Grayscale을 가정해서 픽셀마다 1개의 정수만 가진다고 하자.
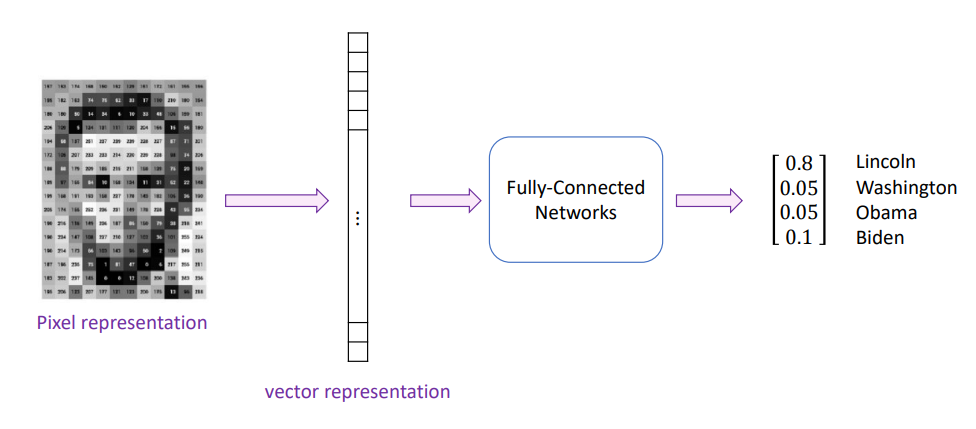
이렇게 이미지를 정수의 배열로 변환할 수 있으니 일단 이대로 MLP에 넣어볼 수는 있다. 그리고 실제로 추론 결과가 나올 것이다. 그러나 입력 데이터가 이미지라는 것을 생각해보자. 이미지는 그 특성상 패딩이 존재해도 같은 의미를 가진다. 그러나 입력 벡터만 따져보면 패딩으로 인해 각 픽셀의 위치가 변경되게 되고, 따라서 MLP는 이 두 이미지를 전혀 다른 입력값으로 인식하게 된다.
MLP는 이러한 이미지의 중요한 특성 중 하나인 “Invariant to affine transformations”를 제대로 반영하지 못한다. 이렇게 되면 이미지에서 발생할 수 있는 다양한 노이즈 및 변형 등이 전부 처음 보는 데이터가 되고, 이는 곧 Overfitting을 야기하게 된다.
그렇기 때문에 이미지를 학습하기 위해선 MLP가 아닌 다른 형태의 모델이 필요하다.
CNNs
그러한 “다른 형태의 모델” 중 가장 대표적인 것이 Convolutional Neural Networks, 즉 CNNs이다. 이 모델은 이미지의 공간적 특성을 유지하기 위해 Convolutional Filter라는 개념을 사용한다.
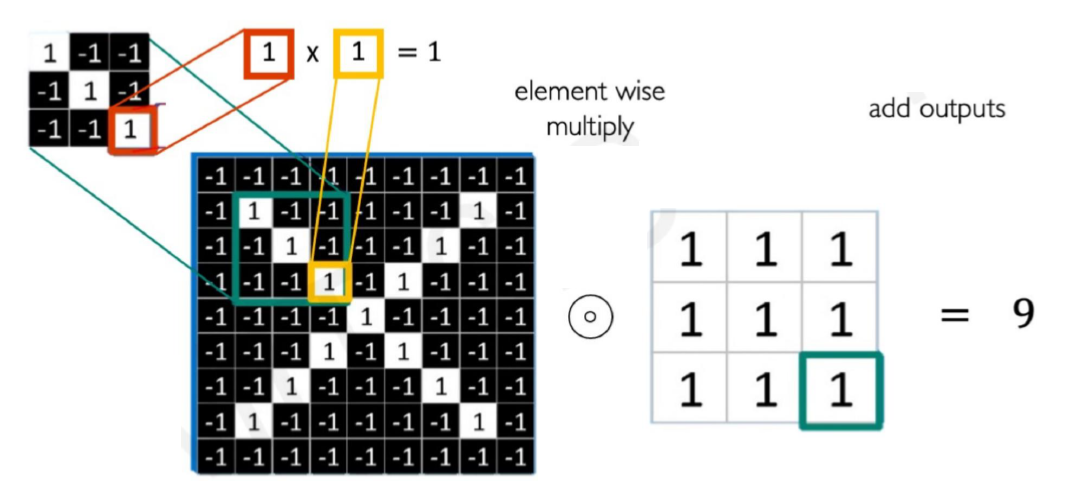
공간적인 특성을 유지하면서 학습을 시키려면 위와 같이 조그마한 크기의 필터를 사용해서, 이 필터가 전체 이미지를 전부 “훑어보는” 식으로 계산해야 한다. 이 계산에는 Convolution 연산을 사용하는데, 간단하게 같은 위치의 값들끼리 곱한 값을 더하는 것이다. 당연히 그 값이 클수록 필터와 유사하다는 의미가 된다.
즉 위의 사진과 같은 상황이라면 이미지의 3x3부분마다 주어진 필터와 얼마나 일치하는지를 따지게 된다.
여담으로 CNNs에서 Convolutional Filter라는 단어는 원래 ML이 아니라 Linear Time-Invariant (LTI) System 등에서 사용되던 연산인 “Convolution Operation”에서 유래되었다. 이는 다음과 같이 정의된다.
\[(f\ast g)(t)=\int_{-\infty}^{\infty}f(\tau)\cdot g(t-\tau) d\tau\]그런데 위에서 알아본 CNNs는 이 연산을 그대로 사용하진 않는다는 것을 알 수 있다. 정확히는 원래 Convolution Operation은 특정 시간을 기준으로 뒤집어서 계산하는데, 이 점만 제외하고 그대로 가져다 쓴 형태라 그냥 Convolutional Neural Networks라고 부른다.
다시 원래의 CNNs로 돌아가보자.
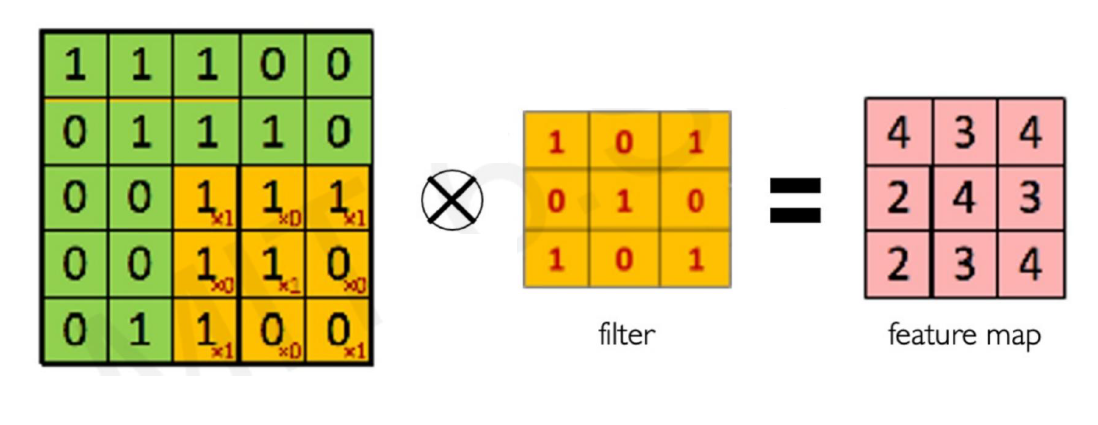
하나의 Convolutional Filter를 통해서 이미지를 훑어보면서 계산한 행렬을 Feature Map이라고 부른다. 그리고 대부분의 CNNs에서는 이러한 Feature Map을 여러 개 만들어서 계산한다. 이는 하나의 Convolutional Filter는 입력값으로 주어진 이미지에서 하나의 특징만을 포착할 수 있기 때문이다. 이미지를 여러 방면에서 확인하기 위해선 당연히 다각도로 확인해야 하고 그렇기 때문에 Convolutional Filter도 여러 개가 필요하다.
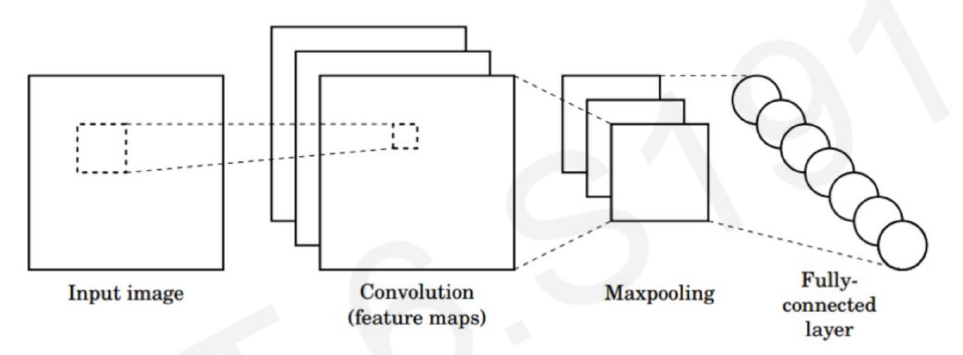
그리고 이러한 Feature Map을 그대로 MLP에 넣어서 유의미한 정보를 추출하기에는 크기가 너무 크기 때문에 그 사이에 Pooling을 추가한다. 이는 Feature Map의 크기를 줄이는, 즉 Downsampling을 하면서 최대한 유의미한 정보를 보존하기 위한 Layer로, 보통 일정 구역 내의 최댓값을 취하는 Max Pooling, 혹은 평균값을 취하는 Average Pooling을 사용한다.
이 과정을 반복해서 원래 이미지 정보를 충분히 작은 크기로 압축을 시키고, 그 후에 MLP를 통해 우리가 원하는 정보를 뽑아낼 수 있는데, 이 일련의 과정들이 바로 CNNs의 전체 구조가 된다. 이 과정에서 활성화 함수는 주로 ReLU를 사용한다.
Sequence Modeling Problem
RNNs는 Sequential Data를 다루기 위해 고안된 모델이다. 이러한 Sequential Data는 생각보다 많이 보이고 또 범용적인 형태인데, 시간 순으로 나열되는 데이터인 오디오나 Speech는 물론이고 심지어는 자연어 텍스트나 코드 같이 딱히 시간의 영향을 받지는 않더라도 순서 개념이 존재하는 모든 데이터에도 다 적용할 수 있다.
이러한 Sequential Data를 어떻게 다룰 수 있을지, 그리고 이를 다루기 위해 필요한 모델의 조건에 대해 알아보자.

다양한 Sequence Modeling 상황 중, 다음 단어를 추론하는 문제를 푸는 모델을 설계하려고 한다고 가정하자. 이게 되어야 추론한 단어를 다시 입력으로 넣는 방식으로 모델 자체적으로 완성된 문장을 만들 수 있다. 여담으로 이러한 모델을 Auto-regressive Modeling이라고 부른다.
이 문제의 경우 입력값이 자연어 문장이기 때문에 길이가 가변적이다. 그래서 입력값의 크기가 고정되는 일반적인 MLP를 그대로 사용할 수는 없다.
이를 해결하기 위한 첫 번째 시도로, 작은 Window를 설정해서 슬라이딩 하듯이 입력값을 주는 방법을 생각해볼 수 있다.

이러면 입력값을 더 이상 가변적인 길이로 받지는 않지만, 대신에 아주 짧은 앞의 몇 개 단어만 보고 뒤를 맞추려고만 시도하게 된다. 이러면 문장의 전체적인 맥락을 파악하지 못하는 문제, 즉 Long-term dependency를 잘 잡지 못하는 문제가 생긴다.
두 번째 시도로, 전체 문장을 “Bag of words”로 변환하는 방식을 생각해볼 수 있다.
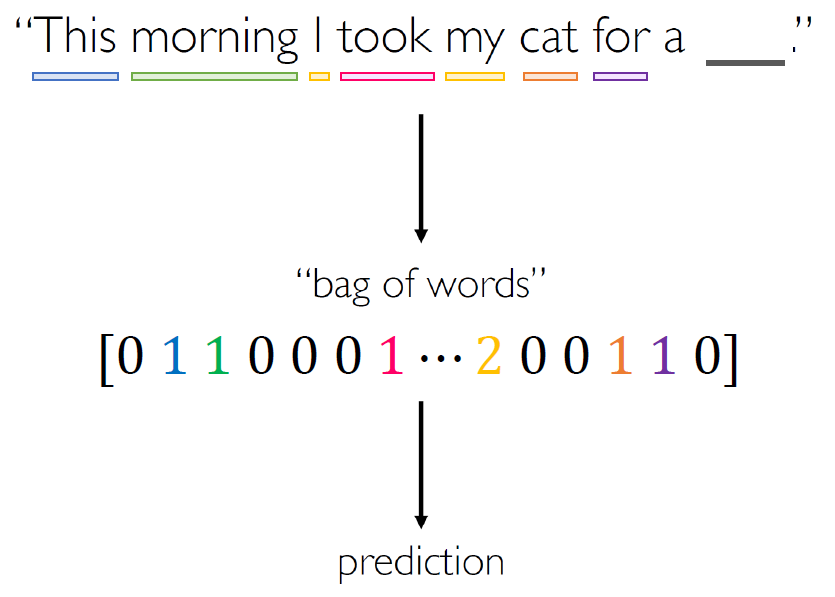
단어의 개수는 결국 유한하기 때문에 입력 크기를 고정시킬 수 있게 된다. 그러나 이 경우는 단어의 순서를 잃어버리게 되는데, 이는 자연어에서, 그리고 더 나아가서 Sequential Data에서 매우 중요한 정보이다. 그렇기 때문에 이러한 형태는 원래 데이터의 정보를 제대로 살릴 수 없는, 좋지 않은 구조가 된다. 이는 “The food was good, not bad at all.”과 “The food was bad, not good at all.”이라는 두 문장을 비교해보면 바로 알 수 있다. 이 둘은 서로 동일한 단어 집합을 사용했으나 의미는 정반대인데, Bag of words 방식은 이들을 동일한 입력값으로 취급하게 된다.
세 번째 시도로, 첫 번째 시도에서 사용했던 “Fixed window”에서 그 window의 크기를 매우 크게 늘리는 방법을 생각해볼 수 있다.
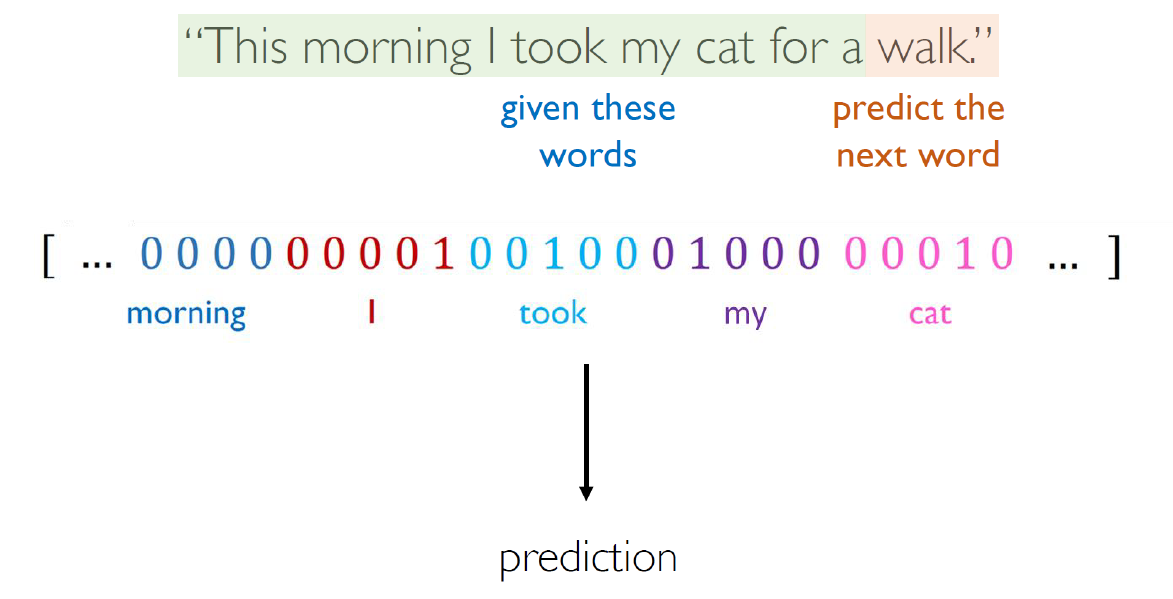
그러나 이 경우엔 CNN에서 다뤄봤던 그 문제가 그대로 나타나게 된다. 즉, 전체 문장을 입력값으로 받게 되면, 문장 내의 사소한 단어 변경, 순서 변경 하나하나마다 완전히 다른 입력값이 되어 Overfitting 문제에 취약해지게 된다. 그래서 결국 이러한 방식도 Sequential Data의 특성을 제대로 살리지 못한다.
위의 시도들을 통해 알 수 있는 이 모델의 조건은 다음과 같다.
- 가변적인 크기의 입력을 다룰 수 있어야 하고,
- Long-term dependency를 처리할 수 있어야 하며,
- 순서 정보를 보존해야 한다.
결국 CNN이 이미지의 공간적 특성을 살리기 위해 파라미터를 공유한 것처럼, Sequential Data에서도 파라미터 공유를 통해 순서 정보를 반영해야 한다는 것이 초창기의 아이디어였다.
그리고 이러한 문제들을 잘 해결할 수 있는 구조가 바로 Recurrent Neural Networks, 즉 RNN이다.
Recurrent Neural Networks
Sequential Data의 구조를 살리려면 사람의 뇌와 같이 네트워크 중간에 Sequential Memory를 담당하는 부분이 필요하다.
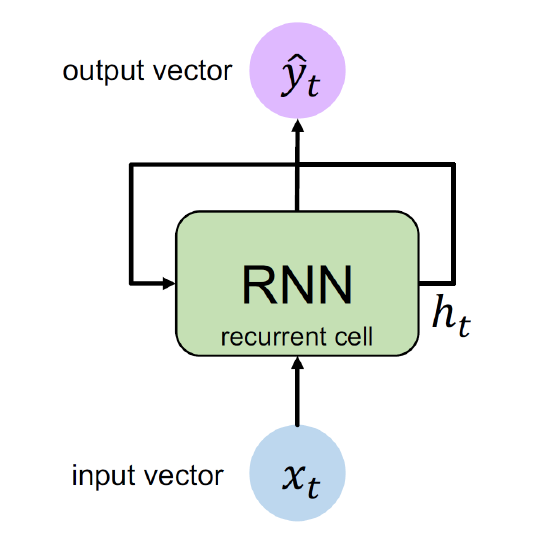
RNN은 이러한 구조를 반영한 모델로, 네트워크 내부에 Hidden State $h_t$가 존재한다. 여기서의 $t$는 Step을 의미하는데, 즉 $t$번째 Step에서의 추론값은 $t-1$번째 Step에서의 Hidden State값의 영향을 받는다는 의미이다. 이것이 Sequential Memory의 역할을 한다.
\[h_t=\tanh(W_{hh}h_{t-1}+W_{xh}x_t)\] \[\hat{y_t}=W_{hy}h_t\]구체적으론 위와 같이 표현된다. 즉 여기서는 Activation function으로 $\tanh$를 사용한다. 이는 Hidden State가 반복적으로 계산되는 특성상 값의 범위가 $[-1,1]$ 사이로 유지되는 것이 가장 이상적이기 때문이다. 또한 파라미터는 어디에서 사용되느냐에 따라 $W_{hh}$와 $W_{xh}$, 그리고 $W_{hy}$의 3개로 나뉘어지는데, 특이한 점으로 이들 모두 Step $t$와는 무관하다. 즉, RNN 전체에 걸쳐서 모두 동일한 공유 파라미터를 사용하며, 이는 위에서 알아본 디자인 조건 중 하나와 동일하다.
그리고 매 Step마다 연산이 수행되는 특성상 가변적인 길이도 자연스럽게 다룰 수 있다. 또한 Input Vector가 $t$에 따라 쪼개진 $x_t$의 형태로 들어오므로 데이터의 순서 역시 보존될 수 있다. 마지막으로 이런 식으로 구성된 Hidden State는 최초의 입력 $x_1$부터 $x_t$까지의 모든 입력값이 다 반영되었으므로 Long-term dependency 또한 반영되어 있다고 할 수 있다.
물론 이는 이론상, 이상적인 이야기일 뿐이고, 실제로 Vanilla RNN은 Long-term dependency를 제대로 반영하지 못하는 문제가 존재한다. 이는 학습 과정에서의 문제고, 이를 해결하기 위해 LSTM이나 GRU같은 변형 RNN이 등장하게 되었다.