Advanced Machine Learning 13 - Generative Models & Diffusion Models
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Advanced Machine Learning 과목의 수업을 다룬다.
Unsupervised Learning
Generative Model은 여태까지 다뤘던 Supervised Learning이 아니라, Unsupervised Learning에 속한다. Unsupervised Learning은 데이터에 Label이 존재하지 않으며, 이 데이터들이 Feature들 간에 어떤 관계들을 잘 가지고 있을 것이라는 전제 하에 데이터 안에 존재하는 고유의 Hidden Structure를 배우고자 하는 목적을 가진다.
예전에는 이러한 Unsupervised Learning으로 Clustering, Dimensionality Reduction, Feature Learning, Density Estimation 등을 연구했으나, 최근에는 Label이 존재하지 않는 샘플들로부터 Supervised Learning을 발전시키거나 Generative Model 등으로 활용하고 있다.
데이터셋에 Label이 존재하지 않기 때문에 Unconditional distribution $p_{\theta}(x)$를 모델링해야 하며, 따라서 Objective function은 $\underset{\theta}{\max}\sum\limits_{x\sim D}\log p_{\theta}(x)$가 된다. 이는 데이터셋에 Label이 존재하여 Conditional distribution $p_{\theta}(y \vert x)$를 모델링하고, 따라서 Objective function이 $\underset{\theta}{\max}\sum\limits_{(x,y)\sim D}\log p_{\theta}(y \vert x)$인 Supervised Learning과 대비된다.
즉, 이러한 Conditional / Unconditional의 차이만 있을 뿐 여태까지 배웠던 Likelihood 개념 자체는 동일하게 적용됨을 알 수 있다.
Generative Models
Generative Model 또한 Unsupervised Learning이므로 위에서 본 차이점이 그대로 적용된다.
우선 기존의 Discriminative Model부터 살펴보자.
위와 같이 Label이 개와 고양이만 존재하는 데이터셋이라면, 이 모델의 Output은 “개일 확률”, “고양이일 확률”의 2가지로만 나온다.
이는 심지어 개도 고양이도 아닌 이미지를 Input으로 넣어도 동일하다. 즉, 이 모델의 세계에선 모든 이미지가 개와 고양이로만 구분된다. 이것이 Conditional distribution의 의미이다.
Generative Model의 경우엔 다르게 표현된다.
이 경우엔 Label이 존재하지 않으며, 따라서 주어진 데이터셋에서 많이 등장한 비율만 가지고 확률을 추정하게 된다. 여기에는 어떠한 Condition도 존재하지 않기 때문에, 개와 고양이로만 이루어진 데이터셋을 제공했더라도 “이미지”의 범주에 있는 이상 전혀 다른 이미지여도 확률이 아예 0이 되진 않는다. 이것이 Unconditional distribution의 의미이다.
물론 등장 확률이 매우 적은 것을 근거로 하여 Unreasonable input을 걸러낼 수 있으며, 실제로 이런 용도로도 사용되기도 한다.
그럼 이제 Generative Model에서의 Maximum Likelihood Estimation에 대해 조금 더 알아보자.
$p(x)=f_W(x)$라고 하고, 데이터셋 $D=\lbrace x^{(1)},x^{(2)},\ldots,x^{(N)}\rbrace$이 주어졌다고 하자. 이 경우 이상적으로는 다음과 같이 MLE를 할 수 있다.
\[\begin{aligned} W^{\ast}&=\arg\max_{W}\prod_{i}p(x^{(i)}) \\ &=\arg\max_{W}\sum_{i}\log p(x^{(i)}) \\ &=\arg\max_{W}\sum_{i}\log f_W(x) \end{aligned}\]여기까지는 크게 다를게 없으나, 이러한 Unconditional distribution을 익히기 위해서 필요한 차원의 크기가 매우 크다는 것이 문제다. Classification이나 Regression 문제와 같이 Label을 만들 수가 없으니 저 데이터를 있는 그대로 배워야 하는데, 32x32 크기의 흑백 이미지라고 쳐도 $2^{32\times32}$ 차원이 된다.
그래서 MLE 추정을 그대로 학습에 사용하는 것은 사실상 불가능에 가까운 일이 된다. 그렇기 때문에 직접 모델링하지 않고 Likelihood를 최대화시킬 다양한 방법론이 고안되었는데, 그것이 바로 VAE, GAN, Diffusion, Flow matching 등의 각각의 Generative Model이다.
Autoregressive Model 또한 Generative Model 중 하나인데, 여기서는 입력 데이터 $x=(x_1,x_2,\ldots,x_T)$의 Sequence로 가정한다. 그리고 앞에서 나온 Sequence들로 바로 다음 단어를 예측하는 형태로 모델링을 한다.
\[\begin{aligned} p(x)&=p(x_1)p(x_2\vert x_1)p(x_3\vert x_2,x_1)\cdots p(x_T\vert x_{T-1},x_{T-2}\ldots,x_1) \\ &=\prod_{t=1}^{T}p(x_t\vert x_{t-1}x_{t-2},\ldots,x_1) \end{aligned}\]즉 $p(x)$는 위와 같은 형태로 계산된다. 이러한 형태의 모델은 RNN이나 Transformer Decoder에서 보던 형태인데, 이들도 사실 Generative Model의 일종이다. 이 경우에는 우리가 기존에 활용했었던 MLE 추정을 그대로 사용할 수 있다.
사실 PixelRNN, PixelCNN 등 이러한 Autoregressive Model을 이미지에도 사용하려는 시도가 있었는데, 결국 위에서도 나온 Dimension 문제가 커서 결국 이러한 방식으로는 이미지를 제대로 학습할 수 없었다. 대신에 Language에서는 이 방법이 여전히 유효해서, LLM 등에서는 아직 이러한 방식으로 모델링을 한다.
Histogram-based Generation
Autoregressive Model을 제외하고 가장 간단한 Generative Model은 Histogram-based Model이다. 이는 주어진 데이터셋 $\lbrace x^{(1)},x^{(2)},\ldots,x^{(N)}\rbrace$가 모두 분포 $p_{data}$로부터 왔을 때, 그 분포 $p_{data}$를 추정하는 모델로, 각각의 샘플들은 모두 1차원이며 그 값은 모두 $\lbrace 1,2,\ldots,k\rbrace$의 원소라는 전제가 필요하다.
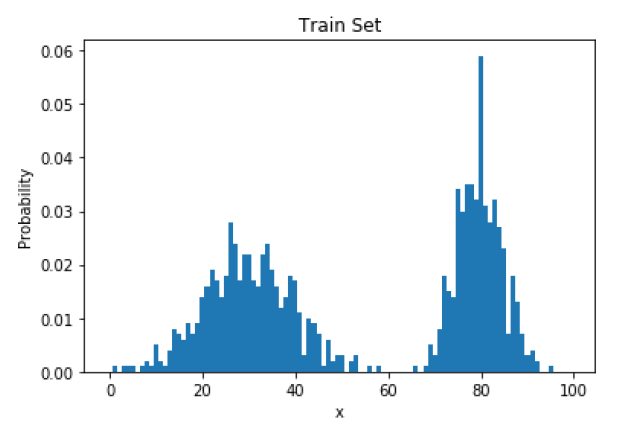
이러한 가정 하에, 각 샘플들의 빈도를 세어서 위와 같은 Histogram을 그릴 수 있다. 이러면 각각의 가능한 값 $i$가 등장할 확률 $p_i$를 알고 있으므로 이 값을 그대로 리턴하면 추론이고, 이를 기반으로 CDF를 구성하여 Uniform distribution을 통해 샘플링도 수월하게 가능하다.
이러한 형식의 모델링은 아주 간단하고 제약도 많이 붙었지만 어쨌든 원본 데이터셋의 분포를 따르는 분포를 추정하고, 그 분포로부터 데이터를 생성할 수 있으니 Generative Model에 속한다. 그러나 이 모델을 실제로 쓰기엔 치명적인 약점이 2개가 있다.
첫번째 약점은 당연히 높은 차원을 감당할 수 없다는 것이다. 결국 여기에서도 32x32 크기의 흑백 이미지, 즉 $2^{32\times 32}$의 차원조차 제대로 감당하기 어렵다는 문제가 있다. 두번째 약점은 Generalization이 어렵다는 것인데, train set의 분포를 모방하기 때문에 train set에서 한번도 등장하지 않은 값은 확률이 무조건 0이 된다. 즉, Overfitting 문제에 너무나도 취약하다.
Likelihood-based Generative Models
이제 현대적인 접근법을 알아보자. Histogram-based Model에서 알 수 있듯이, 분포를 그대로 계산하려고 하는 시도는 Overfitting에 너무 취약하다는 문제가 있다. 이로 인해 분포를 정확히 추정하려고 하는 시도보다는, 계산할 수 있는 형태의 Parametrized distribution 형태로 근사시키고 이 분포를 계산할 수 있는 함수를 모델링 하는 것에 초점을 맞춘다.
이제 이러한 가정에 맞춰서, 데이터셋 $\lbrace x^{(1)},x^{(2)},\ldots,x^{(N)}\rbrace$가 전부 분포 $p_{data}$에서 왔으며, 이 분포 $p_{data}$를 정확히 알 수 있는 방법이 없기 때문에 대신에 계산 가능한 분포 $p_{\theta}$로 근사한다고 하자.
\[\arg\min_{\theta}l(x^{(1)},x^{(2)},\ldots,x^{(N)};\theta)=\dfrac{1}{n}\sum_{i=1}^{n}-\log p_{\theta}(x^{(i)})\]그리고 우리가 풀어야 하는 문제는 위와 같다. 그런데 여기서 PDF의 Negative Log는 다음과 같은 Kullback-Leibler(KL) Divergence와 동일한 의미를 가짐을 알 수 있다.
\[\begin{aligned} KL(\hat{p}_{data}\Vert p_{\theta})&=\sum_{x\in\mathbb{X}}\hat{p}_{data}\log\left(\dfrac{\hat{p}_{data}(x)}{p_{\theta}(x)}\right) \\ &=\mathbb{E}_{x\sim \hat{p}_{data}}\left[-\log p_{\theta}(x)\right]-H(\hat{p}_{data}) \end{aligned}\] \[\hat{p}_{data}(x)=\dfrac{1}{n}\sum_{i=1}^{n}\mathbb{I}\left[x=x^{(i)}\right]\]그래서 MLE 추정으로 유도한 Objective function과 두 분포 $\hat{p_{data}}$와 $p_{\theta}$의 KL Divergence가 사실상 동일한 값을 가리키고 있음을 알 수 있다. 그 후에는 다른 모델과 동일하게 Stochastic Gradient Descent를 통해 학습을 하게 된다.
Diffusion Models
Diffusion Model은 위에서 알아본 Likelihood-based Generative Model의 일종으로, 그 중에서도 비교적 최근에 제안된 모델 중 하나이다. Diffusion은 원래 고밀도/고농도에서 저밀도/저농도로 물질이 퍼져나가는 확산 현상을 일컫는 물리/화학 용어이다.
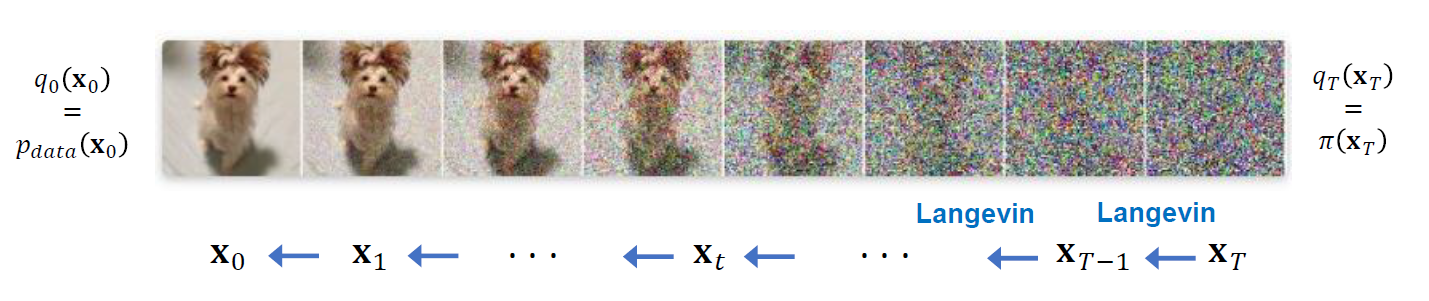
이 이름에 걸맞게 Diffusion Model 또한 원래의 이미지에서 Gaussian Noise를 퍼뜨린다. 즉, 원래의 이미지의 분포 $p_{data}$에서 Gaussian distribution까지 노이즈를 덧씌우는 과정을 여러 단계로 나누어서 수행하는 것이다. 그리고 이미지를 생성할 때는 위와는 정 반대로 Gaussian distribution에서 $p_{data}$까지 여러 단계로 나누어서 수행한다.
이렇게 각 단계로 잘게 쪼개서, 각각의 모델은 딱 1개 Step에 해당하는 정도로만 Noise로부터 이미지를 복원하는 작업을 학습한다. 이러한 과정을 반복 수행시키는 것이 Diffusion Model의 초기 아이디어이다.
사실 이런 식으로 Gaussian을 잠재공간을 Gaussian distribution으로 가정하는 Generative Model은 이미 존재한다. Variational Autoencoder, 즉 VAE라고 불리는 모델이 그것인데, VAE는 이 각각의 과정을 사람이 직접 하기 어려우니 Neural Network를 동원하여 “너가 배워”라고 떠넘기는 형태라면, Diffusion은 그 어려운 일을 어떻게든 여러 Step으로 쪼개서 모델 하나가 이 작업을 통째로 짊어지게 하는 일을 방지하는 형태라고 볼 수 있다.
Iterative Noising Process
그럼 이제 Gaussian Noise를 추가하는 과정을 알아보자. 이 과정을 Iterative Noising Process라고 부르는데, 이는 $T$번의 각 Step이 모두 동일하기 때문이다. 즉, $x_0$에서 $x_1$로 가는 과정이나 $x_{T-1}$에서 $x_T$로 가는 과정이나 동일한 과정을 사용할 수 있다.
그런데 사실 Gaussian Noise를 추가하는 작업은 모델의 도움 없이 그냥 수학적으로 계산이 가능하다.

위와 같이 Gaussian distribution을 그대로 더해주면 된다. 여기서 더해주는 Gaussian distribution의 평균과 분산은 세부적인 알고리즘별로 택하는 방식이 다른데, 가장 초창기의 Diffusion Model인 DDPM(Denoising Diffusion Probabilistic Model)의 경우 다음과 같이 Hyperparameter $\beta_t$를 통해 결정한다.
\[\mathcal{N}(x_t;\sqrt{1-\beta_t}x_{t-1},\beta_t I)\]위의 과정을 총 $T$번 반복하므로 이를 종합하면 다음과 같다.
\[q(x_{1:T}\vert x_0)=\prod_{t=1}^{T}q(x_t\vert x_{t-1})\]그런데 각각의 Step은 Gaussian distribution이므로 결국 Gaussian distribution을 곱한 형태가 된다.
이를 간단하게 하기 위해 다음과 같이 간단한 케이스를 살펴보자.
\[x_1=\sqrt{1-\beta_1}x_0+\sqrt{\beta_1}\epsilon_1, \epsilon_1\sim\mathcal{N}(0,1^2)\] \[\begin{aligned} x_2&=\sqrt{1-\beta_2}x_1+\sqrt{\beta_2}\epsilon_2,\epsilon_2\sim\mathcal{N}(0,1^2) \\ &=\sqrt{1-\beta_2}(\sqrt{1-\beta_1}x_0+\sqrt{\beta_1}\epsilon_1)+\sqrt{\beta_2}\epsilon_2 \\ &=\sqrt{(1-\beta_2)(1-\beta_1)}x_0+\sqrt{(1-\beta_2)\beta_1}\epsilon_1+\sqrt{\beta_2}\epsilon_2 \\ &=\sqrt{(1-\beta_2)(1-\beta_1)}x_0+\left(\sqrt{1-(1-\beta_2)(1-\beta_1)}\right)\epsilon \end{aligned}\] \[\therefore x_2\vert x_0\sim\mathcal{N}\left(\sqrt{(1-\beta_2)(1-\beta_1)}x_0,1-(1-\beta_2)(1-\beta_1)\right)=\mathcal{N}\left(\sqrt{\bar{\alpha}_2}x_0,(1-\bar{\alpha}_2)\right)\] \[\bar{\alpha}_2=(1-\beta_1)(1-\beta_2)\]따라서 위의 관찰을 원래의 DDPM에 적용하면 다음과 같다.
\[q(x_t\vert x_0)=\mathcal{N}(x_t;\sqrt{\bar{\alpha}_t}x_0,(1-\bar{\alpha}_t)I),\bar{\alpha}_t=\prod_{s=1}^{t}(1-\beta_s)\]이를 통해 시작은 Iterative한 Step이었지만 임의의 Step으로 바로 계산할 수 있다. 그리고 이 각각의 Step은 전부 하나의 Gaussian distribution으로 표현이 가능하다. 이것을 Noising Process라고 부른다.
Iterative Denoising Process
다음으로 필요한 것이 Noise를 제거하는 과정이다. 이 과정은 위와 비슷하게 Iterative Denoising Process라고 부르는데, 이 역시 $T$번의 각 Step이 모두 동일한 과정이기 때문이다. 그러나 Noising Process와는 다르게 이 과정은 수학적으로 깔끔하게 계산할 수는 없는데, $q(x_{t-1}\vert x_t)$를 계산하려면 $p_{data}$에 의존해야 해서 closed form을 구할 수 없기 때문이다.

그렇기 때문에 여기서 Neural Network가 필요하다. $p_{\theta}(x_{t-1}\vert x_t)=\mathcal{N}(x_{t-1};\mu_{\theta}(x_t,t),\sigma_t^2I)$라고 하면, 역시 $T$번의 Step을 거쳐야 하므로 이들의 Joint distribution $p_{\theta}(x_{0:T})=p(x_T)\prod\limits_{t=1}^{T}p_{\theta}(x_{t-1}\vert x_t)$가 된다.
Training
이상의 과정을 통해 알아본 DDPM의 Encoder와 Decoder는 다음과 같다.

근데 이 과정은 앞에서도 언급했듯이 VAE가 하던 일을 여러 단계로 쪼갠 것과 개념적으로 유사하다. 즉, 일종의 Hierarchical VAE라고 볼 수 있는데, 따라서 여기서도 VAE와 유사하게 ELBO Loss를 사용한다.
먼저 VAE에서 어떻게 했는지를 간단하게 되짚어보자. VAE에서는 $z\sim\mathcal{N}(0,I)$이고, $p(x\vert z)=\mathcal{N}(\mu_{\theta}(z),\Sigma_{\theta}(z))$로 계산했다. 여기서 $\mu_{\theta}$와 $\Sigma_{\theta}$는 각각 Neural Network이다.
여기서의 ELBO는 다음과 같이 계산된다.
\[\mathbb{E}_{q_{\phi}(z\vert x)}\left[\log p(z,x;\theta)-\log q_{\phi}(z\vert x)\right]\] \[\log p_{\theta}(x) \geq \mathbb{E}_{q_{\phi}(z\vert x)}\left[\log p_{\theta}(x\vert z)\right]-KL(q_{\phi}(z\vert x)\Vert p(z))\]그렇다면 DDPM을 모방해서, $z_2\rightarrow z_1\rightarrow x$와 같은 Hierarchical VAE라면 어떨까? 이 경우 $z_2\sim\mathcal{N}(0,I)$, $z_1\sim p(z_1\vert z_2)$, $x\sim p(x\vert z_1)$이 되며, Encoder는 $q(z_1,z_2\vert x)$가 된다. 이 상황에서의 ELBO는 다음과 같다.
\[\mathbb{E}_{q_{\phi}(z_1,z_2\vert x)}\left[\log\dfrac{p(x,z_1,z_2;\theta)}{q(z_1,z_2\vert x)}\right]\]이제 이러한 고찰을 DDPM에 적용해서, ELBO Loss로 표현해보자.
\[\mathbb{E}_{q(x_0)}\left[-\log p_{\theta}(x_0)\right] \leq \mathbb{E}_{q(x_0)q(x_{1:T}\vert x_0)}\left[-\log\dfrac{p_{\theta}(x_{0:T})}{q(x_{1:T}\vert x_0)}\right]\]여기서 우측 항의 값을 $L$이라고 정의하면, $L$은 다음과 같이 다시 쓸 수 있다.
\[L=\mathbb{E}_{q(x_0)q(x_{1:T}\vert x_0)}\left[KL(q(x_T\vert x_0)\Vert p(x_T))+\sum_{t>1}KL(q(x_{t-1}\vert x_t,x_0)\Vert p_{\theta}(x_{t-1}\vert x_t))-\log p_{\theta}(x_0\vert x_1)\right]\]여기서 $q(x_{t-1}\vert x_t,x_0)=\mathcal{N}(x_{t-1};\tilde{\mu}_t(x_t,x_0),\tilde{\beta}_t I)$이고, $\tilde{\mu}_t$와 $\tilde{\beta}_t$는 다음과 같다.
\[\tilde{\mu}_t(x_t,x_0)=\dfrac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}x_0+\dfrac{\sqrt{\bar{\alpha}_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_t, \tilde{\beta}_t=\dfrac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\beta_t\]이 ELBO Loss에서, $q$는 Gaussian distribution의 곱으로 표현된, 고정된 분포이고, $p_{\theta}$가 우리의 학습 대상인데, DDPM의 Decoder 또한 Gaussian distribution으로 parameterized된다. 따라서,
\[p_{\theta}(x_{t-1}\vert x_t)=\mathcal{N}(x_{t-1};\mu_{\theta}(x_t,t),\sigma_t^2 I)\] \[L_{t-1}=\mathbb{E}_q\left[\dfrac{1}{2\sigma_t^2}\lVert\tilde{\mu}_t(x_t,x_0)-\mu_{\theta}(x_t,t)\rVert^2\right]+C\]이렇게 쓸 수 있다.
마지막으로, $\mu_{\theta}$ 또한 $\tilde{\mu}_t$를 추론하는 모델이기 때문에, 다음과 같이 parameterization을 할 수 있다.
\[\mu_{\theta}(x_t,t)=\dfrac{1}{\sqrt{1-\beta_t}}\left(x_t-\dfrac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon_{\theta}(x_t,t)\right)\]여기까지 반영한 최종적인 ELBO Loss는 다음과 같다.
\[L_{t-1}=\mathbb{E}_{x_0\sim q(x_0),t\sim U[1,t],\epsilon\sim\mathcal{N}(0,I)}\left[\lambda_t\lVert\epsilon_{\theta}\left(\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}\epsilon,t\right)\rVert^2\right]+C\]Algorithms & Structure
이상의 내용을 바탕으로 한 DDPM의 Training 및 Sampling 알고리즘은 다음과 같다.

또한 DDPM은 Noise가 추가/제거되기만 하고 Dimension이 변화되지 않기 때문에 아래와 같이 U-Net 구조를 쓰기 좋다.
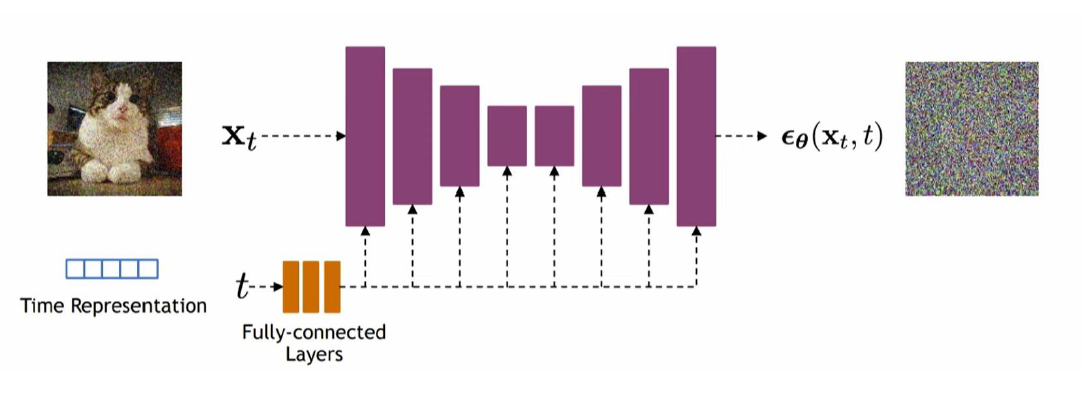
결국 이러한 알고리즘 및 구조를 통해 어떤 Step에서든 입력이 들어오고 그 Step 정보를 주면 얼만큼 Noise가 추가되었는지를 맞추는 모델을 훈련시킬 수 있다. 그리고 거기서부터 시작해서 그 추가된 Noise만큼 지워주고 다음 Step으로 넘어가는 작업을 반복하여 깨끗한 이미지를 생성하게 된다.