Advanced Machine Learning 2 - Supervised Learning & Empirical Risk Minimization
Before starting
“Class” 카테고리에 있는 포스팅들은 실제로 수업에서 배운 내용을 정리하려는 목적으로 작성되었다. 이 글은 그 중 Advanced Machine Learning 과목의 수업을 다룬다.
Learning
머신러닝은 경험에 의해 발전하는 알고리즘, 즉 학습을 하는 알고리즘이라는 것은 저번 글에서 충분히 다뤘다. 이번 글에서는 그 학습이란게 무엇을 의미하는지에 대해 알아볼 것이다. 크게 3가지 방식으로 나눌 수 있는데, 이들은 다음과 같다.
지도학습(Supervised learning)은 정답이 있는 데이터를 가지고 학습을 진행하는 방식이다. (여기서의 정답을 “label”이라고 부른다.) 학습에 사용되는 데이터는 정답이 있기 때문에, 모델이 예측했을때 이것이 label로부터 얼마나 다른지, 얼마나 정확한지를 알려줄 수 있다. 이 경우 우리가 모델에게 원하는건 궁극적으로 정답이 없는 데이터를 줬을 때에도 잘 예측하는 것이다.
비지도학습(Unsupervised learning)은 위와는 반대로 정답이 없는 데이터에서 학습을 진행한다. 예전에는 데이터의 특성을 찾아 분석하거나 패턴을 발견하는 용도로 쓰였으나 요즘은 샘플로부터 아예 새로운 샘플을 만들어내는, 즉 생성형 모델에서 많이 이용되는 방식이다. 이러한 특성 때문에 데이터에서 label을 스스로 만들어 지도학습처럼 학습하는 것도 가능하며, 이러한 방식을 자기지도학습(Self-supervised learning)이라고 부른다.
강화학습(Reinforcement learning)은 위와는 다른 방식을 사용하는데, 게임과 같이 특정한 보상과 그 보상에 만들어내는 행동을 이용해서 학습하는 방법이다.
하지만 지도학습이 “학습”의 본질에 가장 충실한 방식이기 때문에 이 글을 포함한 이 시리즈에선 대부분 지도학습에 대해서만 다룰 것이다.
Supervised Learning Setup
그럼 이제 지도학습을 수학적으로 정의해보자. 정답이 있는 데이터를 가지고 학습을 진행한다는 것은, 이 데이터는 input과 output이 별개로 존재한다는 이야기다. 따라서 학습 데이터를 다음과 같이 정의할 수 있다.
\[\mathbb{D} = {(x_1,y_1), \ldots, (x_n,y_n)}\]- $x_i \in \mathbb{R}^d$: input vector
- $\mathbb{R}^d$: $d$차원의 feature space
- $y_i \in {\Large y}$: output
- $\Large y$: Label space
당연하지만, $(x_i, y_i)$는 (입력, 출력)의 튜플이기 때문에 순서가 바뀌면 안된다. 데이터의 상태, 그리고 원하는 문제가 뭐냐에 따라 input의 차원 $d$와 label space인 $\Large y$는 크게 달라진다.
예를 들어, 환자의 데이터가 input이라면 나이, 키, 몸무게, 성별, 가족력 등등의 정보들이 각각 수치화되어 $x_i$라는 벡터 하나에 들어갈 것이다. 이미지를 입력받고 싶다면 그 이미지에 속하는 모든 픽셀들의 RGB값 각각이 전부 하나의 차원이 되는 거대한 벡터가 될 것이다. 예를 들어 64 * 64 크기의 이미지를 입력하고 싶다면 $x_i \in {0, \ldots, 255}^{(64 \ast 64 \ast 3)}$이 될 것이다.
$y$쪽도 마찬가지로, ${\Large y} = \mathbb{R}$이라면 이건 Regression 문제가 될 것이고, ${\Large y} = \lbrace 1, \ldots, c \rbrace$라면 Classification 문제가 될 것이다.
이렇게 데이터셋이 다 정의된 것처럼 보이지만, 아주 중요한 가정이 하나 더 필요하다.
\[(x_i,y_i) \overset{iid}{\sim} P_{XY}\]여기서 “iid”라는 것은 “Independent & Identically Distributed”의 약자이다. 즉, 모든 $(x_i,y_i)$는 어떤 한 분포 $P_{XY}$에서부터 독립된 시행을 통해서 얻어낸 데이터라는 의미이다. 이 가정이 성립되지 않으면 뒤에서 논의할 많은 내용이 의미가 없어지게 된다.
또 당연하지만 우리는 여기서 가정하는 분포 $P_{XY}$가 어떤 형태인지 모른다. 이걸 알게 되면 우리는 이미 정답지를 손에 들고 있으니 이 모든 과정을 할 이유가 없어지기 때문이다. 이건 더 이상 머신러닝의 영역이 아니라 철저한 통계학의 영역이 된다. 그러니 앞으로의 논의에서도 데이터의 출처가 되는 저 분포 $P_{XY}$는 모른다는 전제 하에 진행될 것이다.
여담으로, 위의 가정은 매우 중요하지만 아이러니하게도 현실에선 만족하기 어려운 경우가 비일비재하다. 동일한 분포로부터 왔다는 가정이 문제가 아니라, 모든 데이터가 독립된 시행을 통해서 얻어낸 것이라는걸 보장하기 어렵다. 극단적으로 보면 시간의 흐름에 따라서도 데이터의 상태가 달라질 수가 있기 때문인데, 이 때문에 현실 데이터를 모델링하여 분포가 조금씩 바뀌는 케이스까지 가정을 해서 모델에 적용하는 Domain Adaptation 등의 연구도 있다고 한다.
하지만 일단 이 시리즈에서는 이러한 케이스는 생각하지 않고 위의 가정대로 모든 데이터가 동일한 한 분포 $P_{XY}$에서 공평하게 잘 추출된 데이터라는 전제 하에 논의를 이어나갈 것이다.
그럼 여기까지 해서 데이터셋이 준비가 되었다. 이제 이 데이터셋을 가지고 Supervised Learning에서 해야하는 목표도 정의해보자. 위에셔 지도학습은 label을 통해서 배운 후, 이를 한 번도 보지 못한 데이터 샘플에도 적용하여 예측을 할 수 있도록 하는 방식이라고 했었다.
즉, 모델 $h$는 위의 데이터셋과 동일한 구조의 데이터 튜플 $(x,y) \sim P_{XY}$에 대해서 높은 확률로 $h(x) = y$를 만족하는 함수(즉, $h(x) \approx y$를 만족하는 함수)가 된다. 그리고 지도학습은 이를 만족하는 함수 $h$를 찾는 과정이다.
이를 좀 더 잘 찾기 위해서는 $h$의 형태를 정해놓고 그 안에서 찾는 것이 훨씬 편할 것이다. 이를 수학적으로 표현하면 $h \in \mathbb{H}$가 되고, 여기서 $\mathbb{H}$를 Hypothesis class라고 부른다. 이는 큰 단위의 모델 구분, 즉 머신러닝 알고리즘에 해당한다.
만일 $\mathbb{H}$가 linear regression이라고 가정하면 이 모델은 어떤 식으로 학습을 하든 $h(x) = wx + b$의 형태라고 가정하고, 주어진 데이터셋의 label을 최대한 만족할 수 있는 $w$와 $b$를 찾는 방향으로만 학습할 것이다. 물론 다른 알고리즘을 택할 경우 다른 형태의 $h(x)$가 나올 것이고, 그 형태에서 존재하는 다양한 계수들을 찾는 식으로 학습할 것이다.
위의 예시처럼 Linear Regression이라면 찾아야 하는 파라미터의 개수가 겨우 2개뿐이지만, 현대의 딥러닝 알고리즘은 Billion, 즉 10억이 기본 단위일 정도로 파라미터의 개수가 상당히 많다.
이 파라미터까지 반영한 hypothesis function $h$는 다음과 같이 표기한다.
\[h(\cdot; \theta): \mathbb{R}^d \rightarrow {\Large y}, \text{ or } h_{\theta}: \mathbb{R}^d \rightarrow {\Large y}\]즉, 주어진 데이터셋 $\mathbb{D}$에 대해, 이 문제를 해결할 수 있을법한 Hypothesis class를 잘 고른 후, 이로 인해 정해지는 함수 $h$의 파라미터들을 잘 정하는 과정이 머신러닝의 본질이라고 할 수 있다.
그러면 매우 복잡하고 정교한, 만능의 Hypothesis function도 존재하지 않을까? 이런 함수가 존재한다면, 여기의 파라미터들을 잘 조정만 하면 모든 것을 해결해줄 수 있는 궁극의 모델도 얻을 수 있지 않을까? 안타깝게도 그런 함수는 존재하지 않음이 증명되었다. 이를 “No Free Lunch Theorem”이라고 한다.
위에서 hypothesis class를 고르는 과정도 어떻게 보면 이 데이터셋에 적합한 함수가 이런 형태일 것이다라는 가정이 포함되어 있다. 즉, 이미 $h$의 형태를 결정하는 과정에서 이 데이터셋에 특화된 가정이 포함되어 있는 상태이다. 이런 식으로 학습된 모델은 이 가정이 깨져있는 데이터셋에는 적합하지 않을 수 밖에 없다. 그렇기 때문에 모든 데이터셋을 만족할 수 있는 모델은 존재할 수 없다는 논리이다.
결국 우리는 어떤 모델이 적합한지를 찾으려면 노가다를 하는 수 밖에 없다. 경험에 의해서 추측해볼 수는 있지만, 결국 만악의 근원인 “이 데이터셋이 어느 분포에서부터 왔는지 모른다”는 점 때문에 해보지 않고 정답을 알 수 있는 방법은 존재하지 않는다. 대신에 각각의 hypothesis class들을 다양하게 알면 많은 데이터셋을 커버할 수 있을 것이고, 잘 알면 파라미터 $\theta$가 어떤 의미를 갖고 어떻게 변경해야 하는지를 보다 쉽게 알 수 있을 것이다. 그리고 실제로 대부분의 머신러닝 및 딥러닝 수업은 이걸 가르치는 것이기도 하다.
Loss Function
그렇다면 모델이 예측을 “잘” 했다는 것을 어떻게 정의할 수 있을까? 지도학습은 정답, 즉 label이 있기 때문에 label과 얼마나 유사한지를 파악하면 된다. 그렇다면 “얼마나” 유사한지는 또 어떻게 정의할 수 있을까? 이걸 손실 함수(Loss function)으로 정의한다. 손실 함수는 label과 모델이 예측한 값을 인자로 받아야 하기 때문에 $l: {\Large y} \times\mathbb{R} \rightarrow \mathbb{R}$의 형태를 가지게 된다.
즉 hypothesis function $h$에 대해 손실함수의 값이 최소가 되는 $\theta$를 찾으면 된다. 그렇게 찾은 $\theta$는 학습이 완료된 상태라는 의미로 $\theta^{\ast}$로 표기하며, 아래 식을 만족하게 된다.
\[\theta^{\ast} = \text{arg } \underset{\theta}{\inf} (l(y,h(x)))\]$\inf$는 하한선의 의미로, 손실함수의 공역은 실수 집합 $\mathbb{R}$이라 손실함수의 형태에 따라선 명확한 최솟값이 존재하지 않을 수도 있기 때문에 대신 하한선으로 표기한다. 또한 여기서 $\text{arg}$는 Argument를 뜻하는 것으로, 말 그대로 $\theta^{\ast}$는 $h$의 파라미터이기 때문에 이렇게 표기한다.
이제 간단한 손실 함수의 형태들을 몇 개 보고 넘어가자.
가장 먼저 간단하게 Zero-One Loss가 있다. 이는 다음의 형태를 가진다.
\[l(y,h(x)) = \delta_{h(x) \neq y}\]즉 단순하게 맞으면 0, 틀리면 1을 리턴한다. 주로 classification 문제에서 쓰이지만 이 함수는 연속적이지도 않고 미분도 불가능해서 사용하기 좀 불편하다. 그 때문에 요새는 Cross Entropy라고 하는 손실함수를 사용한다고 한다.
다음으로는 Squared Loss, 그리고 Absolute Loss가 있다.
- Squared Loss: $l(y,h(x)) = (h(x)-y)^2$
- Absoulte Loss: $l(y,h(x)) = \mid h(x)-y \mid$
둘 다 주로 regression 문제에서 쓰인다. Squared Loss는 차이를 제곱하기 때문에 Absolute Loss에 비해 틀리는게 치명적으로 작용하는 문제에서 쓰기 좋다. 물론 그만큼 outlier가 존재하면 손실함수의 값이 산으로 가기 때문에 이상하게 학습이 되는 문제도 존재한다.
이와 같이 손실함수의 디자인도 모델을 학습하는 데에 중요한 지분을 차지한다.
여담으로, 손실함수의 공역이 $\mathbb{R}^+$가 아니라 $\mathbb{R}$로 되어있는데, 실제로 음수가 될 수 있다! 위의 예시들은 전부 최솟값이 0이고 실제로도 상당수의 손실함수가 그런 식으로 설계되지만, 일부 음수가 나올 수 있는 케이스도 존재한다. 일단은 그럴 수 있다 정도만 알아두고 넘어가자.
Empirical Risk Minimization
여기까지 오면 머신러닝의 본질에 대해 다 이해한 것 같지만, 아직 한 가지 중요한 문제가 남아있다. 우리는 모델이 학습 데이터 뿐만이 아니라, 새로운 데이터에 대해서도 예측을 잘 하기를 원한다. 근데 당연하게도 이 새로운 데이터는 label이 없다. 그러면 어떻게 손실함수를 계산해서 추론을 잘 했는지를 파악할 수 있을까?
생각해볼 수 있는 아이디어는, 우리가 label을 알건 모르건 어쨌든 같은 분포로부터 왔다는 사실을 이용하는 것이다. 모든 확률분포에는 기댓값이 존재한다. 그러면 손실함수의 기댓값을 계산해서, 궁극적으로 이 기댓값을 낮추는 방향으로 가게 되면 우리가 label을 모르는 데이터도 잘 추론했는지 알 수 있을 것이다.
\[R(h) = \mathbb{E}_{X,Y \sim P_{XY}}[l(y,h(x))]\]즉, 위와 같은 형태의 True Risk $R$를 구하면 될 것이고, 학습이 완료된 hypothesis function $h^{\ast}$는 이 Risk를 최소화시키는 방향으로 학습이 되었으므로 다음과 같이 표기할 수 있을 것이다.
\[h^{\ast} = \underset{h:{\Large x} \rightarrow {\Large y}}{\text{arg } {\inf}}R(h)\]그런데 안타깝게도 True Risk $R(h)$는 구할 수 없는 값이다. 우선 $h:{\Large x} \rightarrow {\Large y}$를 만족하는 $h$는 무수히 많다. 우리는 이 모든 함수를 테스트할 수가 없어서 함수의 class를 미리 정해놓고 학습하기로 했는데, 실제로 계산하려면 모든 가능한 경우에 대해서 다 계산해야만 한다.
그렇다고 이 조건을 $h \in \mathbb{H}$로 바꿔도 여전히 구할 수 없는데, 분포 $P_{XY}$를 모르기 때문이다. 분포를 모르니 당연히 기댓값도 구할 방법이 없다. 그렇다고 분포를 아는 문제가 주어지면 통계학으로만 모든 문제를 해결할 수 있어 머신러닝이 필요없어진다.
이 모순을 해결하기 위해, Empirical Risk라는 개념을 정의하게 된다. 우리가 알고 있는 것은 $n$개의 input-output의 튜플뿐이므로, 이들의 평균을 내서 True Risk의 값을 어림짐작 해보는 것이다.
\[\mathbb{L}(h;\mathbb{D}) = \dfrac{1}{n} \sum^{n}_{i=1} l(y_i,h(x_i))\]이런 식으로 계산할 수 밖에 없어서 위의 “iid” 가정이 중요하다. 모든 데이터셋이 한 분포로부터 “균등하고” “독립적으로” 왔다는 가정이 있어야만 Empirical Risk가 True Risk의 unbiased estimate가 될 수 있어 모델의 정확도를 끌어올릴 수 있다. 또한 아무리 iid 가정이 지켜졌다 하더라도 데이터셋 $\mathbb{D}$가 분포 $P_{XY}$를 대변하기 위해선 큰수의 법칙이 성립될 정도로 많은 수의 데이터가 필요하다.
다시 여기까지의 내용을 수식으로 압축해보면, 머신러닝은 다음과 같은 함수 $\hat{h^{\ast}}$를 구하는 과정이다.
\[\hat{h^{\ast}} = \underset{h \in \mathbb{H}}{\text{arg } {\inf}}L(h;\mathbb{D})\]이를 구하기 위해 어떤 머신러닝 알고리즘을 쓸지($\mathbb{H}$)를 잘 고르고, 예측의 정확도를 판별하기 위해 Empirical Risk $L(h;\mathbb{D})$를 구해서 이것이 최소화되는 $h$의 파라미터 집합 $\theta$를 구하면 된다. 물론 위의 최적화 과정들은 풀고자 하는 문제마다, 그리고 주어진 데이터셋마다 다 다를 것이지만 결국 다 같은 과정을 거치게 된다는 이야기이다.
Generalization
그런데 아직도 해결해야 할 문제가 남아있다. 위의 과정을 모두 거쳐서 Empirical Risk가 최소가 되는 $h$를 구했다고 해도 이것이 실제로 추론을 잘 하지 못할 수도 있다. 우리는 궁극적으로 모든 데이터에 대해 모델이 정답을 잘 맞추기를 기대한다. 그러나 그 정답을 판별하기 위한 값은 결국 데이터셋으로부터 나온 값이지, 모든 데이터에 대한 값이 아니다. 제 아무리 Empirical Risk를 잘 줄여도 이건 이 데이터셋에 대해서만 잘 맞는다는 증거가 될 뿐이다. 이런 경우를 과적합(Overfitting)이라고 한다.
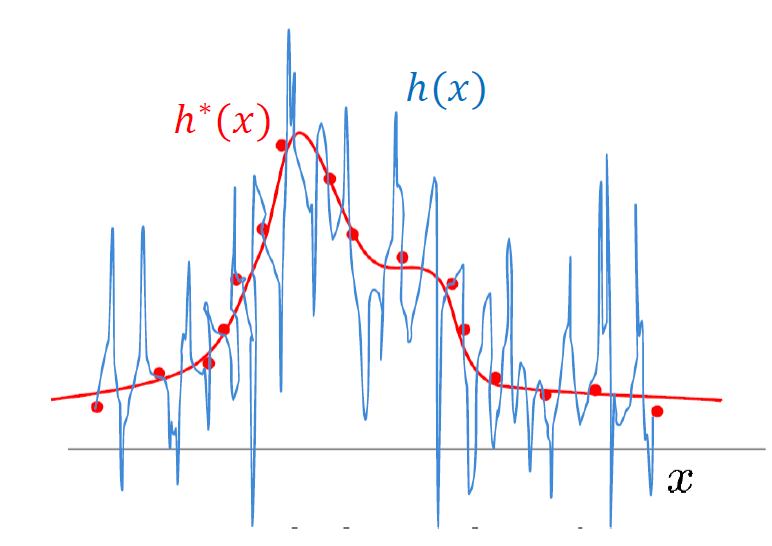
위의 함수에서, 정말 공교롭게도 점이 찍힌 부분들만 데이터셋으로 삼아 학습을 진행했다면, $h$의 Empirical Risk는 0에 수렴할 것이다. 그러나 새로운 데이터를 가지고 추론을 하게 되면 Ground Truth인 $h^{\ast}$와 크게 차이가 나게 될 것이다.
이러한 과적합을 방지하려면 결국 $\mathbb{L}(h;\mathbb{D}) - R(h)$가 줄어야 한다. 이 값을 Generalization Error라고 부른다. 그런데 True Risk를 직접 계산할 수 없다는 문제가 또 발목을 잡는다. 그렇기 때문에 여러 단계에 걸쳐서 Generalization Eror를 분해해야 한다.
우선 $R^{\ast} = \underset{h: {\Large x} \rightarrow {\Large y}}{\inf}R(h)$, 그리고 $R_{\mathbb{H}}^{\ast} = \underset{h \in \mathbb{H}}{\inf}R(h)$라고 하자. 즉 $R^{\ast}$는 모든 $\mathbb{H}$에 대한 True Risk고, $R_{\mathbb{H}}^{\ast}$는 Hypothesis class를 고정해서 True Risk를 계산한 값이다. 당연하지만 두 값 모두 실제로 계산할 수 없는 값이다. 그리고 우리가 실제로 계산할 수 있는 Empirical Risk를 계산한 값은 $R(\hat{h_\mathbb{H}^{\ast}}) = \underset{h \in \mathbb{H}}{\inf}L(h;\mathbb{D})$라고 표기하자.
그러면 $R(\hat{h_\mathbb{H}^{\ast}}) - R_\mathbb{H}^{\ast}$는 동일하게 Hypothesis Class를 고정했을 때 True Risk와 Empirical Risk의 차이를 뜻하게 된다. 이 값을 Estimation Error, 혹은 Sample Error라고 하며, 이 값이 크다는 얘기는 데이터가 충분히 확보되지 않아 데이터셋 $\mathbb{D}$가 표본 $P_{XY}$를 대표할 정도가 되지 못했다는 이야기다. 즉 Estimation Error를 줄이기 위해서는 데이터를 많이 확보하면 된다.
그리고 $R_\mathbb{H}^{\ast} - R^{\ast}$는 모든 경우의 True Risk와 특정한 Hypothesis Class를 선택했을 때의 True Risk의 차이를 뜻하게 된다. 이 값을 Approximation Error라고 하며, 이 값이 크다는 얘기는 주어진 문제를 잘 해결할 함수를 잘못 골랐다는 뜻이 된다. 물론 우리가 어떤 알고리즘이 정답일지 알 수는 없지만, $h$가 복잡할수록, 그리고 파라미터가 많을수록 좀 더 세밀하고 복잡한 케이스를 커버할 수 있어서 실제 정답에 더 근접할 것이다. 그 때문에 Approximation Error를 줄이기 위해서는 모델을 더 복잡하게 만들면 된다.
여기까지 놓고 Generalizatin Error를 다시 보면, Generalization Error = Estimation Error + Approximation Error가 된다. 즉 모델이 복잡하고 샘플이 많을수록 Generalization Error를 줄여 overfitting 문제를 해결할 수 있다…고 정리하면 좋지만, Occam’s Razor라는 원리가 있다.
샘플수가 같다면 더 간단한 모델이 추론을 더 잘 한다는 내용인데, 사실 직관적으로 생각해봐도 복잡한 모델일수록 파라미터의 개수가 많고, 이는 곧 경우의 수의 상승으로 이어진다. 그 때문에 데이터의 개수가 동일하다면 정해야 하는 파라미터의 개수가 적을수록 보다 잘 최적화시킬 가능성이 높으리라는 사실을 짐작할 수 있다.
다시 Generalization Error 문제로 돌아가면, $\mathbb{H}$의 복잡도는 Trade-off이다. 그래도 데이터가 많은 것은 항상 옳으니 먼저 데이터가 충분한지부터 검토하는게 우선이 된다. 그 후 모델의 복잡도를 올리는 것은 신중하게 검토해야 한다.
실제로 데이터의 개수가 고정되어 있다는 가정 하에, $\mathbb{H}$의 복잡도와 Generalization Error의 상관관계는 다음과 같은 형태를 띄게 된다.
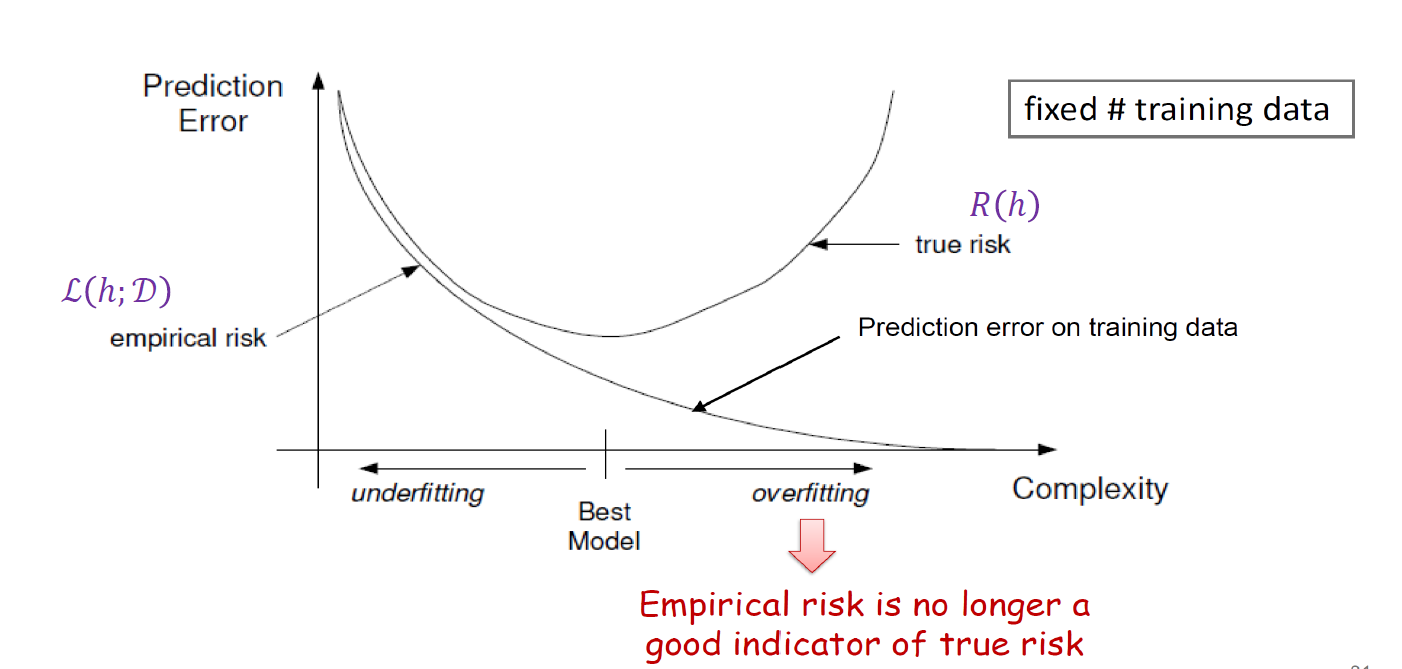
여담으로, 딥러닝 시대로 넘어가면서 $\mathbb{H}$가 훨씬 더 복잡해졌는데, 위의 그래프에서 Complexity가 더 커진다면 오히려 Generalization Error 값이 줄어든다는 연구 결과가 있다. 이를 Double Descent 현상이라고 부르는데, LLM에서 전혀 기대하지 않았던, 최초에 주어진 Task와 관계없는 것들을 맞춘다거나, 생각지도 못했던 예측을 하거나 하는 현상들이 이 때문에 생긴 것이 아닐까 하는 추측이 있다고 한다.
물론 그렇다고 해도 위의 큰 원칙은 동일하게 적용되기 때문에 딥러닝 모델들도 나름의 방식으로 복잡도를 줄이기 위해 다양한 방법을 사용한다고 한다. 모델의 복잡도는 곧 파라미터의 수와 동일하기 때문에, CNN, RNN, transformer 등 잘 알려진 모델들도 전부 동일한 구조나 필터를 여러 번 재사용하여 파라미터를 줄이려는 노력을 한다.