Advanced Machine Learning 12 - Transformer (2)
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Advanced Machine Learning 과목의 수업을 다룬다.
Transformer
저번 글에서 RNN의 근본적인 한계점에 대해 알아봤는데, 이러한 문제점들 때문에 RNN 기반의 구조를 아예 버리는 연구가 이루어졌다.
그 유명한 Attention is All You Need (Vaswani et al., NIPS, 2017)도 그러한 시도에서 탄생한 논문이며, 여기서는 Transformer라는 구조를 제안했다. 이 Transformer는 RNN 계열의 모델과 다르게 학습할 때엔 병렬로 처리가 가능한데, 어떻게 이게 가능한지 알아보자.
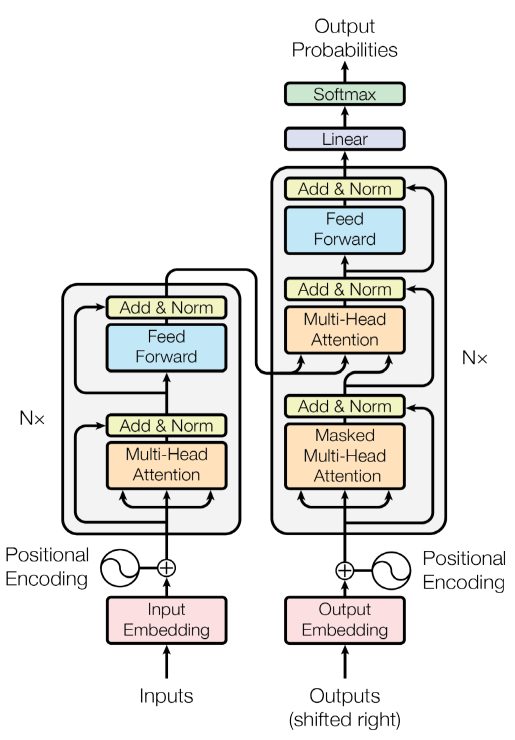
우선 Transformer의 전체 구조는 위와 같다. 원 논문에서는 기계 번역 문제를 해결하기 위해 위의 구조를 제안했는데, 여기서는 그 때 제안된 구조를 그대로 볼 것이다.
간략한 흐름을 보면, Input이 들어오면 가장 먼저 이를 Embedding 차원으로 바꾼다. 그 후 위치 정보를 추가로 제공하는 Positional Encoding을 추가한다. 그리고 왼쪽의 영역을 통과하는데, 이 영역에서는 Input이 가지고 있는 관계를 함축적으로 내포한 형태로 바꿔준다. 이 영역을 Encoder Block이라고 한다.
이제 오른쪽 영역을 보자. 이 영역을 Decoder Block이라고 하는데, 실질적으로 번역된 문장이 출력되는 곳이다. 이는 Next Word Prediction 문제기 때문에, 이미 앞서 생성된 번역된 문장이 그대로 Decoder의 Input으로 들어간다. 이것이 Decoder 하단의 Outputs이다. Encoder Block과 마찬가지로 Embedding 과정을 거쳐서 Decoder Block에 진입하여 최종적인 Prediction을 리턴한다. 이 Prediction은 Softmax로, 즉 다음 단어의 확률로 나오며, 실질적인 문장은 이 확률대로 샘플링하여 구성하게 된다.
Transformer의 전체적인 구조는 이와 같다. 이제부터 각 구성 요소를 하나씩 자세히 살펴보자.
Embedding
Transformer의 입력으로 들어오는 것은 자연어 문장이다. 그러나 모델은 기본적으로 모든 입력값을 벡터로 받아야 한다. 따라서 자연어를 벡터로 변환할 방법이 필요하다. 물론 특정 자연어에 존재하는 단어의 개수는 유한하기 때문에 One-hot vector로 하라면 할 수는 있겠으나, 이는 차원이 너무 커져서 사실상 불가능에 가까운 방법이었다.
이를 위해 고안된 다른 방법 중 하나가 Word Embedding이다.
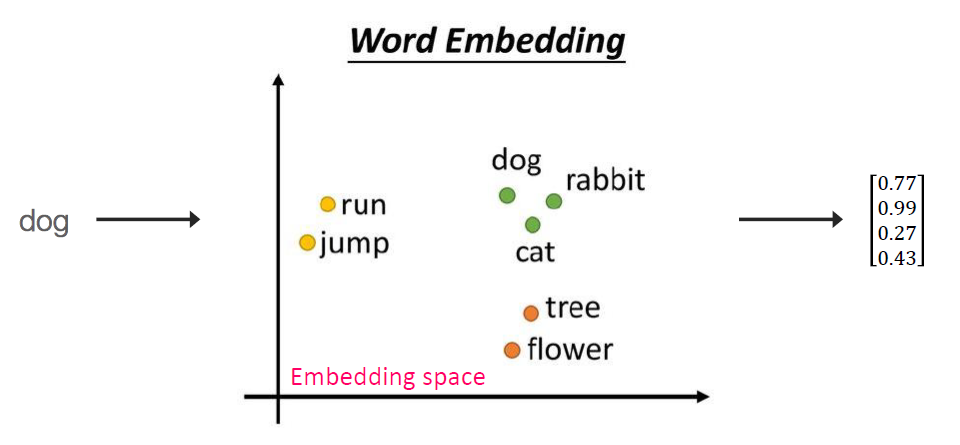
Word Embedding은 말 그대로 단어를 하나의 벡터에 대응시키는 Embedding 방법인데, 그 중에서도 특히 단어는 그 자체로 의미를 가진다는 점에 주목했다. 즉, 위 그림과 같이 서로 비슷한 의미의 단어를 비슷한 공간에 매핑시켜놓은 것이다.
그러나 Word Embedding은 단어에만 대응되는데, 한 문장 내에서 단어의 위치가 중요한 경우가 존재하기 때문에 이것만 가지고는 단어의 의미를 제대로 살려내질 못하는 문제점이 있다. 그렇기 때문에 이 Word Embedding에 더해 이 벡터가 전체 Input 중 어디에 위치했느냐를 알려주는 Positional Encoder를 같이 넣어줘야 한다.
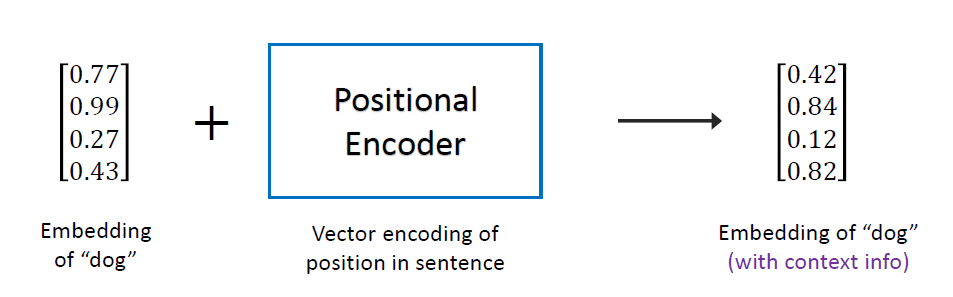
실제론 위 그림과 같이 Word Embedding으로 매핑된 값에 Positional Encoder에 의해 계산된 값을 반영하여 Input Embedding으로 들어갈 각 단어의 값이 바뀌게 된다. 이 Positional Encoder의 계산식은 모델마다 다른데, 원본 Transformer에서는 아래의 식을 사용했다.
\[\begin{aligned} PE_{(pos,2i)}&=\sin(pos/10000^{2i/d_{model}}) \\ PE_{(pos,2i+1)}&=\cos(pos/10000^{2i/d_{model}}) \end{aligned}\]이러한 위치 정보는 사실 RNN을 비롯한 Sequential Data를 다루는 모델이 처리해야 할 정보인데, 후술하겠지만 Transformer의 핵심이 되는 Attention 연산은 이러한 위치 정보를 직접적으로는 파악할 수 없어서 이런 식으로 강제로 넣어줘야 한다.
여담으로 요즘은 Word Embedding 방식을 쓰지 않고, 대신 Tokenizer를 사용한다. Word Embedding으로 매핑시키면 Input 단계에서부터 일종의 Inductive Bias를 걸어주는 셈인데, 이것이 Word Embedding의 장점이긴 하지만 이 또한 모델의 사고를 강제시키기 때문이다. 요즘은 이러한 식의 Inductive Bias를 최대한 배제하고 더 많은 데이터를 준비하여, 모델이 학습 중 자연스럽게 익힐 수 있도록 유도한다. 물론 Positional Encoding 개념은 지금까지도 살아남아 여전히 쓰이고 있다.
Encoder Block
Attention
Encoder를 알아보기 전에 먼저 Encoder Block의 핵심이 되는 Attention 개념에 대해 알아보자. Attention은 실제로 사람들이 정보를 받아들이거나 대조할 때 뇌에서 일어나는 기저 작용이라고 한다. 이는 굳이 이미지에 국한된 것은 아니고, 모든 종류의 데이터에서 공통적으로 일어나는 현상이다.

ML에서의 Attention은 바로 이 Attention 작용을 모방한 것이다. 위의 사진을 보면 “The big red dog”란 Sequence를 순차적으로 볼 때 각 단어 중 어디에 집중해서 보는가를 알 수 있다. 가장 높은 가중치가 걸린 것은 당연히 자기 자신이지만, “The”, “big”, “red”를 볼 때 “dog”에 2번째로 높은 가중치가 걸려 있음을 알 수 있다. 실제로도 이 영어 구절을 보면 “dog”가 가장 중요하기 때문에 어느 정도 말이 되는 형태로 Attention Vector가 형성되었음을 알 수 있다.
또한 Input Sequence 내의 각 단어끼리 서로의 연관관계를 파악했는데, 이런 식으로 자기 자신의 Attention Vector를 구하는 것을 Self Attention이라고 한다.
참고로 이 Attention 메커니즘은 Transformer에서 처음 제안된 것은 아니다. 초창기엔 RNN 계열의 모델에서 Attention을 넣으려는 시도를 많이 했었는데, 다른 과목에서 다룬 내용이지만 이 글에 보다 자세한 설명이 있다.
Multi-Head Self Attention Block
그럼 이제 Transformer에서 이 Attention 개념을 구체적으로 어떻게 적용했는지 알아보자.
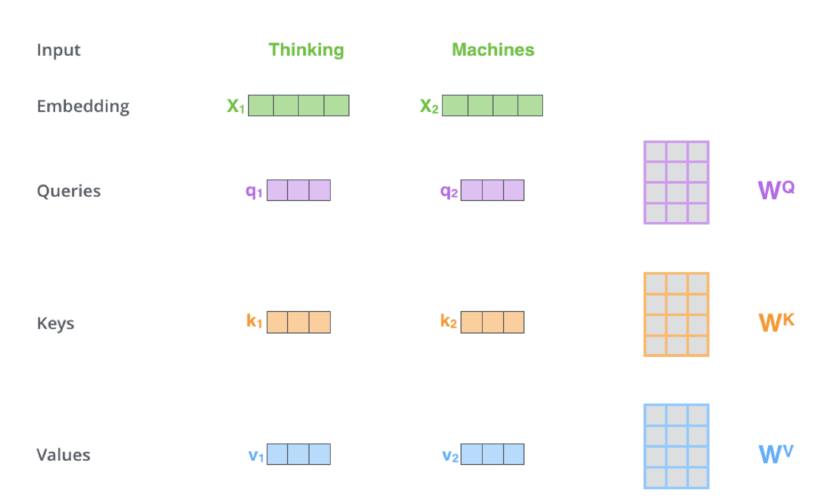
위의 그림과 같이 “Thinking Machine”이라는 Input이 들어왔다고 가정하자. 이것이 Embedding 과정을 통해 두 벡터 $X_1$과 $X_2$로 변환되어 Encoder Block에 들어온다. 이 각각의 벡터에 대해, 3개의 행렬 $W^Q$, $W^K$, $W^V$를 각각 곱하여 Query, Key, Value의 쌍 $(q_1,k_1,v_1)=(X_1 W^Q,X_1 W^K,X_1 W^V)$, $(q_2,k_2,v_2)=(X_2 W^Q, X_2 W^K, X_2 W^V)$를 얻는다. 여기서 나온 이 3개의 행렬은 각각 학습을 통해 구하는 값이며, 모든 Input Sequence에 대해 같은 값을 사용한다.
Attention Vector는 이렇게 구해진 Query, Key, Value의 쌍을 가지고 아래와 같이 계산하여 얻는다.
\[Z=softmax\left(\dfrac{Q\cdot K^T}{\sqrt{\text{Dimension of vector }Q\text{ or }K}}\right)\cdot V\]이 연산의 핵심은 Softmax의 분자로 들어가 있는 $Q\cdot K^T$이다. 간단하게 $Q=\begin{pmatrix}q_1 & q_2 & \cdots & q_n\end{pmatrix}^T$, $K=\begin{pmatrix}k_1 & k_2 & \cdots & k_n\end{pmatrix}^T$라고 해보자. 이러면 $Q\cdot K^T$는 다음과 같이 계산된다.
\[Q\cdot K^T=\begin{pmatrix}q_1^T k_1 & q_1^T k_2 & \cdots & q_1^T k_n \\ q_2^T k_1 & q_2^T k_2 & \cdots & q_2^T k_n \\ \vdots & \vdots & \ddots & \vdots \\ q_n^T k_1 & q_n^T k_2 & \cdots & q_n^T k_n \end{pmatrix}\]이러한 행렬이 만들어진다. 그런데 $Q$와 $K$가 각각 Sequence에서 파생된 값임을 생각해보면, 이는 곧 Sequence의 모든 원소에 대한 각각의 관계를 하나하나 다 구한 것과 동일하다.
또한 이렇게 처리하게 되면 RNN 계열에서 결국 제대로 잡지 못한 Long-Term Dependency 문제도 자연스럽게 해결된다. 위의 Attention 계산을 잘 보면 거리 개념을 무시하고 모든 원소 간의 모든 관계를 다 구하게 된다. 즉, 아무리 거리가 멀어도 Attention은 제대로 계산되며 이를 통해 아무리 먼 거리의 원소여도 제대로 계산이 가능하다는 이야기가 된다.
그리고 잘 보면 “Multi-Head” Self Attention Block이라고 되어 있다. 이 Multi-Head라는 말은 Attention 연산을 서로 다른 관점으로 여러 번 수행했다는 의미이다. 즉, 위에서 본 3개의 행렬 $W^Q$, $W^K$, $W^V$를 여러 쌍 학습시켜서 이 각 쌍들에 대한 Attention을 계산한 후 병합한다. 이는 마치 CNN에서 Filter 및 Channel을 여러 개 만드는 것과 동일하다. 당연하게도 이 각각의 Attention 연산들은 독립적이므로 병렬 처리가 가능하다.
그리고 위의 구조에 Residual Connection 및 Layer Normalization을 추가하여 Attention Block을 완성한다. 이들은 Transformer에서 제안된 구조는 아니며, Residual Connection은 깊은 네트워크에서도 Gradient가 잘 흐르게 하는 역할을, Layer Normalization은 각 토큰의 Feature 차원을 정규화하여 분포가 튀는 현상을 방지한다. 즉, 둘 다 학습을 잘 하기 위한 목적으로 일반적으로 넣는 장치들이다.
이렇게 Attention Block을 통과시킨 후 이 정보를 잘 섞어주기 위해 Feedforward Network까지 통과시킨다. 이것이 Encoder Block의 전체적인 과정인데, Transformer 모델에서는 이 Encoder Block을 여러 번 반복하며, 원 논문에서는 6회 반복한 구조를 제안했다.
Decoder Block
Masked Multi-Head Self Attention Block
Decoder Block은 Encoder Block과 거의 유사한 형태로 이루어져 있다. 그러나 자세히 보면 좀 다른 부분이 있는데 우선 처음으로 등장하는 Attention Block을 보면 Masked라고 되어 있다.
Decoder Block의 Input Sequence를 생각해보자. 논문에서 소개된 Transformer 모델은 기계 번역을 위한 모델이다. 즉, Decoder는 Next Word Prediction 문제를 푸는 모델이며, 이를 위해 첫 단어를 생성한 후 그것이 그대로 입력값으로 들어오게 되는 식으로 동작하는 Auto Regressive Model이다.

그렇기 때문에 학습 데이터로 전체 번역된 문장을 던져주고 그걸 그대로 학습시키면 정상적인 상황에서는 볼 수 없을 “미래 데이터”를 보고 학습하게 된다. 그렇기에 위의 그림처럼 현재 보는 단어를 기준으로, 그 뒤의 단어를 가려서 보지 못하게 만드는 Masking 처리를 한다. 물론 실제로는 Masking 처리를 직접 하진 않고 Attention Vector의 값에 매우 큰 음수를 더해서 해당 위치의 Softmax 결과가 0에 가깝게 수렴하도록 만드는 식으로 구현하는데, 이런 식으로 동작하는 이 Attention 연산을 Masked Multi-Head Self Attention이라고 부른다. 그 외에는 Encoder Block에 존재하는 Multi-Head Self Attention과 동일하다.
Multi-Head Cross Attention Block
Decoder Block은 Attention Block이 2개 존재한다. 1번째 Block에서 여태까지 생성해낸 Sequence에서 Self Attention을 계산한 후, Encoder로부터 받아온 정보와 1번째 Attention Block에서 계산한 정보를 가지고 다시 Attention 연산을 수행해야 한다.
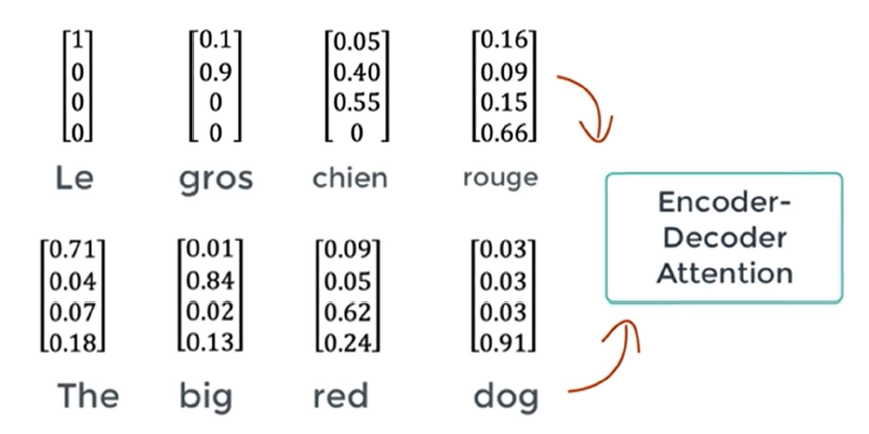
이렇게 서로 다른 Sequence 간의 관계도를 계산해야 서로 다른 언어로 된 두 Sequence가 얼마나 유사한지를 파악하여 원래 의도대로 기계 번역을 수행할 수 있다. 이렇게 서로 다른 Sequence 간에 계산하는 Attention을 Cross Attention이라고 부른다.
그 후에는 역시 Encoder Block과 동일하다. 즉, Residual Connection이 포함되고, Layer Normalization이 추가되며, 최종적으로 Feedforward Network까지 묶어서 한 세트로 구성된 Decoder Block을 여러 번 반복한다. 원 논문에서는 6회 반복하는 것마저도 Encoder Block과 동일하다.
다만 Decoder Block에서는 최종적으로 다음 단어를 뱉어내야 하기 때문에, 마지막은 Auto Regressive Model과 동일한 절차를 따른다. 즉, 모든 Decoder Block을 통과하면 마지막으로 Feedforward Network 및 Softmax를 통과시켜 각 단어가 나올 확률을 계산하고, 이 확률대로 샘플링하여 최종적인 단어를 하나씩 추론하게 된다. 당연하지만 학습 시에는 Masked Self Attention을 사용하여 병렬로 가능하다고 해도 추론 시에는 이전 단어를 그대로 넣어서 다음 단어를 추론해야 하기 때문에 Sequential하게 수행된다.
여기까지가 Transformer 모델의 구조이다. 현재 대부분의 LLM 모델들은 이를 기반으로 하여 구성되었는데, 사실 Transformer 또한 완전무결한 구조는 아니다. 대표적인 약점으로 지적되는 것이 바로 Attention 연산인데, 위에서 봤듯이 모든 원소 간의 Attention Score를 계산하다보니 필연적으로 시간복잡도가 $O(N^2)$이 된다. 이는 Sequence의 길이가 길어질수록 더더욱 부담이 심해지게 된다.
물론 이를 개선하고자 하는 연구도 많이 이루어졌으나 안타깝게도 현재까지는 GPU의 성능을 올리거나 Flash Attention과 같이 하드웨어적인 최적화 및 캐싱을 두는 식이 가장 유효한 방법이라고 하며, 위의 시간복잡도 문제를 해결할만한 뾰족한 대안은 아직 등장하지 않았다.
BERT: Bidirectional Encoder Representations from Transformers
여태까지 알아본 내용은 최초로 제안되었던 Transformer 모델의 구조이다. 이 구조가 제안된 이후 NLP 관련 연구의 판도가 바뀌어 RNN을 고수하던 사람들이 전부 Transformer를 활용하는 연구로 전환을 하기 시작했다. 여기서 소개할 BERT 역시 그러한 연구 중 하나로 제안된 모델이다.
BERT는 Google에서 제안된 모델로, Transformer에서 Encoder Block 부분만 떼내서 독자적으로 활용할 수 있게 고안된 모델이다. 즉, BERT는 Encoder만 있기 때문에 Input Sequence를 받아서 그 의미를 잘 파악하는 것까지만 목적인 모델이다.
Masked Language Models
그런데 BERT는 Decoder가 없기 때문에 원래 Transformer와 달리 Next Word Prediction과 같은 명확한 출력이 존재하지 않고, 따라서 Transformer와는 다른 학습 방법이 필요하다. 이를 위해 고안된 것이 Masked Language Models, 즉 MLM이다.
MLM은 Self-Supervised Learning의 일종으로, 주어진 문장에서 일부분을 Masking한 후 그 Masking된 영역에 어떤 단어가 들어가야 하는지를 맞추는 방식이다. 이러한 방식은 “Inpainting”이라는 이름으로 기존에 존재했던 방법론인데, Inpainting에서는 이미지를 대상으로 한다. 즉, 이미지의 특정 영역을 지워놓고 해당 부분을 복원하라는 식으로 학습을 시키는 것인데, 이것이 그리 쉬운 작업은 아니라서 Inpainting 방법을 활용해 성공적으로 학습에 성공한 모델은 성능이 매우 좋아졌다는 연구 결과가 존재한다. MLM이 바로 이 Inpainting을 NLP에 적용한 예시이다.
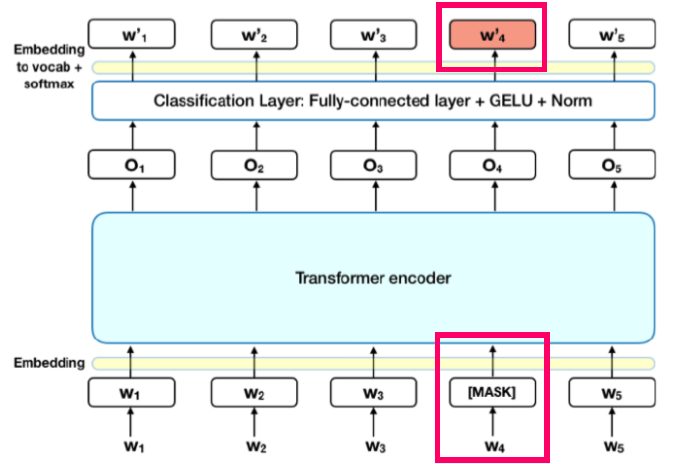
위 그림과 같이 Input Embedding에 한 영역 (여기서는 $w_4$)에 Masking 처리를 하고 그 영역에 실제로 어울리는 단어를 찾아서 넣으라는 방식이다. 그럼 이 방식이 왜 효율적일까? 문장에서 빈 단어를 말이 되게 채우려면 그 문장의 문맥을 이해해야 하기 때문이다. 즉, 빈 단어를 채워가는 과정에서 이 문장의 문맥을 제대로 이해할 수 있도록 유도되는 것이고, 이것이 곧 Encoder의 품질 상승으로 이어진다.
여담으로 이 Masking의 적절한 비율에 대해서도 연구가 이루어졌는데, 15% 정도를 Masking하는 것이 가장 효율이 좋은 것으로 밝혀졌다. 그러나 왜 하필 15%인지에 대한 명확한 이유는 아직 밝혀지지 않은 상태이다.
또한 MLM의 경우 단어 단위로 Masking을 하다 보니 연속된 $n$개의 단어가 하나의 구절로써 쓰이는 n-gram에 많이 취약하다는 점이 발견되었다. 이러한 점들을 보완하기 위해 Whole-word Masking (WW-BERT), Random-span Masking (SpanBERT) 등과 같은 Masking에 관련된 다른 후속 연구들이 많이 이루어졌다고 한다.
마지막으로 사실 BERT는 이 MLM 외에도 Next Sentence Prediction, 즉 NSP 문제로도 학습을 진행했었다. NSP 문제는 임의의 2개의 문장을 주고, 이 두 문장이 연속된 문장인지를 맞추는 것이다. 그러나 이 문제는 최초의 기대와는 다르게 MLM 문제와는 달리 성능에 크게 영향을 미치지 않았음이 밝혀졌다.