Deep Learning 6 - Attention & Transformer
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Deep Learning 과목의 수업을 다룬다.
Seq2Seq
Seq2Seq는 가변적인 길이의 Input Sequence를 입력받아 역시 가변적인 길이의 Output Sequence로 변환하는 모델이다. 이러한 형태의 문제는 서로 다른 언어 간의 번역기나 질문-답변으로 이루어지는 대화, Image Captioning 등등 생각보다 흔하게 볼 수 있다.
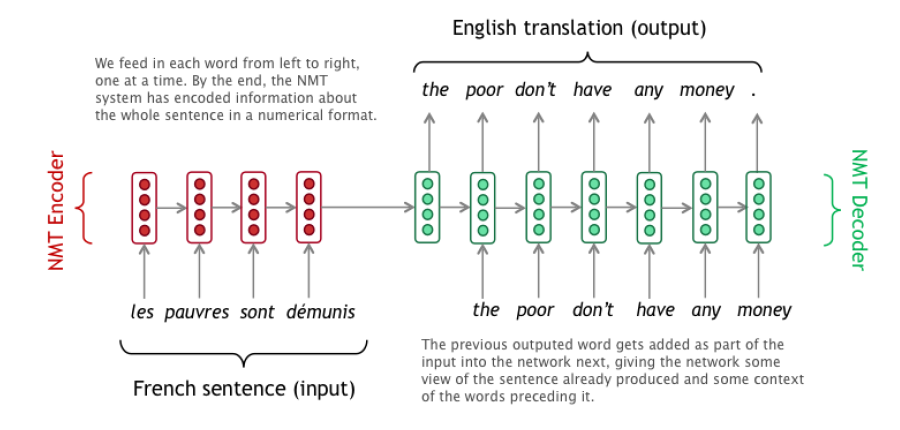
이러한 Seq2Seq 모델은 위와 같이 Encoder와 Decoder로 분리된 구조로 구현한다. Encoder에서는 Input Sequence를 받아 그 정보를 압축한 Context Vector를 생성한다. 그리고 이 정보를 그대로 Decoder에게 넘기는데, Decoder는 이 Context Vector를 가지고 Output Sequence를 생성하는 것이다.
그렇다면 이 Encoder와 Decoder는 각각 어떤 모델을 사용해야 할까? Sequence를 받고 Sequence를 생성하는 특성상 여태까지 배운 지식으로는 둘 다 RNN으로 구현하는 것이 가장 자연스럽다.
그런데 Encoder와 Decoder를 RNN으로 구현할 경우, 치명적인 문제가 몇 개 존재한다.
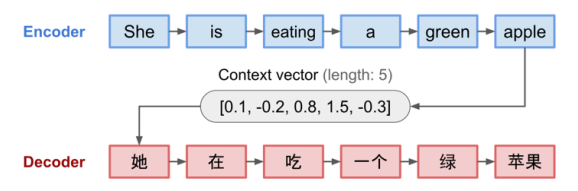
우선 Encoder가 RNN이라면 Context Vector는 RNN에서 Input Sequence의 정보를 요약한 벡터, 즉 Hidden State가 된다. 그런데 RNN에서 Hidden State는 크기가 고정되어 있다. 따라서 Input Sequence가 너무 짧아 Capacity의 낭비가 생기거나 혹은 반대로 Input Sequence가 너무 길어 Capacity가 부족해 제대로 압축하지 못하는 문제가 발생한다. 이러한 문제를 Bottleneck Problem이라고 부른다.
또한 RNN은 각각의 Step마다 Output Sequence를 하나씩 출력하는데, 이 과정은 Sequential하게 이루어진다. 이 때문에 Parallel Computation이 불가능하다. 이 문제는 학습 속도가 매우 느려지는 문제를 야기하는, 상당히 치명적인 단점이다. Seq2Seq의 Decoder를 RNN으로 구현하게 되면 RNN의 이 단점이 그대로 Seq2Seq에도 적용되게 된다.
Attention
Attention은 RNN 기반 Seq2Seq의 Bottleneck Problem을 해결하기 위해 등장한 개념이다.
사실 Attention은 원래 AI가 아니라 심리학에서 사용하는 용어로, 뇌에서 어떤 정보를 처리할 때 모든 정보를 한 번에 보는 것이 아니라, 내가 포커싱하는 정보 및 그와 연관된 다른 정보들만 가지고 선택적으로 정보를 처리한다는 개념을 뜻한다.
이는 뇌의 기전이므로 데이터의 형식에 구애받지 않고 공통적으로 적용된다.

사진을 보게 된다면 먼저 가운데부터 보고, 그 다음부터 주요 요소들로 눈동자가 빠르게 움직인다. 순간순간 집중하는 대상이 달라지며, 놀랍게도 “주요 요소”가 아닌 대상들로는 시선이 거의 가지 않는다.
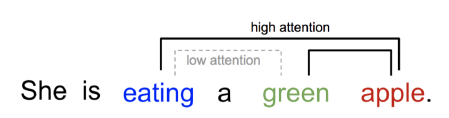
문장을 읽더라도 전체 문장을 보기보다는 중요한 요소 및 그들의 관계를 먼저 해석한다. 위의 텍스트의 경우 일반적으로 “eating”과 “apple”을, 그리고 “green”과 “apple”을 각각 연관지어서 해석한다.
이러한 Attention 개념을 머신러닝, 혹은 딥러닝에도 적용할 수 있다면 모델이 지금 처리하고 있는 정보와 관련도가 높은 다른 정보들을 파악하기에 용이하며, 또 그 정보들을 어떻게 묶어서 처리할지에 대한 것들을 알 수 있게 될 것이다.
Overview
Attention 개념을 모델에 적용하기 위해선 어떤 식으로 구현되어야 할까?
Attention의 핵심은 결국 지금 내가 보고 있는 정보와 과거에 있었던 정보 간의 관계를 파악해서, Sequential Data의 순서와 관계 없이 중요한 정보를 지금 봐야 하는 정보 앞에 불러오는 것이다. 즉, Attention Vector는 Context Vector와 Input Sequence의 각각의 원소들간의 관계를 표현해줘야 한다.
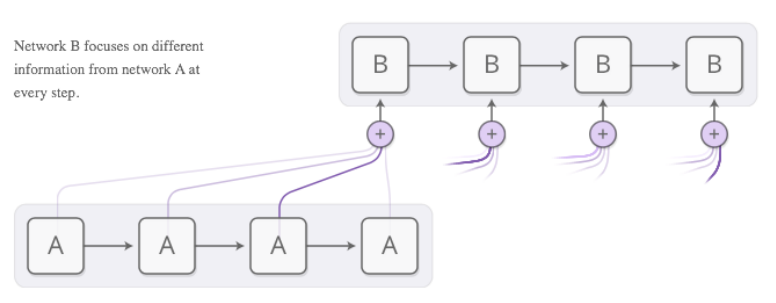
즉, 위의 그림과 같이 일종의 Shortcut이 형성되어서, 각각의 상황마다 모델이 필요한 정보를 더 찾아올 수 있게 해주는 것이다.
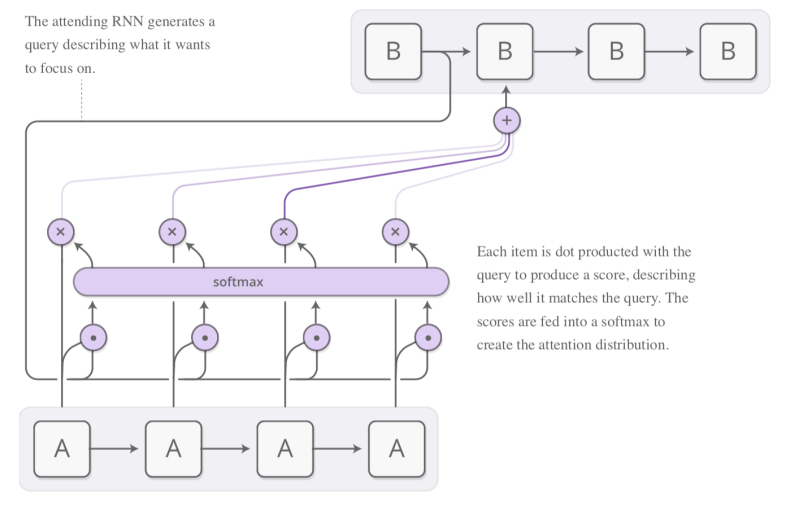
각각의 상황마다 각 정보의 필요도는 위의 그림과 같이 Softmax를 사용해서 계산한다. Softmax를 사용하는 이유는 당연히 각각의 Sequence마다의 유사한 정도를 우리가 잘 아는 $[0,1]$범위의 확률로 치환시킬 수 있기 때문이다.
이러한 방식의 Attention을 적용한 실제 사례는 다음과 같다.
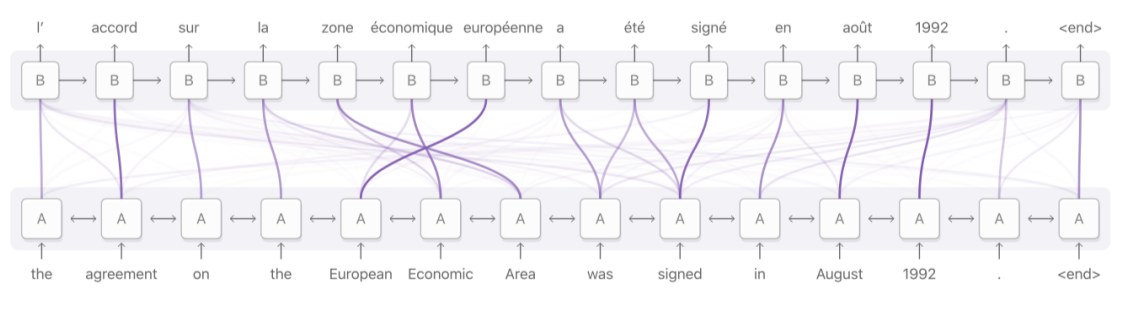
Seq2Seq에서 가장 흔하게 보이는 상황인 기계 번역이다. 이 경우는 Input Sequence가 완성된 문장으로 주어지기 때문에 Bidirectional RNN을 사용해서 Input Sequence가 양방향으로 주어진다.
각각 관련있는 단어끼리 강하게 연결이 된 것을 볼 수 있는데, 이러한 방식을 통해 RNN 기반 Seq2Seq의 치명적인 문제 중 하나인 마지막 Step의 Hidden State가 모든 부담을 떠안아야 하는 Bottleneck Problem을 해결할 수 있다.
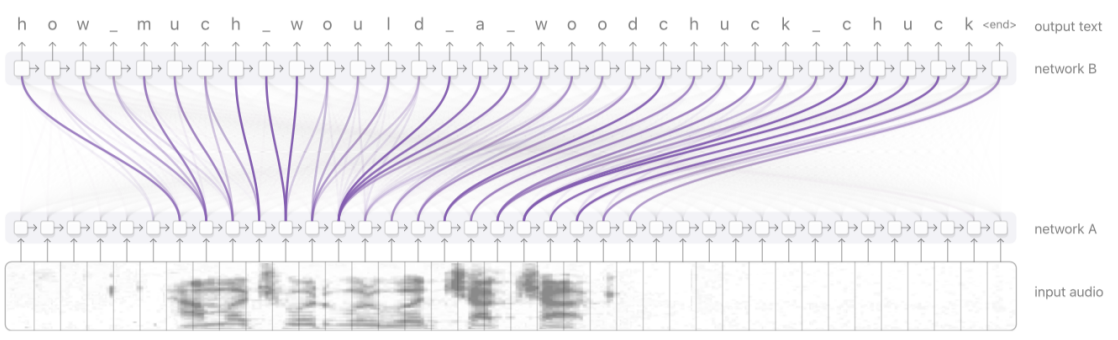
이번에는 음성 인식 상황이다. Input Sequence가 음성이라 뒤에서부터 보는 접근이 불가능하여 위의 기계번역과는 다르게 일반적인 단방향 RNN으로 되어 있다. 그 점 외에는 위의 기계 번역 문제와 동일한 원리이다.

이번엔 이미지를 설명하는, Image Captioning 작업이다. 위의 사진에서 이미지별로 특정 영역에 강조가 되어 있는데, 우리의 Seq2Seq 모델이 결과물로 문장을 생성하고 있을 때, 밑줄친 부분을 생성할 때 이미지에서 강조가 된 영역에 Attention Weight가 강하게 걸려있다는 의미이다.
물론 Weight가 크다고 해서 그걸 그대로 해석해도 되는지는 아직까지도 논쟁이 있긴 하지만, 여하튼 어느 정도 관련성은 보여준다는 것을 알 수 있다.
Mathematical Details
그럼 이러한 Attention이 수학적으로 어떻게 계산되는지 확인해보자.
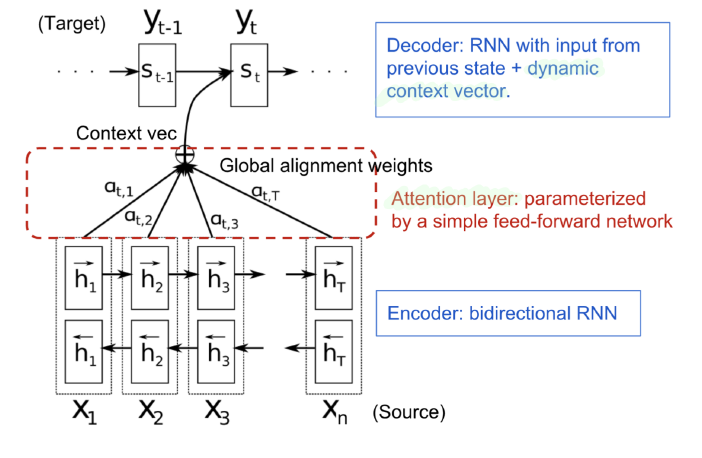
위 그림의 상황은 기계 번역을 다루고 있어 Input Sequence를 Bidirectional RNN으로 다루고 있다. 그리고 Encoder와 Decoder 사이에 Alignment가 존재하는데, 이것이 바로 위에서 다뤘던 Attention Layer이다.
이제 Input Sequence를 $x=[x_1,x_2,\ldots,x_n]$, $y=[y_1,y_2,\ldots,y_m]$이라고 하자. Bidirectional RNN을 쓰고 있는 상황이기 때문에, Encoder State $h_i$는 다음과 같이 2개의 Hidden State를 그냥 Concat한 결과가 된다.
\[h_i=[\overset{\scriptscriptstyle\rightharpoonup}{h_i}^T;\overset{\scriptscriptstyle\leftharpoonup}{h_i}^T]^T, i=1,2,\ldots,n\]그리고 Attention은 다음과 같은 Context Vector $c_t$로 계산된다.
\[c_t=\sum_{i=1}^{n}\alpha_{t,i}h_i\] \[\begin{aligned} \alpha_{t,i}&=align(y_t,x_i) \\ &= softmax(score(s_{t-1},h_i))=\dfrac{\exp(score(s_{t-1},h_i))}{\sum_{j=1}^{n}\exp(score(s_{t-1},h_j))} \end{aligned}\]즉 Context Vector의 $t$번째 원소 $c_t$는 Encoder State의 각 원소 $h_i$에 가중치 $\alpha_{t,i}$를 곱한 값을 더한 Weighted Sum이 된다. 이 $\alpha_{t,i}$는 $y_t$와 $x_i$가 얼마나 가까운지를 의미하는데, 이걸 편의상 $align(y_t,x_i)$이라는 함수로 계산한다고 하자.
align 함수를 계산하는 방식은 여러 가지가 있지만 일반적으로는 위의 수식과 같이 $s_{t-1}$, 즉 Decoder에서 이전 Step으로부터 넘어온 값과 $h_i$ 사이의 Attention Score를 계산하여, 이 값에 Softmax를 씌워서 구한다. 이 Score 함수 또한 각각의 Attention 설계마다 다르게 정할 수 있는 Design Choice로, 지금까지 다양한 종류가 제시되었다.
마지막으로 이렇게 계산한 Context Vector는 Decoder로 전달되는데, Seq2Seq에서는 간단한 MLP를 사용해서 다음과 같이 계산했었다.
\[s_t=f(s_{t-1},y_{t-1},c_t),t=1,2,\ldots,m\]그럼 이제 실제로 Attention Score를 어떻게 계산했는지 알아보기 위해 몇 가지 예시를 간단하게 알아보자.
Content-based Attention (Graves et al., 2014)
\[score(s_t,h_i)=cosine[s_t,h_i]=\dfrac{s_t\cdot h_i}{\lVert s_t \rVert\lVert h_i \rVert}\]최초에 제시된 Attention 중 하나로, 가장 간단하게 $s_t$와 $h_i$에 대한 코사인 유사도를 계산하여 이를 직접적으로 Attention Score로 사용한다. 이는 $s_t$와 $h_i$의 크기를 무시하고 순수하게 “내용이 얼마나 비슷한가”에 집중하는 형태라고 할 수 있다.
Additive Attention (Bahdanau et al., 2015)
\[score(s_t,h_i)=v_a^T\tanh(W_a[s_t;h_i])\]이름에서도 드러나듯이 $s_t$와 $h_i$를 결합한 후, 학습을 통해서 구한 가중치 행렬을 적용하여 계산한다. $v_a$는 가중치 행렬을 적용하여 계산한 벡터를 하나의 스칼라값으로 projection하기 위해 사용되며, 이 역시 학습을 통해서 구한다.
Location-based Attention (Luong et al., 2015)
\[\alpha_{t,i}=softmax(W_a s_t)\]여기는 특이하게 Score function을 정의하지 않았다. 오로지 $s_t$만을 보고, 즉 Decoder에서의 현재 Step만으로 Alignment를 결정하겠다는 뜻으로, Input Sequence의 내용과 무관하게 순서/위치 패턴이 중요한 경우를 고려했다.
General Attention (Luong et al., 2015)
\[score(s_t,h_i)=s_t^T W_a h_i\]여기서는 $W_a$를 중간에 끼워넣어서 $s_t$와 $h_i$의 차원이 서로 달라도 계산이 가능하도록 “일반화”시킨 버전이다.
Dot-Product Attention (Luong et al., 2015)
\[score(s_t,h_i)=s_t^T h_i\]위의 General Attention에서 가중치 행렬을 없애고 내적만 계산한 형태로, 학습할 파라미터의 개수가 줄어든 단순한 구조지만 이것이 의외로 괜찮은 성능을 보였었다.
Scaled Dot-Product Attention (Vaswani et al., 2017)
\[score(s_t,h_i)=\dfrac{s_t^T h_i}{\sqrt{n}}\]위의 Dot-Product Attention에서 차원을 $n$이라고 할 때 $\sqrt{n}$으로 나누는 과정만 추가되었다. 이는 차원이 커질수록 내적값이 매우 커지는 문제를 방지하기 위한 구조이다. 그리고 이 Scaled Dot-Product Attention이 바로 Transformer에서 사용하는 Attention이다.
Categories
위의 분류는 Score function을 기준으로 나눈 것이지만, 그보다 더 폭넓게 Attention의 종류를 나눠볼 수 있다. 크게 아래의 3가지 독립적인 기준축을 사용한다.
Self Attention vs Cross Attention
Self Attention은 Attention을 계산하는 범위가 자기 자신이다.

즉 위와 같이 하나의 Sequence 내에서 다른 원소 간의 관계를 계산하는 것이 Self Attention이다.
Cross Attention은 이와 반대로 서로 다른 Sequence 간의 관계를 계산한다. 즉, 앞에서 봤던 Seq2Seq 모델에서 사용하는 Attention은 전부 Cross Attention에 속한다.
Global Attention vs Local Attention
Global Attention은 참조 대상 Sequence의 전체 영역을 보고 Attention을 계산한다.
Local Attention은 이와 반대로 Sequence의 일부 Window만 보고 Attention을 계산한다. Seq2Seq 모델에서는 Global Attention을 사용했으며, 사실 지금까지도 Transformer를 포함한 대부분의 경우에 Global Attention을 사용한다.
Soft Attention vs Hard Attention
Soft Attention은 Deterministic Attention으로, Sequence의 모든 위치에 전부 가중치를 부여하여 Sequence의 각 원소마다 “부드럽게” 이어지도록 한다. 이 경우 Hard Attention에 비해 미분이 가능하고 모델이 상당히 부드럽게 학습이 가능해진다. 그러나 모든 위치에 대해 계산해야 하므로 계산량이 커진다는 단점이 있다.
Hard Attention은 이와 반대로 Stochastic Attention으로, Sequence 내에서의 위치를 Sampling해서 특정 한 부분만의 가중치만 사용한다. 이러면 Soft Attention과는 반대로 추론 시 필요한 계산량이 적어진다는 장점은 있으나, 샘플링 과정이 포함되기에 미분도 불가능하고 좀 더 복잡한 과정이 필요하다는 문제가 생긴다.
현재는 계산량이 커진다는 문제를 하드웨어의 발전으로 어떻게든 뭉개고, 계산의 간편함 및 미분가능하다는 장점 때문에 Soft Attention을 주로 사용한다. Seq2Seq 모델에서도 Soft Attention을 사용했다.
Case studies
그럼 이제 기존의 모델들에 Attention 개념을 적용해서 어떻게 개선했는지 몇 가지 실제 사례를 통해 알아보자.
Neural Image Caption Generation (Xu et el., 2015)
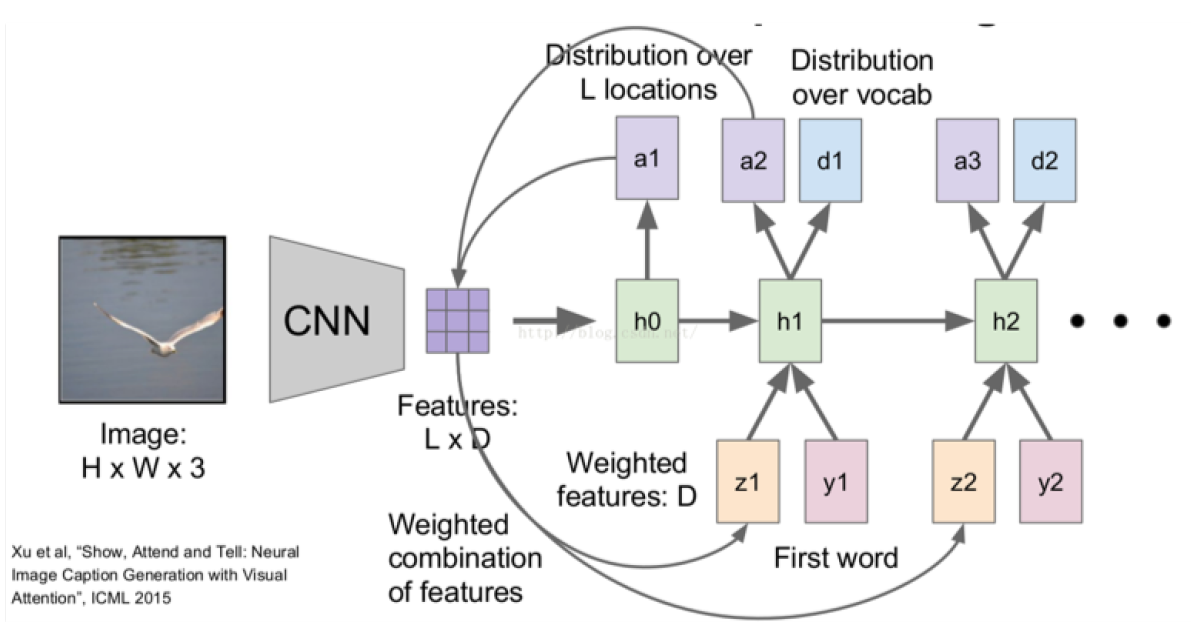
Image Captioning 문제를 푸는 모델이다. 여기서는 Vanilla RNN 대신 LSTM을 사용했는데, 기본적인 원리는 Seq2Seq와 동일하다. 다만 Input Sequence가 이미지이므로 CNN을 통해 Feature vector $A=\lbrace a_1,\ldots,a_L \rbrace, a_i\in\mathbb{R}^D$를 얻고, Seq2Seq의 방식으로 LSTM을 훈련시켜 Image Caption $y=\lbrace y_1,\ldots,y_C \rbrace, y_i\in\mathbb{R}^K$를 구한다.
이 논문에서 특이한 점은 Soft Attention과 Hard Attention을 모두 사용해서 비교했다는 것인데, 각각 다음과 같이 계산했다.
먼저 Soft Attention의 경우 다음과 같이 정의했다.
\[\mathbb{E}_{p(s_t|A)}[\hat{z}_t]=\sum_{i=1}^{L}\alpha_{t,i}a_i\]즉 모든 위치에 연속적인 가중치 $\alpha_{t,i}$를 부여해서 그 가중합을 계산한다. 그리고 이 논문에서는 Additive Attention을 사용해서 다음의 방식으로 Attention Score 및 Alignment를 구했다.
\[\begin{aligned} e_{t,i} &= f_{att}(a_i,h_{t-1}) \\ \alpha_{t,i} &= \dfrac{\exp(e_{t,i})}{\sum_{k=1}^{L}\exp(e_{t,k})} \end{aligned}\]다음으로 Hard Attention의 경우 다음과 같이 정의했다.
\[\begin{aligned} p(s_{t,i}=1|s_{j<t},A)&=\alpha_{t,i} \\ \hat{z}_t &= \sum_{i}s_{t,i}a_i \end{aligned}\]여기서 $s_{t,i}$는 0 혹은 1인 이진값으로, 즉 하나의 위치를 샘플링하는 과정이 포함되어 있다. 이러한 과정으로 인해 미분이 불가능하며 Backpropagation도 직접 사용할 수 없다. 이 문제를 해결하기 위해 이 논문에서는 다음의 과정을 통해 계산했다.
Variational Lower Bound를 Objective Function으로 사용
\[L_s=\sum_{s}p(s|A)\log p(y|s,A) \leq \log\sum_{s}p(s|A)p(y|s,A)=\log p(y|A)\]Monte-Carlo estimator로 Gradient를 근사
\[\dfrac{\partial L_s}{\partial W}=\sum_s p(s|A)\left[\dfrac{\partial\log p(y|s,A)}{\partial W}+\log p(y|s,A)\dfrac{\partial\log p(s|A)}{\partial W}\right]\]여기서 $\tilde{s}_t\sim Multinoulli_L(\lbrace \alpha_i \rbrace)$, 즉 $L$개의 위치 중 하나를 Multinoulli 분포에서 샘플링해서 구한다. 이 때 각 위치가 선택될 확률은 $\alpha_i$로, 즉 Soft Attention에서 계산한 그 가중치를 그대로 사용한다. 그러면 아래와 같이 근사시킬 수 있다.
\[\dfrac{\partial L_s}{\partial W}\approx\dfrac{1}{N}\sum_{n=1}^{N}\left[\dfrac{\partial\log p(y|\tilde{s}^{(n)},A)}{\partial W}+\log p(y|\tilde{s}^{(n)},A)\dfrac{\partial\log p(\tilde{s}^{(n)}|A)}{\partial W}\right]\]Moving Average Baseline으로 2에서 구한 Monte-Carlo estimator의 Gradient 분산을 감소
이러면 $k$번째 Mini-batch에 대해 아래와 같이 계산할 수 있다.
\[b_k=0.9\times b_{k-1}+0.1\times\log p(y|\tilde{s}_k,A)\]

위의 사진은 이러한 방식으로 구한 Soft Attention과 Hard Attention을 각각 시각화한 것이다. 즉, 각각의 단어를 생성할 때마다 이미지의 어느 부분을 보고 있는지를 표현한 것인데, Soft Attention은 이미지를 전체적으로 보고 있지만 Hard Attention은 특정 위치에 상당히 집중해서 보고 있다는 것을 알 수 있다.
그런데 문제는 Soft Attention이 딱히 성능이 나쁜 것이 아니라는 것이다. 그럼에도 불구하고 Hard Attention은 학습 절차가 너무 복잡해서 자연스럽게 Soft Attention을 주로 쓰게 되었다.
Visual Question & Answering
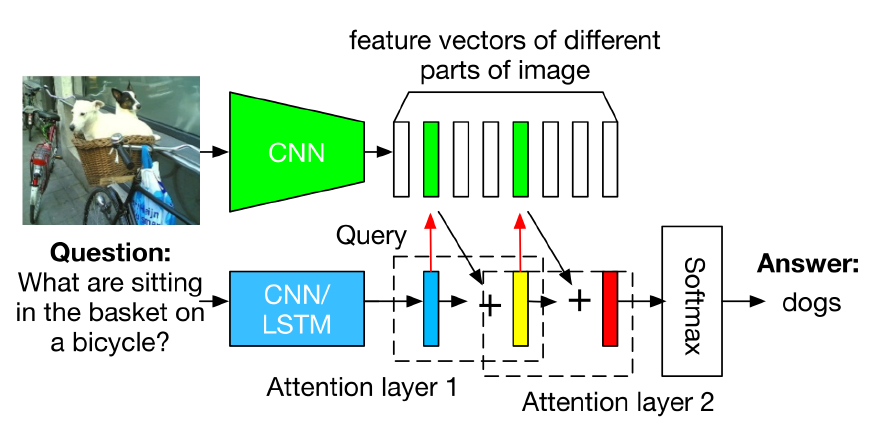
이번에는 Visual Question & Answering, 즉 사진과 질문이 주어졌을 때 그에 맞는 대답을 출력하는 모델이다. 이 때는 사진은 CNN을 통과시켜서 Feature Vector를 생성하고, 질문은 Seq2Seq를 통과시켜서 답변을 출력하게 한다. 다만 Attention Layer가 총 2개 필요한데, Feature Vector와 Input Sequence 간의 관계도 알아내야 하기 때문이다.
Neural Turing Machines (Graves et al., 2014)
NTM은 Attention 개념을 활용해 컴퓨터 시스템을 아예 바꾸려고 했던 시도이다.
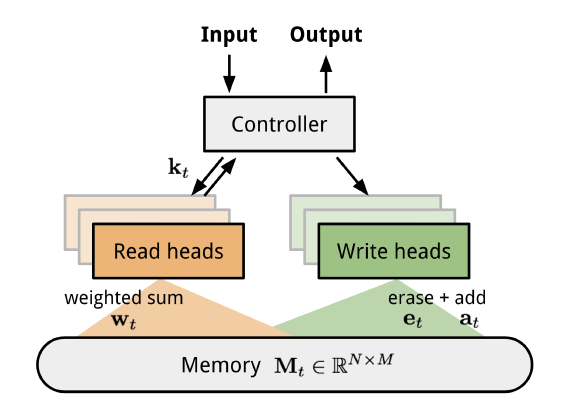
NTM에서는 Attention 개념을 활용해 데이터를 Neural Network 외부의 Memory에 두는 구조를 제안했으며, 대략적인 구조는 위와 같다. 여기서 Controller가 Input을 받아 외부의 Memory와 상호작용해서 Output을 출력하는 Neural Network이며, 여기서 Memory $M_t$는 $M_t\in\mathbb{R}^{N\times M}$로 구성되었다. 추가적으로 Controller가 Memory에 읽고 쓰는 작업을 지원하기 위해 Read/Write heads가 배치되었다.
이 과정에서 Controller가 처리해야 할 가장 핵심적인 문제는 Memory 중 “어디에” 읽고 써야 할지 결정하는 것이다. 일반적인 컴퓨터를 생각해보면 모든 작업마다 모든 Memory를 건드리지는 않으니 Hard Attention을 적용하는 것이 자연스러워 보인다. 그러나 이 논문에서는 모든 위치에 가중치를 부여하는 Soft Attention 방식을 적용했다.
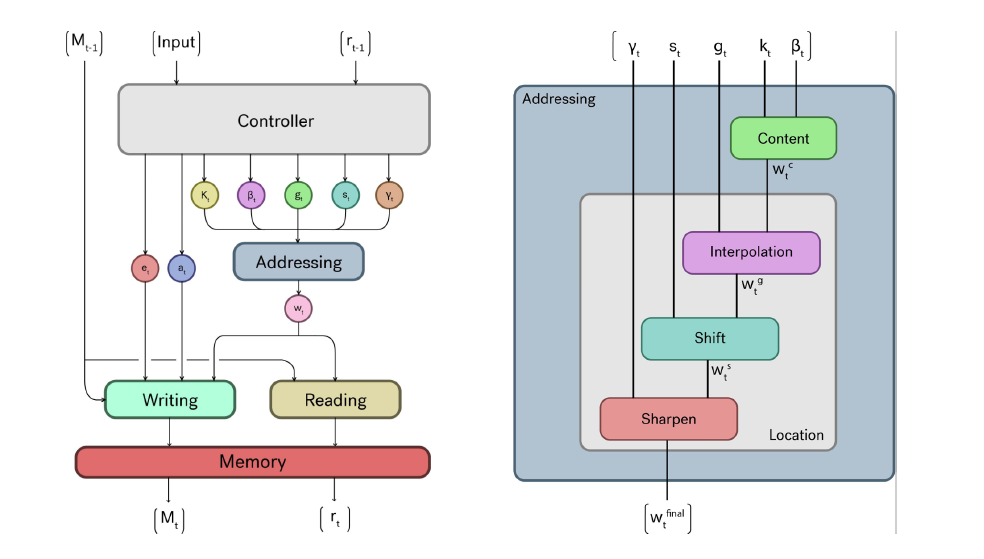
전체적인 구조는 위와 같다. Controller는 Addressing에 사용할 다양할 파라미터를 출력하고, Adressing 과정을 통해 나오는 최종 가중치 $w_t^{final}$을 구해 Reading/Writing 과정에 사용한다.
여기서 각 파라미터의 의미는 다음과 같다.
- $k_t$: Key Vector. Addressing 과정에서 Memory와의 유사도를 체크할 벡터
- $\beta_t$: Key Strength. Content Addressing의 정밀도를 조절하는 가중치
- $g_t$: Blending Factor. Content Addressing과 이전 Time-Step Addressing의 비율을 결정하는 가중치
- $s_t$: Shift Weighting. 이동 가능한 위치들에 대한 분포
- $\gamma_t$: Sharpening Exponent. Addressing 중 Sharpening 단계에서 사용
- $e_t$: Erase Vector. LSTM의 동작과 유사하게, 지울 메모리를 결정하는 벡터
- $a_t$: Add Vector. Memory에 추가할 데이터
이제 세부적인 단계들을 알아보자. 먼저 Reading은 다음과 같이 이루어진다.
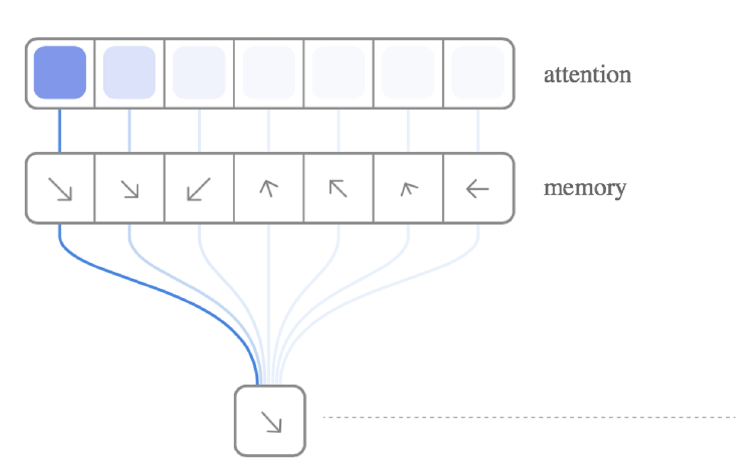
Reading의 결과는 Attention 가중치 $w_t(i)$로 Memory의 각 위치에 대한 가중합을 계산해서 구하며, 이 과정은 특별할 것 없이 일반적인 Soft Attention과 동일하다.
다음으로 Writing은 다음과 같이 이루어진다.
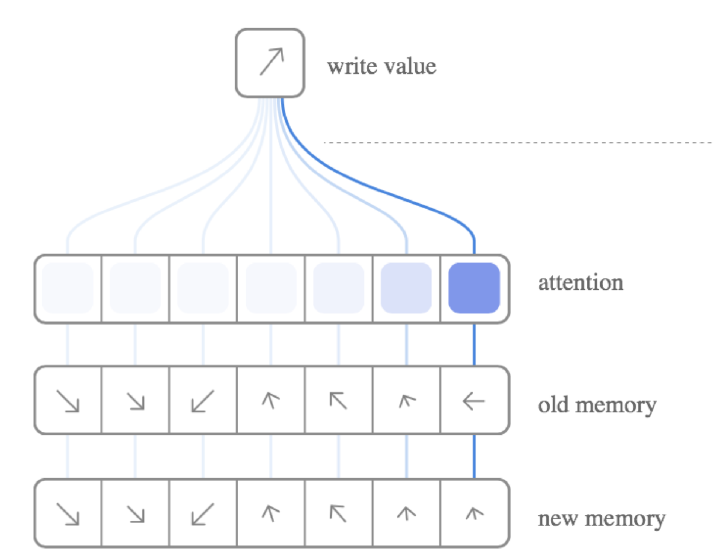
Read와 달리 두 단계 과정을 거치는데, $e_t$로 지울 내용을 먼저 결정하는 Erase 단계와 $a_t$를 실제로 추가하는 Add 단계이다. 이는 LSTM의 Forget Gate / Input Gate와 유사한 구조로 동작한다. 그리고 이 각각의 단계마다 전부 Attention 가중치 $w_t(i)$를 참조해 그 비율만큼 지우거나 더한다.
마지막으로 Addressing 과정에 대해 알아보자. 우선 Addressing은 아래 그림과 같이 총 4단계로 이루어진다.
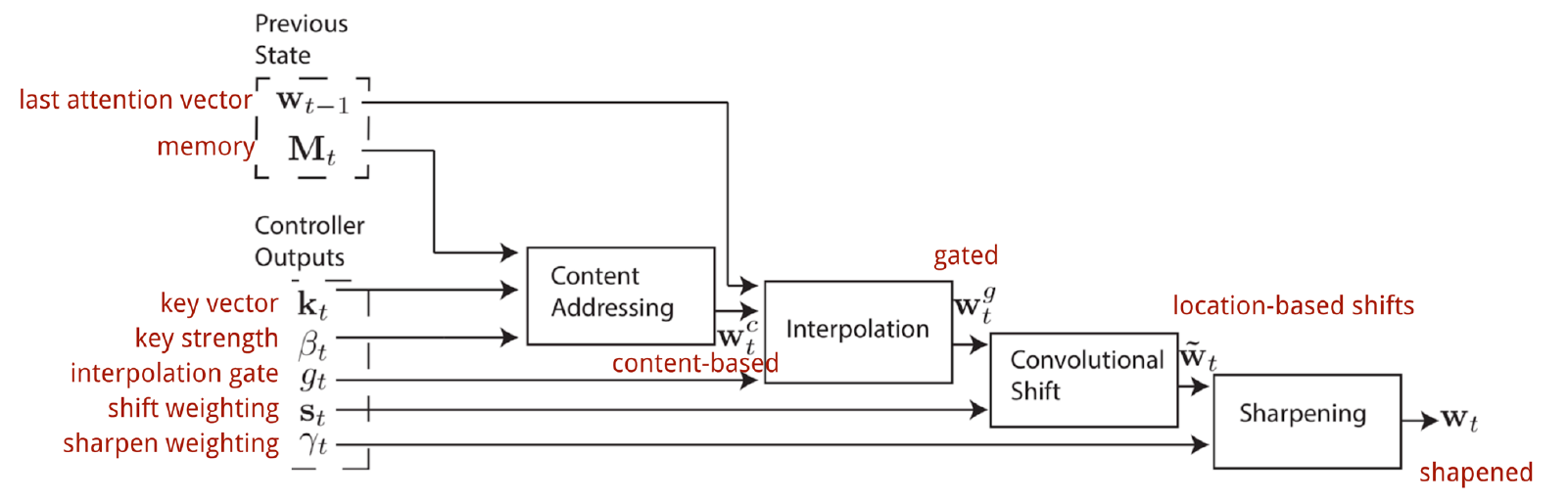
각각의 단계는 다음과 같이 동작한다.
Content-based Addressing
Addressing의 첫 단계는 내용이 비슷한 곳을 찾는 것이다. 이를 위해 Key Vector $k_t$와 Memory의 각 행을 비교해서 유사도를 체크한다.
$w_t^c=softmax(\beta_t\cdot\cos(k_t,M_t))$
그 과정은 위와 같은데, $\beta_t$가 클수록 더 유사한 위치에 집중하게 된다.
여담으로 앞에서 다루었던 Content-based Attention과 형태가 동일함을 알 수 있는데, 실제로 Content-based Attention이란 개념이 바로 여기서 처음으로 등장했다.
Interpolation
다음으로는 Content-based Addressing으로 찾은 이번 Time-Step의 Attention Vector와 이전 Time-step의 Attention Vector를 혼합한다.
\[w_t^g=g_t w_t^c+(1-g_t)w_{t-1}\]$g_t$가 각각 두 Attention Vector의 비율을 결정하는데, 1에 가까울수록 이번 Time-Step 위주로 계산한다.
Location-based Shift
다음 단계는 메모리 상의 순차적인 순회를 돕기 위한 Shift 단계이다.
\[\tilde{w}_t(i)=\sum_{j=1}^{N}w_t^g(j)s_t(i-j)\]분포 $s_t$로 Attention 위치를 앞뒤로 이동시키는데, 이 과정을 위의 식과 같이 Kernel $s_t$에 대한 1D Circular Convolution으로 구현한다. 그래서 이 과정을 Convolution Shift라고도 부른다. 만일 이 과정이 없다면 Controller는 Random Access만 가능해질 것이다.
Sharpening
마지막 단계는 Sharpening이라고 부르는데, 앞 단계에서 Convolution을 거치게 되면 Attention 분포가 주변으로 퍼지게 된다. 이를 다시 날카롭게 만드는 과정이다.
\[w_t(i)=\dfrac{\tilde{w}_t(i)^{\gamma_t}}{\sum_{j=1}^{N}\tilde{w}_t(j)^{\gamma_t}}\]여기서는 $\gamma_t$를 사용하는데, 이 값이 클수록 분포가 더 집중된 형태가 된다.
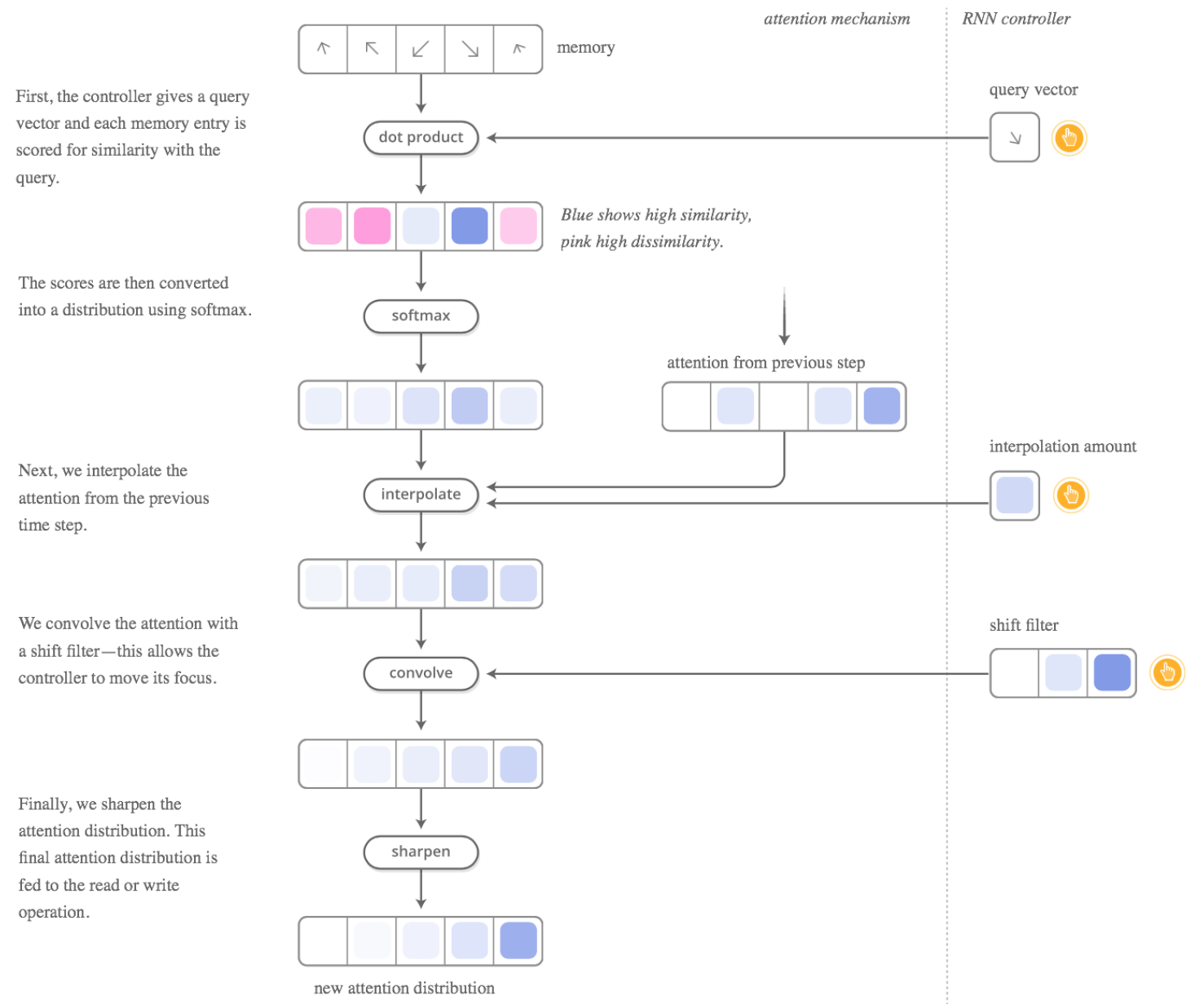
마지막으로 Addressing의 전체 과정을 정리하면 위의 그림과 같다.
이렇듯 Neural Turing Machine은 Attention 개념을 Memory 접근 메커니즘으로 활용한 모델이다. 단순히 입/출력만 가능하게 한 것이 아니라, 알고리즘을 학습할 수 있도록 설계되었다.
Transformer (Vaswani et al., NIPS, 2017)
여태까지 알아본 내용들은 전부 RNN 기반 모델들에서 Attention을 활용하는 법을 연구한 것들이다. 그러나 그러한 방식은 RNN의 궁극적인 한계인 Context Vector의 길이가 고정되어 있어서 모든 정보를 처리하는 데엔 한계가 있다는 점과 항상 Sequential하게 연산이 되어야만 해서 병렬 처리가 불가능하다는 문제를 해결해주진 못한다.
그래서 Attention is All You Need (Vaswani et al., NIPS, 2017)에서는 과감하게 RNN 기반 구조를 버리고 Attention을 새롭게 정의했으며, 추가로 Multi-Head Attention과 그 유명한 Transformer 아키텍쳐를 제안했다.
여담으로 Context Vector의 길이가 고정되어 있다는 문제는 위의 논문이 발표된 이후인 2022년도에 Elhage et al.에 의해 연구된 주제와도 관련이 있다. 2022년의 이 논문에서는 이상적인 모델은 Feature와 뉴런이 1:1로 대응하나 실제로는 더 적은 수의 뉴런이 많은 Feature를 동시에 표현하고 있음을 밝혔다. 이는 Feature Superposition, 혹은 Polysemanticity라는 이름으로 불리며 모델의 해석 가능성(Explainability)를 떨어뜨리는 원인이 된다고 한다.
Attention Operator
Transformer에서는 RNN 구조를 버렸기 때문에 기존 Attention에서 사용했던 값들을 새롭게 정의했다. 여기서는 Key, Query, Value라는 개념을 정립했는데, RNN 기반 Attention에서 Key와 Value는 Encoder의 Hidden State에, Query는 Decoder의 Hidden State에 대응된다.
즉, Bahdanau Attention을 비롯한 기존 Attention에서는 Key와 Value가 분리되지 않는 개념이었다. 이는 Encoder의 Hidden State와 Decoder의 Hidden State가 얼마나 일치하는지만 따지는 구조였기 때문이다. Transformer에서는 이들을 분리하여, “어디를 볼 지 결정하는 정보”인 Key와 “실제로 가져올 정보”인 Value를 독립적으로 학습시킬 수 있다.
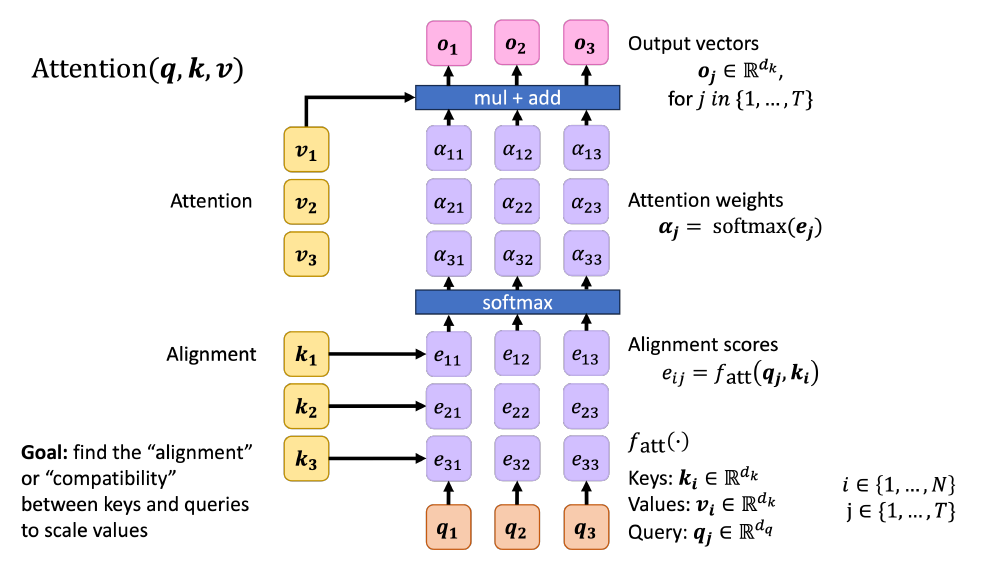
위의 분리된 Key, Query, Value를 바탕으로 한 $Attention(Q,K,V)$ 연산은 위 그림과 같은 구조로 이루어져 있다. 즉, 먼저 Key와 Query 간의 관계를 Alignment Score로 계산하는데, 여기서는 위에서도 언급되었듯이 Scaled-Dot Product Attention을 사용한다. 이렇게 나온 각각의 원소 $e_{ij}$를 같은 Query를 기준으로 하여 묶어서 Softmax를 취한다. 그렇게 나온 값을 Attention Weight로 삼아 Value와의 가중합을 취하는 연산이다.
\[Attention(Q,K,V)=softmax\left(\dfrac{QK^T}{\sqrt{d_k}}\right)V\]이 과정을 수식으로 요약하면 위와 같다.
또한 위의 로직에서 알 수 있듯이 Transformer Attention은 Soft Attention 및 Global Attention에 속한다. Self Attention인지 Cross Attention인지는 Key, Query, Value가 어느 Sequence에서 왔는지에 따라 다르다.
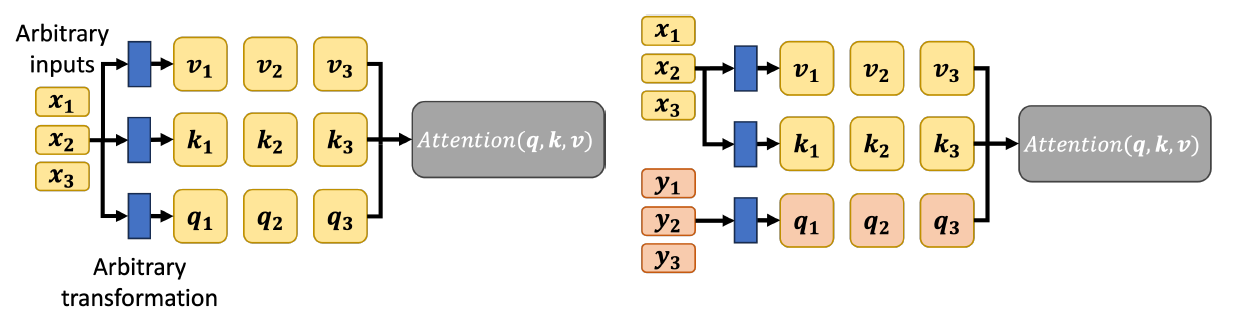
Key, Query, Value가 모두 같은 Sequence에서 왔으면 Self Attention, Query가 다른 Sequence에서 왔으면 Cross Attention이 된다.
Structure
그럼 이제 위에서 새롭게 정의한 Attention을 어떻게 사용했는지 2017년 당시의 Transformer 아키텍쳐를 파악해보자.
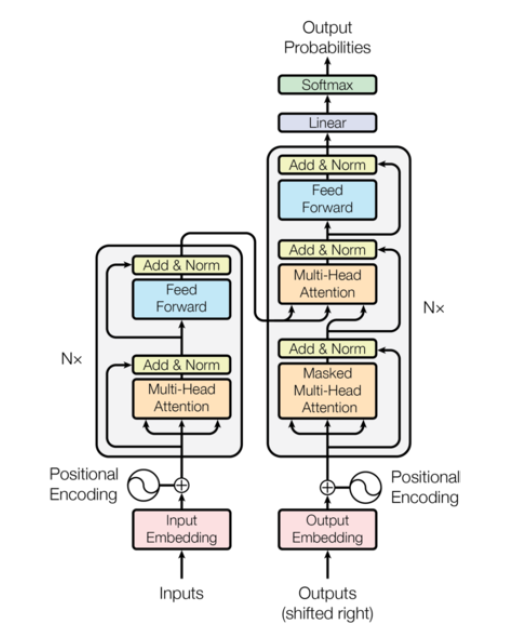
우선 이 당시의 Transformer는 Seq2Seq를 대체하기 위해 만들어진 모델이기 때문에 위와 같이 Encoder - Decoder 구조가 그대로 남아있다. 각각의 역할은 Seq2Seq에서와 동일하다. 즉, Encoder에서는 Input Sequence를 이용해서 Context Vector를 생성하고, Decoder는 이것을 이용해서 Output Sequence를 생성한다.
또한 위에서 알아본 Attention 연산은 Query, Key, Value가 필요한데, Transformer에서 우리에게 주어진 Input 값은 Sequence 뿐이다. 따라서 Input Sequence로부터 Query, Key, Value를 만들어서 Attention을 계산해야 하는데, Transformer에서는 다음과 같이 파라미터 $W^Q$, $W^K$, $W^V$를 사용하여 Input Sequence $X$에 대해 다음과 같이 계산한다.
\[Q=XW^Q, K=XW^K, V=XW^V\]또한 Multi-head Attention이 쓰였는데, 이는 CNN에서의 Channel과 유사한 개념이다. 즉, $W^Q$, $W^K$, $W^V$ 한 세트로는 Input Sequence를 한 관점에서밖에 보지 못하기 때문에 서로 다른 관점에서 Query, Key, Value 쌍을 생성한 후, 이들을 대상으로 각각 Attention을 계산한 것을 이어붙인다. Attention 연산의 결과를 head라고 부르기 때문에 이를 Multi-head Attention이라고 부른다.
그럼 이제 Encoder부터 확인하자.
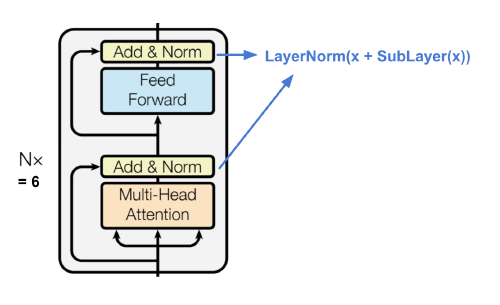
전체 구조도에서 왼쪽에 위치한 부분인데, Multi-head Attention, Layer Normalization, Feed Forward, Layer Normalization이 순서대로 이루어져 있다. 이렇게 이루어진 한 단위를 Transformer Encoder Block이라고 하며, 실제 Transformer에서는 이 Encoder Block을 여러 번 반복 배치한다.
Multi-head Attention을 잘 보면 Input이 3개로 나뉘어져 있는 것을 알 수 있는데, 이것이 바로 Key, Value, Query를 의미한다. 또한 Encoder Block에서는 하나의 Input Seqeunce에서 Key, Value, Query가 모두 파생된 것을 알 수 있는데, 이는 Self Attention을 의미한다.
Multi-head Attention 다음의 Feed Forward Layer는 Multi-head Attention으로부터 얻어진 정보를 잘 뒤섞어서 Complexity를 높이기 위함이다. 여기서의 Activation Function은 다음과 같이 일반적으로 ReLU를 사용한다.
\[FFN(x)=ReLU(xW_1+b_1)W_2+b_2\]또한 ResNet에서 등장한 Residual Connection이 여기서도 사용된 것을 알 수 있는데, 이는 필연적으로 네트워크의 깊이가 깊어질 수밖에 없는 Transformer의 특성상 Gradient가 안정적으로 흐르기 위한 장치이다. 비단 Transformer 뿐만이 아니라 어느 정도 깊은 네트워크는 대부분 이러한 구조를 채택한다.
다음으로 Decoder는 다음과 같이 이루어졌다.
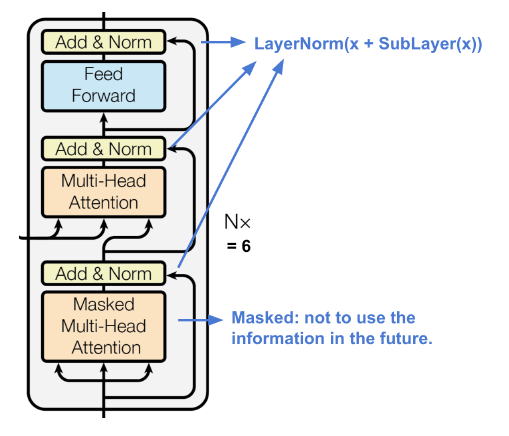
Encoder에 비해서는 조금 복잡한 구조인데, 먼저 Decoder라고 해서 Context Vector 외에 아무 입력값도 없는 것이 아니라는 것을 알아야 한다. RNN이 Sequence를 생성할 때를 생각해보면, 이전 Step의 출력값이 그대로 다음 Step의 입력값으로 들어가게 된다. 이렇게 해야 스스로 Sequence를 만들어내는 Auto Regressive Model이 되기 때문인데, 제 아무리 Transformer가 RNN 구조를 버렸다고 하더라도 이러한 원칙은 지켜져야 한다. 즉, Decoder는 Encoder로부터 생성된 Context Vector 외에도 이전 Step까지의 Decoder가 스스로 생성한 Output Sequence를 입력받는다.
이 Output Sequence를 가지고 먼저 Multi-head Attention을 계산하는데, 이 역시 Self Attention이다. 그런데 Transformer는 Self Attention으로 각 원소 간의 관계를 파악하기 때문에 RNN의 Sequential 제약에서 벗어나 병렬적인 학습이 가능한데, 실제로 추론하는 과정 중에는 Decoder가 여태까지 생성했던 Output Sequence만 알고 있어야 하기 때문에 학습할 때도 이 과정을 모방하여 미래의 Time-Step에 해당하는 원소를 Masking하여 가려놓는다. 그래서 이 부분을 Masked Multi-head Attention이라고 부른다.
이 과정을 거쳐서 얻은 Vector와 Encoder로부터 얻은 Context Vector를 가지고 다시 한번 Multi-head Attention을 계산하는데, 이 경우 Key와 Value는 Context Vector로부터, Query는 Decoder의 앞 단계로부터 얻었으므로 이는 Cross Attention이다. 그 후에는 Encoder와 동일하게 Feed Forward Layer를 사용하여 Complexity를 높이면 Decoder Block이 종료된다. 실제 Transformer는 이 Decoder Block도 여러 번 반복 배치한다.
여기서도 마찬가지로 각각의 Attention, Feed Forward Layer 뒤에 Layer Normalization을 두고, Residual Connection을 사용했다. 이유는 Encoder Block과 동일하다.
여기까지 보면 다 된 것 같지만 중요한 요소가 하나 빠져있다. Transformer는 기본적으로 Sequence를 입력받고 Sequence를 출력한다. 그리고 Sequence는 순서가 중요한 데이터인데, Attention은 Sequence의 각 요소들 간의 관계만 정의할 뿐 순서에 대해서는 어떠한 정보도 제공하지 않는다. 그래서 Input Sequence를 생성할 때 순서에 대한 정보를 같이 넣어줘야 하는데, 이를 Positional Encoding이라고 한다.
이를 어떻게 넣느냐에 대한 연구도 많이 존재하지만, Attention is All You Need에서는 아래와 같이 간단하게 $\sin$과 $\cos$를 사용했다.
\[\begin{aligned} PE_{(pos,2i)}&=\sin\left(\dfrac{pos}{10000^{2i/d_{model}}}\right) \\ PE_{(pos,2i+1)}&=\cos\left(\dfrac{pos}{10000^{2i/d_{model}}}\right) \end{aligned}\]물론 Positional Encoding은 순서가 중요한 데이터에서 순서를 입력해주기 위한 장치이므로, 만일 Set과 같이 순서가 중요하지 않은 데이터를 다룬다면 이 과정은 아예 생략해도 무방하다.
여담으로 최초의 Transformer는 Positional Encoding을 위와 같은 방식으로 계산했기 때문에 Input Sequence의 차원이 너무 커지면 계산이 잘 안되는 문제가 있다. 일반적으로 Sequence의 길이가 512를 초과하면 이 Positional Encoding으로 제대로 위치 정보를 주입하기 어려워서 최초의 Transformer는 Sequence의 최대 길이를 512로 제한했다. 물론 Sequence 길이를 $N$이라고 하면 Attention 연산의 시간복잡도는 $O(N^2)$이라는 문제도 있어 어차피 당시 기준으로 512를 초과하는 길이에 대해서는 Transformer가 제대로 동작하기 어렵기도 했다.
Large Language Models
Transformer 아키텍쳐가 인정을 받은 후, 이 구조를 어떻게 활용할 수 있을지에 대한 연구도 많이 이루어졌다. 그리고 원래 Transformer는 번역과 같은 Sequence to Sequence 문제를 풀기 위해 고안된 모델이었다는 점에 착안하여, 둘 모두가 필요하지는 않은 작업에서 Encoder와 Decoder 중 일부만 사용하려는 시도 또한 이루어졌었다.
BERT (Devlin et al., ACL, 2019)
Bidirectional Encoder Representations from Transformers, 즉 BERT는 Google에서 사용한 전략으로, Transformer의 Encoder 구조만 가져온 것이다. 이들은 데이터를 다루는 데에 있어서 가장 중요한 것은 Encoding, 즉 정보를 어떻게 표현하느냐가 가장 중요하며 그 표현이 잘 될수만 있다면 어떠한 Task에서도 사용할 수 있을 것이라는 아이디어에 초점을 두었다.
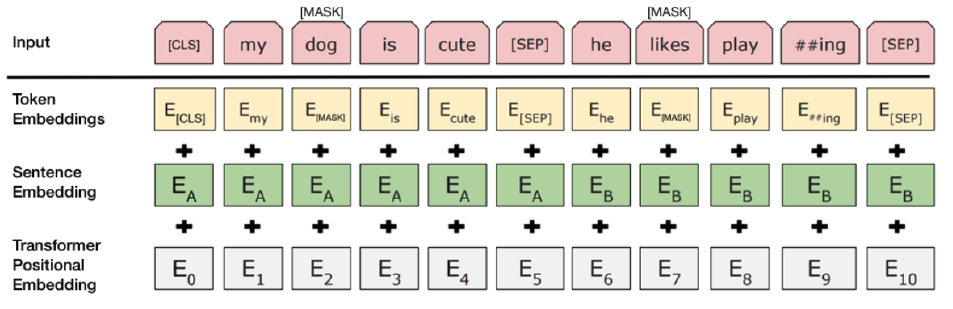
BERT는 Input Sequence를 위 그림과 같이 구성했다. 즉, 원래 Transformer에 존재하던 Positional Embedding에 더해서 문장의 구분을 알려주는 Sentence Embedding, 그리고 각 단어에 대응되는 토큰이 포함된 Token Embedding을 합쳤다. 그런데 Input에 일반적인 자연어 문장 외에도 특수한 토큰들이 포함되어 있다는 것을 알 수 있는데, 우선 [SEP]는 그냥 문장의 경계를 알려주는 토큰이다.
중요한 것은 맨 앞에 포함된 [CLS] 토큰인데, 이 자리에 BERT를 통과하며 얻은 정보가 압축되어 저장된다. 이는 BERT가 결국 Self Attention으로 계산되기 때문이다. 즉, BERT를 통과하면서 Input Sequence의 다른 모든 부분과 Attention 연산을 수행하기 때문에 자연스럽게 Input Sequence 내의 다른 모든 Token의 정보를 다 참조할 수 있는 위치에 있다. 이 때문에 BERT에서도 이 정보를 바탕으로 최종적으로 출력값을 내도록 학습하며 이로 인해 [CLS] 토큰 내에 필요한 모든 정보가 다 집약되도록 유도된다.
그렇다면 BERT는 Decoder 없이 어떻게 학습을 했을까? 여기에 사용된 방법은 크게 2가지이다. 첫번째는 Masked LM이라고 불리는 방식으로, Input Sequence를 넣을 때 정해진 비율만큼 단어를 아예 가려버리고 Masking을 시킨다. 그리고 지워진 곳에 들어갈 적절한 단어를 찾는 식의 학습이다.
두 번째 방식은 Next Sentence Prediction이라고 불리며, 2개의 문장을 이어놓고 2번째 문장이 첫번째 문장에 이어서 나오는 것이 적절한지를 학습시킨다.
GPT
Generative Pretrained Transformer, 즉 GPT는 OpenAI에서 사용한 전략으로, BERT와는 반대로 Transformer의 Decoder 구조만 가져온 것이다. 여기서는 혼자서 데이터를 생성하는, 즉 Auto Regressive Model에 초점을 맞춰서 같은 Sequence 내에서 앞부분만 보고 뒷부분을 예측하는 문제를 해결하도록 학습시켰다.
이 과정에서 원래 Transformer의 Decoder Block에 있던 Masked Multi-head Attention은 그대로 두고, Encoder가 생성한 Context Vector를 받아서 Cross Attention을 계산하는 부분을 통째로 제거한 구조를 사용했다. 그리고 Next Sequence를 생성하는 문제이니만큼 BERT와 다르게 단방향으로만 이루어져 있다.
Transformers in Computer Vision
또한 Transformer 아키텍쳐를 자연어 문장이 아닌 다른 곳에 사용해보려는 시도도 이루어졌는데, 그 중 대표적인 것이 이미지이다.

가장 처음 시도된 방법은 Image GPT (Chen et al., 2020)인데, GPT가 텍스트에서 성공했으니 이미지도 동일하게 취급하면 되지 않을까? 하는 발상에서 출발했다. 자연어 문장은 Token 단위로 쪼갤 수 있듯이 이미지도 픽셀이라는 최소 단위로 쪼개서 Transformer에 넣어 GPT처럼 다음 픽셀을 예측하는 방식으로 학습시켰다.
그러나 이 방식에는 치명적인 문제점이 있어 결국은 사장되었다. 우선 자연어의 Token과 다르게 각 픽셀은 그 자체로는 아무 의미가 없다.
또한 픽셀 단위로 쪼갠다는 점에서 Sequence가 너무 길어지는 문제가 존재한다. 256x256 이미지만 해도 65536 픽셀인데, 이는 Attention 연산의 복잡도로 감당할 수 없는 차원이다. 이 문제로 인해 실험에서는 32x32로 다운샘플링했는데, 이러면 또 이미지의 품질이 너무 낮아져서 학습이 잘 안된다는 문제가 존재한다.
마지막으로 제 아무리 Positional Embedding을 추가했다고 하더라도 Transformer는 이미지의 Inductive bias를 구조적으로 반영할 수는 없는 구조라는 점이다. 이는 곧 이미지의 특성을 학습으로만 찾아야 하는데 이러면 픽셀 단위로 Input Sequence를 구성해 차원이 너무 커진다는 문제가 다시 발목을 잡는다.
![]()
Image GPT의 실패 이후 새롭게 제시된 구조가 Vision Transformer, 즉 ViT이다. ViT에서는 픽셀 단위로 Input Sequence를 구성했다는 점을 핵심 문제로 지적하여, 특정 크기(원 논문에서는 16x16)로 이루어진 Patch 단위로 Input Sequence를 구성했다.
Patch 단위로 Input Sequence를 생성하게 되면 각각의 Patch별로 어느 정도의 의미가 생기게 되고, Input Sequence의 차원도 상당히 낮아지게 된다. 또한 Inductive bias 문제 자체를 해결하진 못했으나, Input Sequence의 차원이 크게 낮아짐에 따라 더 많은 데이터로 극복 가능한 수준으로 내려왔다. 그리고 오히려 Inductive bias 없이 학습하기 때문에 데이터가 충분하다면 오히려 더 유연하게 학습할 수 있다는 장점이 추가로 생겼다.
이렇듯 Input Sequence의 단위만 수정했을 뿐인데 놀랍게도 Image GPT의 문제가 대부분 해결되어 Transformer가 이미지에도 적용될 수 있음을 보였다고 할 수 있다.